
雷锋网AI科技评论按:本文为浙江大学吴骞为雷锋网 (大众号:雷锋网) AI 科技评论撰写的独家稿件,未经雷锋网答应不得转载。
论文标题: DON’T DECAY THE LEARNING RATE, INCREASE THE BATCH SIZE
论文地址: https://arxiv.org/abs/1711.00489
真的是生命不息,打脸不止。前几天刚刚总结了 罕见的 learning rate decay 办法 ,最近又看到这篇正在投 ICLR2018 的盲审,求我如今的心思暗影的面积。。。

然后上 arxiv 一查,哦,Google 爸爸的,干货满满,几乎不容反驳。。。

先点题:
不必衰减学习率啦,只需 增大 Batch Size 就可以啦!
摘要:
-
实践上作者在衰减学习率的时分同时也降低了SGD中随机动摇
的值;衰减学习率相似于模仿退火; -
不同于衰减学习率,作者提出了在 添加 Batch Size 的同时坚持学习率的战略,既可以保证不掉点,还可以增加参数更新的次数;
-
作者还可以即添加学习率又增大 Batch Size,如此可以根本坚持test中不掉点又进一步增加参数更新次数;
-
作者比照了本人的模型和另一篇著名论文( Accurate, large minibatch SGD: Training imagenet in 1 hour )中的模型,Batch Size:65536 - 8192;正确率:77% - 76%;参数更新次数:2500 - 14000;
随即梯度下降法与曲线优化
传统的学习率遵照以下两个约束:
(1)
(2)
直观来看,公式1约束最小值优化的参数一定存在,公式2保证了衰减学习率有助于疾速收敛至最小值处,而不是由于噪声在震荡。
但是以上结论是给予 Batch Size 不变推导出的。作者基于前作(
A BAYESIAN PERSPECTIVE ON GENERALIZATION AND STOCHASTIC GRADIENT DESCENT
)推导出另一个解释优化进程的模型,并指出可以经过找到某个最优化的随机动摇值
(其中
为学习率 ,
为训练数据集大小,
为 Batch Size 大小),使得模型到达最优值。
模仿退火法和泛化才能下降
普遍的研讨后果指出小 Batch Size 训练的模型在 test 中的泛化才能比大 Batch Size 的要好。前作中还得出了固定学习率下的最大 Batch Size 优化值
,并验证了
与随机噪声值
有关。
研讨者以为小 Batch 中的随机误差有助于 SGD 的收敛,尤其是在非凸曲线优化成绩上。噪声可以协助 SGD 收敛至所谓平滑最小值(flat minima)而不是锋利最小值(sharp minima)以保证 test 的泛化特性。
作者发现大局部研讨者在训练进程中都运用了「early stop 」的办法(当验证集的点数不再增高时中止训练),因而作者实践上有意的阻止了网络抵达最小值。衰减学习率的成功是经历式的。详细进程可以类比于模仿退火法中,较大的初始乐音有助于探究更大范围内的参数空间而不是很快地堕入部分最优值;一旦作者找到了能够的最优区域后开端增加噪声来 finetune 到最优值。
而这也能解释为什么近来越来越多的研讨者开端运用 cosine 式衰减学习率或阶梯形的衰减——物理退火法中,迟缓衰减温度是零碎收敛到某些锐利的全局最小值;而团圆地降高温度则有利于收敛到不是最低但足够鲁棒的区域。
无效的学习率和累积变量
许多研讨者开端运用带 momentum 的 SGD 下降法,其噪声值与原始 SGD 稍有不同:
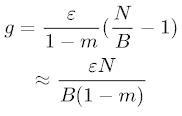 (3)
(3)
当
时该噪声将退步为原始 SGD 噪声。比照两种 SGD 可以得出带 momentum 的 SGD 方
法的无效学习率应为 。
比照原始 SGD,作者可以推导:成比例的缩小
可以坚持模型功能。但是,作者发现若成比例的缩放学习率
和 Batch Size 表现良好,但是若依照
