
 雷锋网
(大众号:雷锋网)
:
喜欢机器学习和人工智能,却发现埋头苦练单调有趣还杀工夫?油管频道 Arxiv Insights 每周精选,从技术视角动身,带你轻松深度学习。
雷锋网
(大众号:雷锋网)
:
喜欢机器学习和人工智能,却发现埋头苦练单调有趣还杀工夫?油管频道 Arxiv Insights 每周精选,从技术视角动身,带你轻松深度学习。
翻译/ 曹晨
校正/ 凡江
整理/ 廖颖
雷锋网本期Arxiv Insights围绕一篇名为 《研讨电子游戏中人类的先验信息》 (Investigating Human Priors For Playing Video Games)展开。论文提出的中心成绩是:为什么人类擅长通关电子游戏?作者发现其中一个关键点是,人类可以应用弱小的先验才能疾速决策、疾速通关。
视频解读
人类1分钟通关的游戏,机器要花37小时
以“营救公主”的益智游戏为例,游戏通关方式是,需求营救者爬上梯子抵达最顶端,越过朋友救出公主,对普通玩家来说,整个操作进程只需求1分钟工夫。但假如用现阶段最先进的加强学习算法停止游戏,就算是最无效的一类算法也大约需求4百万帧来训练。(要延续通关,这个数量的帧数是必需的)
如今我们以工夫为单位,来重新计算这些帧数。假定你运转的游戏是每秒30帧左右,那么400万帧就相当于一团体不连续地玩37个小时左右的游戏。这样算上去,机器破费的工夫大约是人类闯关所需工夫的2000倍。
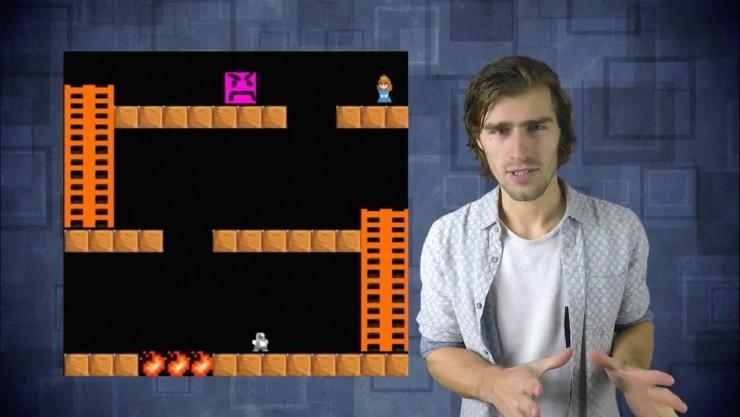
为什么人类擅优点理新的复杂环境?
很显然你会说,这是由于人类有很多已知的先验信息。比方,我们晓得梯子是需求爬的,所以我们避开梯子。但关键成绩不在信息数量,而在于信息的重要度和影响力: 不同的先验信息重要水平会有所不同吗?我们能否量化这些先验信息所带来的影响?
在最近几年中,机器学习获得了十分明显的提高,加强学习也获得了明显的提高。这些提高大局部来自于相似谷歌的 DeepMind OpenAI 以及在人工智能研讨前沿中声名鹊起的大学。
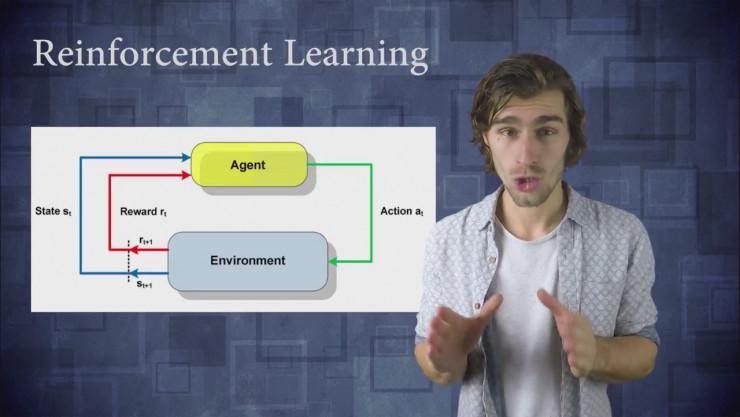
这些停顿标明我们可以训练agent,使它在静态环境中能学习到十分复杂的行为。agent运用了一种信号,我们称之为 奖励信号 。不同于监视学习,需求告知agent在给定状况下应该采取什么举动。这种agent可以在环境中依照其想要的方式自在举动。但是它有一个信号,即之前提到的奖励信号,奖励信号试图随着工夫的推移,不时优化agent,使其到达最优值。
这些算法在各式各样的场景中,表现十分出色。这样的成就甚至让很多人提出,我们能够看到了泛化人工智能晚期的萌芽。 虽然已获得一些可观的成就,要使机器到达与人类程度相近的学习才能,还有很长的路要走。
机器学习终究差在哪?
目前的算法擅善于 泛化学习(general learning) ,但它们存在 样本应用率(sample efficiency) 差的成绩。这个成绩意味着,在它们可以分清什么行为是以后环境所需求的之前,你必需给agent很多训练帧。还需求阐明,算法和人类表现的不同之处,大局部研讨者并没有提到 嵌入式知识(embedded knowledge) ,即人们带到新的义务中的知识。这些知识使得我们找寻特定成绩的最优解法能比我们目前拥有的任何算法都疾速。
假如你还理解些心思学,我们就晓得,重生婴儿实践上是有模拟倾向的。假如一个父亲伸出他的舌头,虽然孩子没无意识到发作了什么,但是我们常常会看见婴儿模拟这个举措。这个现实阐明有些信息是嵌入在我们基因中的。异样我们有激烈的倾向去留意人脸。因而,关于重生婴儿而言,假如给他很多很多图片,他们总是会首先盯着人脸看。

