
Petuum 专栏
机器之心编译
参与:Panda
不久之前,机器之心推出了引见 AI 创业公司 Petuum 在医疗范畴的一系列研发效果的文集。而除了医疗范畴,Petuum 也在自动驾驶等多个范畴启动了研发项目。本系列我们将引见 Petuum 在自动驾驶研发方向的一系列效果。我们在此以[用于端到端公路驾驶的无监视真实域到虚拟域的域一致]这一创始性论文来开端这一系列。
在获取用于训练自动驾驶零碎的数据时,罕见的做法是运用对立生成模型(GAN)依据来自模仿器的虚拟图像生成接近真实的图像。在这篇论文中,Petuum 团队则反其道而行之,直接以真实驾驶图像为终点,应用无监视去除其中对驾驶行为预测有关的细节而使之简化为虚拟域中的精炼标准表征,并据此预测车辆指令,构成一种愈加高效精确的全新的训练方案。
引言
开发基于视觉的自动驾驶零碎是一个临时以来不断存在的研讨成绩 [27, 24, 10, 9]。在曾经提出来的各种处理方案中,将单个正面相机的图像映射成汽车控制命令的端到端驾驶模型失掉了很多研讨关注 [5, 33, 18],由于这没有繁琐的特征工程进程。研讨者们停止了很多尝试,试图经过应用两头表征来提升单纯的端到端模型的表现(如图 1 所示)。例如,[33] 将语义联系作为主要义务来提升模型的表现,而 [8] 则初次训练了一个检测器来检测四周的车辆,之后再停止驾驶决策。但是,当我们迈向更大的规模时,搜集驾驶数据和标注两头表征的本钱能够会高得不实在际。
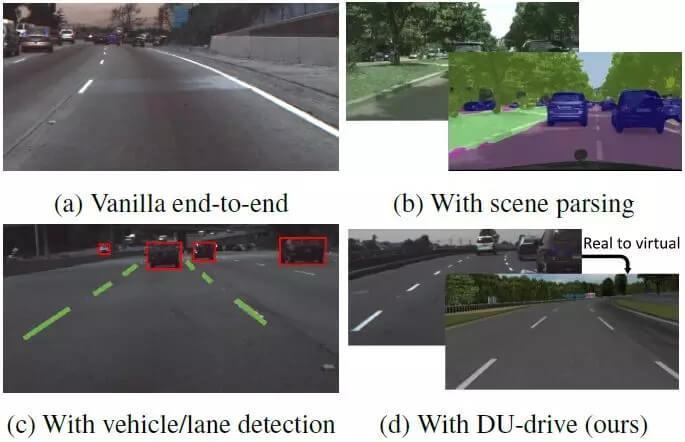
图 1:研讨者们曾经提出了很多种用于基于视觉的驾驶模型的办法。但单纯的端到端模型 (a) 是不可解释的,且只要次优的表现,另外场景解析 (b) 或目的检测 (c) 还需求本钱昂扬的有标注数据。我们的办法 (d) 能未来自不同数据集的真实图像一致成它们在没有多余细节的虚拟域中的标准表征,这可以提升车辆指令预测义务的表现。
此外,由于真实世界很复杂,驾驶场景的普通图像和两头表征中包括了很多多余的细节。这些细节中很多都是带来费事的信息,它们要么与预测义务有关,要么就基本没协助。比方,在公路上驾驶的典型人类驾驶员不会依据前一辆车的品牌或路途之外的景观而改动本人的行为。在完满的状况下,模型应该只经过察看人类驾驶数据就能学习到关键的信息,但由于深度神经网络实质上是黑箱的,所以我们难以剖析模型能否是依据正确的信号做出预测的。[6] 对神经网络的激活停止了可视化,后果标明其模型不只学习了车道标志等对驾驶至关重要的信息,而且还学到了非典型车辆类别等不需求的特征。[18] 给出了经过因果过滤(causal filtering)优化的留意图(attention map)后果,其中似乎包括了相当多随机的留意点。我们很难证明学习这样的信息对驾驶有协助,而且我们置信从驾驶图像中无效地提取最少充沛信息(minimal sufficient information)的才能对提升预测义务的表现而言至关重要。
绝对而言,来自模仿器的驾驶数据当然能防止这两个成绩。一方面,只需复杂地设置一个机器人汽车,我们就可以轻松取得有限量的标注了控制信号的驾驶数据。另一方面,我们可以控制该虚拟世界的视觉外观,还能经过最小化多余的细节来构建一个标准的驾驶环境。
