
雷锋网 AI 科技评论按:谷歌大脑近期的一篇新论文对对立性样本做了多方面的实际性研讨,不只初次发现了复杂数据散布下对立性样本的散布特性,而且得出了「分类误差为零的模型不存在对立性样本」这样的大家此前不曾想象过的结论。我们把这篇论文《Adversarial Spheres》(对立性球面)次要内容引见如下。

背景
自从 Ian Goodfellow 等人发现并命名了「对立性样本」以来,学术界曾经有许多研讨者投入了许多工夫精神在这种景象的研讨上。数字图像可以被巧妙地修正,修正的幅度对人眼来说简直无法发觉,但修正后的图像却可以以很高的相信度骗过图像辨认模型,让模型以为这是另一个类别的实体,这是「对立性样本」的直接来源。Ian Goodfellow 稍后也把这种景象正式描绘为「从数据散布中随机选择图像,大少数都可以被图像模型正确分类,但是看上去十分类似的图像却能够会被分类错误」。经过对立性办法创立的对立性样本具有优秀的鲁棒性(可以对多种不同模型起效),而且具有一定的视角、方向、大小不变性。虽然之前也有研讨者提出实际假说和一些进攻战略,大家对这种景象的缘由依然知之甚少。
关于对立性样本的缘由目前有这么几种假说:神经网络分类器在输出空间的许多区域都过于线性;对立性样本并没有落在正常的数据流形上;也有人提出网络外部权重矩阵的单个很大的值有能够会让网络对输出中的小扰动更软弱。
除了尝试解释对立性样本的成因,也有研讨者提出了各种进攻办法来进步模型的鲁棒性。有的研讨尝试交换网络运用的非线性函数以进步对小扰动的鲁棒性,有的研讨尝试把大模型蒸馏为小模型,有的研讨中给网络添加正则化,还有一些研讨中尝试用一个额定的统计模型先把对立性样本挑出来。不过,也有研讨阐明了以上这些办法都不一定见效,对立性训练在某些情况下倒是可以进步网络的鲁棒性。
从构建球面散布数据开端
思索到这些能被骗过的模型在测试集上其实也是有很高的精确率的,对立性样本的这种景象就有点耐人寻味。在这篇论文中,作者们提出一种假说,以为网络之所以会呈现这种行为,是数据流形的高维度实质特性的自然后果。
为了可以验证这种假说,作者们构建了两个同心的高维球面数据集,训练网络做这个二分类义务,以此展开研讨。两个球面辨别为 r=1 和 R=1.3,数据维度最高为 5000,并且数据点就散布在球面上(雷锋网 (大众号:雷锋网) AI 科技评论注:这也就是标题中的「spheres」的含义)。在这样的设定中,数据流形无数学上的完善定义,而且模型学到的决策边界也是可以有解析性的表示的;而以往的基于现有图像数据集的研讨中,数据流形是不可知的,决策边界也无法表示,就很难停止研讨。更重要的是,经过本人生成数据的进程,作者们可以自在地变化数据维度的数目大小,从而研讨输出维度数目对神经网络的泛化误差存在性的影响。
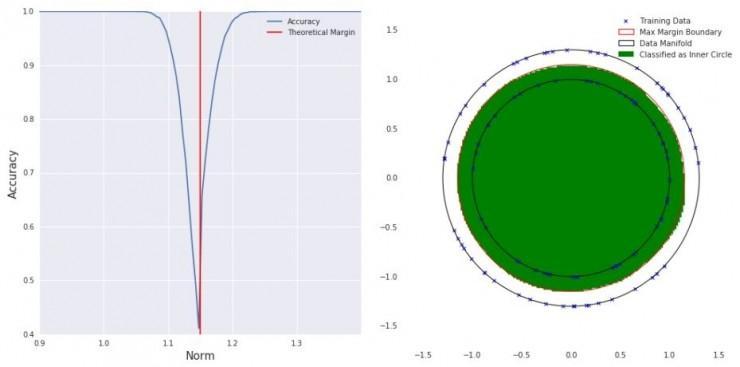
用球面散布数据集对二分类模型的测试后果和图像模型的测试后果类似:数据散布中随机选择的点少数都可以被正确分类,同时也和不能被正确分类的点十分接近。即使当测试错误率低于一千万分之一的时分都会呈现这种行为。
研讨结论
作者们经过研讨失掉了这样的结论:「测试集上呈现分类错误的点呈现的概率」和「到最近的分类错误点之间的间隔」,两者之间的关系是与模型有关的。任何一个总会分类错误球面上的一小局部点的模型,就一定会在少数随机采样的数据点左近存在会被分类错误的点,不论模型分类错误的点在球面上的散布如何。在球面数据集上训练的神经网络都会自然地迫近作者们找到的这个测试误差战争均间隔之间的实际最优均衡曲线。这似乎标明,为了按线性减小到最近的分类错误点之间的均匀间隔,模型的分类错误率需求以指数减小。
这个结论给出了模型的泛化误差和到最近的分类错误点间隔之间的最优取舍均衡关系。作者们也设计了三个不同的网络,在 1k、5k、10k、100k、有限制这几种训练样本数目下停止了验证性测试,失掉的后果正是沿着以上结论给出的曲线(黑线)的。
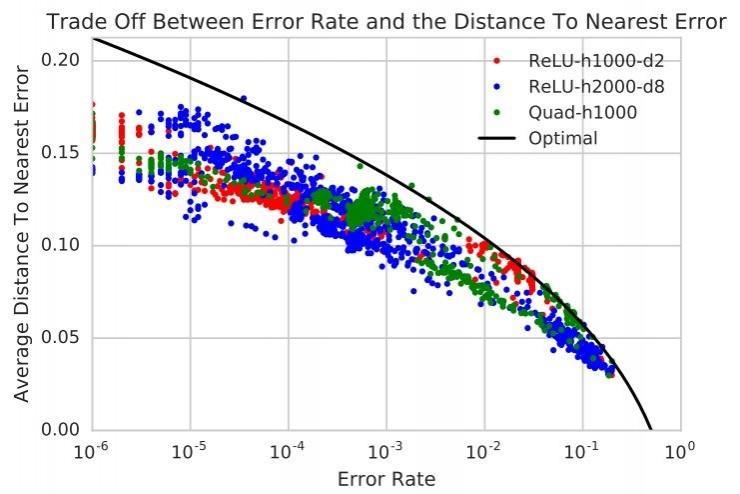
这个结论的重要意义表现在,它把「为什么模型很容易被对立性样本骗过」这个难以给出直接答案的成绩变成了「为什么有大批的分类错误」这个更复杂的成绩。目前还不晓得关于图像数据集的数据流形,这个结论能否还成立,后续研讨会向着这个方向持续探究。毕竟论文中研讨的只是一个极为复杂的球面散布数据集,还不能很好表现出真实图像数据集数据流形的复杂性。
这个结论引发的后续成绩还包括在数据量无限的状况下有没有能够完全处理对立性样本的成绩。作者们的实验中,用足够少数据训练的足够大的网络曾经展示出了低到测不出来的分类错误率,不过实验同时也标明这个网络的规模要明显大很多才可以。作者们猜想也许一个足够大的神经网络、经过十分大的图像数据集训练之后有能够最终变得完满,在测试中获得低到测不出来的分类错误率,同时也就能很好抵抗对立性样本。
论文详细内容请见: https://arxiv.org/abs/1801.02774 ,雷锋网 AI 科技评论编译
雷锋网版权文章,未经受权制止转载。概况见。