倍缩放 Batch Size 和冲量系数
的话则会招致 test 功能下降。这是由于冲量式的更新在工夫上是累积的,因而当
设置较大时需求额定的训练次数才干保证模型处于相反程度,原文的补充资料中有较详细的剖析,此处不作解释。
随着冲量系数
的增大,还会添加网络遗忘旧的梯度的工夫(该工夫和
成反比),一旦工夫跨度到达几个 epoch 以上时,损失空间将会变得不利调整从而障碍训练。这种状况在学习率衰减的时分尤其分明。这也是为什么有些论文引荐在初始的若干 epoch 时提升学习率。但是,在作者的大 Batch Size 实验中,这种做法却会带来零碎不波动性。
实验比照
实验中运用的网络是「16-4」宽型残差网络构造(wide ResNet architecture),运用了 ghost batch norm 办法来保证均匀梯度与 Batch Size 不相关。
实验中运用的比照战略是阶梯形的,学习率阶梯形下降,对应的,Batch Size 阶梯形上升。
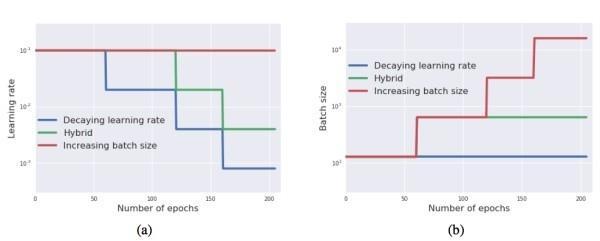
图中,蓝线代表罕见的坚持 Batch Size,逐渐衰减学习率的办法;红线代表与之相反的,坚持学习率,相应的上升 Batch Size 的战略;绿线模仿真实条件下,上升 Batch Size 到达显存下限的时分,再开端下降学习率的战略。
该实验可以验证两个成绩:
学习率下降能否是必需的——若是则三条曲线应不同;
能否是由于随机噪声的变化招致后果不同——若是则三条曲线相反;
实验后果如下(a)所示, 并验证了随机噪声与训练曲线的相关性。
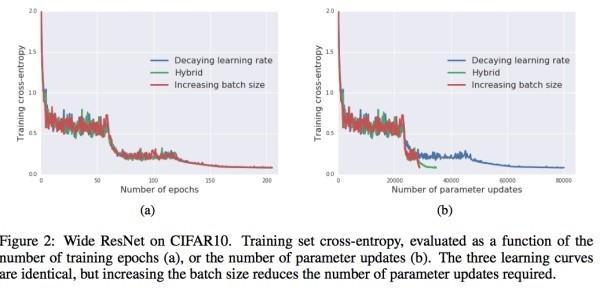
实验后果(b)进一步显示增大 Batch Size 的益处,察看损失值与参数更新次数的关系,显然,增大 Batch Size 的办法中 参数更新的次数远少于 衰减学习率的战略。
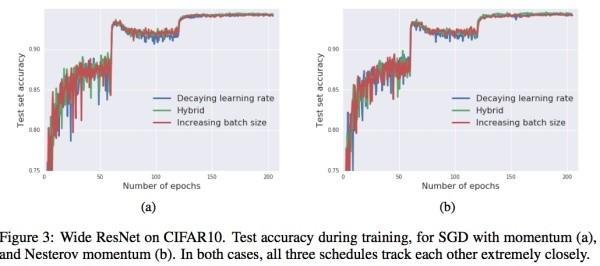
下图是两种不同的梯度下降战略的 test 后果,显然效果相差不大。
增大学习率战略
作者预备了四组实验:
Original training schedule:初始学习率设为 0.1,momentum 为 0.9,Batch Size 为 128,采用衰减学习率战略,每阶段增加 5 倍;
Increasing batch size:初始学习率设为 0.1,momentum 为 0.9,Batch Size 为 128,采用增大 Batch Size 战略,每阶段添加 5 倍;
Increased initial learning rate:初始学习率设为 0.5,momentum 为 0.9,Batch Size 为 640,采用增大 Batch Size 战略,每阶段添加 5 倍;
Increased momentum coefficient:初始学习率设为 0.5,momentum 为 0.98,Batch Size 为 3200,采用增大 Batch Size 战略,每阶段添加 5 倍;
当 Batch Size 添加到最大值
后即不再添加,以保证
,并相应的开端增加学习率。
后果如下所示,结论与上文相反,办法4的后果稍差也在章节无效的学习率和累积变量中有所解释。
训练 IMAGENET 只用更新 2500 次参数
论文 Accurate, large minibatch SGD: Training imagenet in 1 hour 中的参数与实验参数设置和后果比照如下:
上述论文中的 Batch Size 曾经到达了坚持网络波动的最大值,为了进一步扩展 Batch Size 可以适当增大 momentum 的值。最终,作者的网络到达了显存的下限
并保证了
。其参数设置与后果如下所示,可以看到精确率下降不大但是无效增加了参数的更新次数。
增大 Batch Size 就可以不必衰减学习率了,emmm,听起来很有道理,但是总觉得哪里不对...

最初,祝大家炼丹愉快!
雷锋网特约稿件,未经受权制止转载。概况见。