这促使我们开发了一个可以无效地将真实驾驶图像变换成它们在虚拟域中的标准表征的零碎,从而有助于执行车辆指令预测义务。很多已有的研讨任务应用虚拟数据的方式是运用生成对立网络(GAN)将虚拟图像变换成看起来很真实的图像 [12],同时在辅佐目的的协助下坚持标注的完好 [34,7]。我们的办法虽然也是基于 GAN,但却有几方面的不同之处。首先,我们的目的是将真实图像变换成它们在虚拟域中的标准表征,而不是反过去。我们所说的标准表征(canonical representation)是指从背景中别离出了对该预测义务而言最少充沛信息的像素级表征。由于任何图像都只能有一个标准表征,所以我们不会在生成进程中引入任何噪声变量。其次,我们不会试图直接保存标注,由于我们不清楚究竟是图像中的哪些信号确定了车辆指令。相反,我们提出了一种全新的结合训练方案,可以将对预测而言关键的信息逐步地提取到生成器中,这还能使训练波动化以及避免驾驶关键信息的形式解体(mode collapse)。
我们的任务有三大全新的奉献。第一,我们引入了一种无监视的真实域到虚拟域一致框架,可以将真实驾驶图像变换成它们在虚拟域中的标准表征,然后可以据此预测车辆指令。第二,我们开发了一种全新的训练方案,该方案不只能将对预测而言关键的信息逐步地提取到生成器中,还能选择性地避免 GAN 的形式解体。第三,我们给出的实验后果证明了为端到端驾驶义务在虚拟域中运用一致的标准表征的优越性。
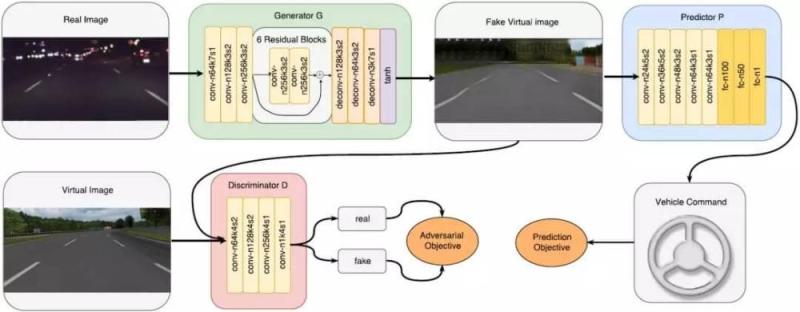
图 2:DU-Drive 的模型架构。其中生成器网络 G 将输出的真实图像变换成假的虚拟图像,然后预测器网络 P 依据这些虚拟图像预测车辆指令。判别器网络 D 的目的是区分假的虚拟图像和真实的虚拟图像。这里的对立目的和预测目的都能促进生成器 G 生成最有助于预测义务的虚拟表征。为了复杂起见,这里省略了实例归一化和每个卷积层/全衔接层之后的激活层。(n 表示过滤器的数量,k 表示核大小,s 表示步幅大小)
网络设计和学习目的
DU-Drive 的学习目的。给定真实域中一个标注了车辆指令的驾驶图像数据集和虚拟域中一个类似的数据集,我们的目的是将真实图像变换成其在虚拟域中的标准方式,然后再在变换后的假虚拟图像上运转预测算法。我们的模型与条件 GAN [22] 亲密相关,其中生成器和判别器都有一个条件因子(conditional factor)作为输出;但仍有两个纤细的差别。其一,在我们的模型中,判别器并不依赖于该条件因子。其二,我们的生成器的输出中不包括任何噪声向量。不同于将复杂的虚拟图像映射成信息丰厚的真实图像(能够存在多种可行方案),将真实图像映射成仅包括足以完成预测义务的最少充沛信息的标准方式的方式应该是独一的。因而,我们可以移除传统 GAN 中的噪声项,运用确定性的生成网络作为我们的生成器。
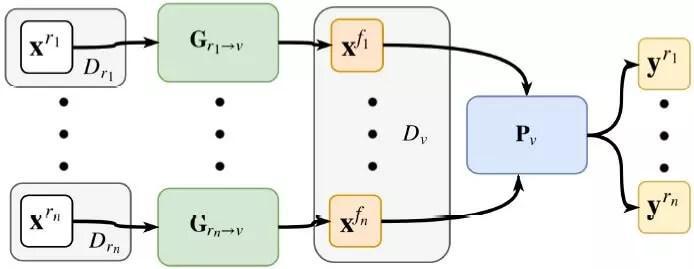
图 3:经过 DU-Drive 完成的域一致(domain unification)。关于每个真实域,都独立地训练一个生成器来将真实图像变换成一致的虚拟域中的假虚拟图像。然后训练一个单张图像到车辆指令的预测器来在多个真实域上停止预测。