而还有一些人类的先验信息是没有存储到我们基因中的,但我们会在年老的时分去学习。其中一个案例就是 客体永世性 (object permanence)。客体永世性标明一个现实:假如你有一个给定的物体,忽然将该物体隐藏起来,我们还是以为物体在那儿。
客体永世性这个概念常常呈现在两个月左右大小的人类婴儿。但是在黑猩猩和其他猴类,这种景象呈现得更快更早。因而你可以看到,一只和人类婴儿相反年龄的猴子,关于猴子来说,客体永世性的概念曾经表现出来了。为了检测不同人类先验信息的呈现和影响,研讨者们设计了个游戏,他们成心用随机构造交换了游戏中的一些物体。这个想法其实是,假如处置得巧妙,你实践上可以掩盖某些方式的先验信息。然后再经过人类玩家的表现变化来分辨,哪些方式的先验知识实践上对完成游戏是关键的。
人类赢了,靠的是先验信息
在持续讨论之前,我希望你们一切人都来试玩一下这个 游戏 ,并且尝试其中一个调整过的游戏版本,去看看假如你没有了先验信息,玩下去是多么困难。没有重新映射任何构造的原始游戏,一个正常人需求大约1.4分钟来闯关。

研讨者对游戏的第一个调整是改动了对象的语义,他们将可以看见的一把钥匙或一扇门交换了,玩家只能复杂地看到一种一致颜色的正方形。这样做其实是拿走了我们关于对象属性的先验知识。我们很显然能觉察,在游戏的初始版本中,一切玩家需求先去拿钥匙,然后去开门。而在重新映射了却构的游戏中就不是这样了。这分明地展现了人们运用他们关于对象先验信息来引导他们的行为。
在 重新映射构造的游戏 中,均匀游戏工夫从1.4分钟上升至大约4.4分钟。在调整的第二个游戏版本中,研讨者决议复杂地在一个版本根底上,再隐藏物体的地位。于是,如今一切玩家能自在挪动的地位曾经被一致颜色的正方形掩藏起来了。在这个版本游戏中,人类玩家闯关所需的均匀间上升到9分钟。我们不晓得对象在哪儿,但我们仍十分清楚地形是什么样的,比方我们晓得平台在哪儿,也晓得晶格作用是什么。

在 新版本游戏 中,他们又重新映射了一切的这些构造,我们把这种行为叫做 去除功用可见性 (affordance removal)。这证明了去除功用可见性并不像移除对象语义那样蹩脚。最初研讨者决议试试游戏的骨灰级形式,于是他们将重力感应旋转了90度,交流了左和右的控制键。此外,他们还重新映射了一切的功用可见性构造。
这阐明我们找到了关键点,因而经过定量比拟这些调整的游戏版本给人们闯关工夫所带来的影响,研讨者们列出了一些人类已晓得的先验信息,以及这些先验信息关于处理一个义务来说的重要性。
从后果我们能看出端倪,比方复杂的判别物体关于处理复杂环境来说十分关键。接上去,研讨者们就做了十分风趣的事:他们运用了最先进的加强学习算法,该算法称为 A3C (Asynchronous Advantage Actor-Critic),经过这个算法来尝试经过异样处置的调整后游戏版本——这些版本都是之后人类玩家见过的。后果证明加强学习agent没有任何成绩,无论在调整的版本,哪怕是游戏版本中一切的物体构造都被重新映射了,加强学习agent需求大约相反数量的训练帧来处理这局部成绩。

总体来说,人类运用十分弱小的先验信息,使得他们能在之前从未遇见的情境中疾速发现最佳的处理方案。而这正是以后在加强学习算法中,所短少的最次要的东西,由于算法没有事后树立起关于这个世界如何任务的知识。
先验信息不万能,有时分还会成为绊脚石
最初需求留意的一点是,掌握对象的先验知识能够不总是一件坏事情。想想我之前讨论过的AlphaGo零碎,就可以很清楚地发现,该算法从零开端训练,就需求丢掉一些基于人类知识和人类游戏的先验信息,而这些先验信息的确能使算法失掉一个更好的功能。
还有另一个例子,假如你改动了游戏的重力,那么人们将会做出十分蹩脚的决策,并做出比没有事后输出物理知识定义的目的agent更蹩脚的事情。这些标明,虽然人类的先验信息能够对处理新环境中的新义务有用,但是这些先验信息也能够是起到阻碍作用。
这种状况我们在量子物理也会中见到 。人类的知识是我们经过很多年的迷信研讨和自然界生活积聚的。但是这些却被量子物理中奇异的规则所违犯了,这些对我们来说十分不契合自然规律,也十分难以承受和了解。
论文旧址:
https://openreview.net/pdf?id=Hk91SGWR-
论文中各个版本的游戏链接:
https://high-level-3.herokuapp.com/
https://openreview.net/pdf?id=Hk91SGWR-
雷锋网(雷锋字幕组)出品。添加微信:雷锋字幕组(leiphonefansub),参加我们。
相关文章:
神经网络往常都在做些啥?可视化特征解释了一下
。