图 4:我们的任务所用的样本数据。从上到下:TORCS 模仿器失掉的虚拟数据,来自 comma.ai 的真实驾驶数据,来自 Udacity 应战赛的真实驾驶数据。

图 5:DU-Drive 的图像生成后果。可以看到,对驾驶行为不重要的信息(比方白昼/黑夜光照条件和路途边界外的景观)被一致处置了。有意思的是,这些场景中的车辆也被移除了;思索到我们的实验只是在预测转向角度,所以细心想想这种处置方式实践上是合理的。另一方面,车道标志等对驾驶而言关键的信息失掉了很好的保存。

图 7:条件 GAN 的图像生成后果。背景和前景都遭遇了形式解体,车道标志没有失掉保存。

图 8:CycleGAN 的图像生成后果。上排:真实的源图像和生成的假虚拟图像。下排:虚拟的源图像和生成的假真实图像。
论文: 用于端到端公路驾驶的无监视真实域到虚拟域的域一致(Unsupervised Real-to-Virtual Domain Unification for End-to-End Highway Driving)

论文链接:https://arxiv.org/abs/1801.03458
在基于视觉的自动驾驶的范围内,单纯的端到端模型是不可解释的且只要次优的表现,而居中的感知模型需求联系掩码或检测边界框等额定的两头表征,在我们向更大的规模开展时,其标注本钱能够会高得无法完成。
原始图像和现有的两头表征还充溢了与车辆指令预测有关的费事细节(比方后面车辆的作风或路途之外的景观)。更重要的是,之前的一切研讨都无法应对臭名远扬的域转移(domain shift)成绩——假如我们要将搜集自不同来源的数据交融到一同,那就会极大地障碍模型的泛化才能。
在这项研讨中,我们经过应用搜集自驾驶模仿器的虚拟数据而处理了上述限制;我们还提出了 DU-drive,这是一种用于端到端驾驶义务的无监视真实域到虚拟域的域一致框架。它可以将真实驾驶数据变换成其在虚拟域中的标准表征,然后可以据此预测车辆控制指令。我们的框架有几个优点:1)可以将搜集自不同源散布的驾驶数据映射进一个一致的域;2)可以应用可以收费获取的有标注的虚拟数据;3)可以学习到驾驶图像中公用于车辆指令预测的可解释的标准表征。我们在两个地下的公路驾驶数据集上停止了少量实验,后果清楚地标明了 DU-drive 的表现优越性和解释才能。