
大众号/机器之心
选自arXiv
作者:Xiaodan Liang、Lisa Lee、Wei Dai、Eric P. Xing
机器之心编译
关于自动驾驶零碎而言,精确预测驾驶场景的将来状况关于驾驶平安而言至关重要。卡内基梅隆大学和 Petuum 的一项研讨试图经过对偶对立学习机制来处理这一成绩,他们提出的对偶运动生成对立网络在分解逼真的视频将来帧和流上都获得了很好的表现。机器之心对该研讨的论文停止了编译引见。
虽然用于监视学习的深度学习架构获得了很大的停顿,但用于通用和可扩展的视觉义务的无监视视频表征学习依然很大水平上仍未失掉处理——虽然这也是一个关键的研讨成绩。最近,预测视频序列中的将来帧 [22,20,28] 曾经成为了视频数据的无监视学习的一个很有希望的方向。
由于自然场景具有复杂的外观和运动静态,所以视频帧预测自身是一项很有应战性的义务。直观上讲,为了预测将来帧中的实践像素值,模型必需要能了解像素层面的外观和运动变化,这样才干让之前帧的像素值流入到新的帧中。但是,大少数已有的以后最佳办法 [20,28,18,16,26,37] 都运用了生成式神经网络来直接分解将来视频帧的 RGB 像素值,无法明白建模固有的像素方面的运动轨迹,从而会招致预测后果模糊。虽然最近有些研讨 [23,16,26] 试图经过设计能从之前的帧复制像素的运动场层(motion field layer)来缓解这一成绩,但由于两头流不精确,预测后果往往有明显的伪影成绩。
在这项任务中,我们开发了一种对偶运动生成对立网络(dual motion Generative Adversarial Network)架构,可以运用一种对偶对立学习机制(dual adversarial learning mechanism)来学习明白地将将来帧中的分解像素值与像素上的运动轨迹坚持连接。详细来说,它能同时依据一种共享的概率运动编码器而处理原始的将来帧预测(future-frame prediction)成绩和对偶的将来流预测(future-flow prediction)成绩。受 GAN [6,13] 的成功的启示,我们在两个将来帧和将来流生成器以及两个帧和流鉴别器之间树立了一种对偶对立训练机制,以便失掉与真实数据难以区分的预测后果。经过相互的彼此审查,这种根本的对偶学习机制将对将来像素的想象和流预测联络到了一同。我们的对偶运动 GAN 由如下三个完全可微分的模块构成:
- 概率运动编码器可以获取能够呈现在不同地位的运动不确定性并为之前的帧发生隐含的运动表征,然后这些表征会被用作两个生成器的输出。
- 然后将来帧生成器会预测将来的帧,预测后果会在两个方面失掉评价:帧鉴别器会对帧的逼真度停止评价,流鉴别器会依据之前帧和预测帧之间的估量的流而评价流的逼真度。
- 将来流生成器又会预测将来的流,这也会在两个方面失掉评价:流鉴别器会对流的逼真度停止评价,帧鉴别器会依据推算失掉的将来帧(是经过一个嵌套的流变形层(flow-warping layer)计算的)来评价帧的逼真度。
经过从两个对偶的对立鉴别器学习对称的反应信号,将来帧生成器和将来流生成器可以受害于彼此互补的目的,从而失掉更好的辨认预测。在运用了 KITTI 数据集 [5] 中车载摄像头拍摄的视频和来自 UCF-101 数据集 [27] 的消费者视频训练之后,我们的对偶运动 GAN 在分解接上去的帧以及自然场景的临时将来帧上的表现超越了一切已有的办法。我们还经过在另一个汽车摄像头拍摄的 Caltech 数据集 [3] 以及一个来自 YouTube 的行车记载仪原始视频集合上的测试证明了它的泛化才能。此外,我们还经过少量 ablation study(注:指移除模型和算法的某些功用或构造,看它们对该模型和算法的后果有何影响)标明了每个模块的设计选择的关键性。我们还在流估量、流预测和举措分类上停止了进一步的实验,后果标明了我们的模型在无监视视频表征学习上的优越性。
对偶运动 GAN
我们提出了对偶运动 GAN,这是一种用于视频预测的完全可微分的网络架构,可以结合处理原始的将来帧预测和对偶的将来流预测。图 1 给出了这种对偶运动 GAN 架构。我们的对偶运动 GAN 以视频序列为输出,经过交融将来帧预测与基于将来流的预测来预测下一帧。
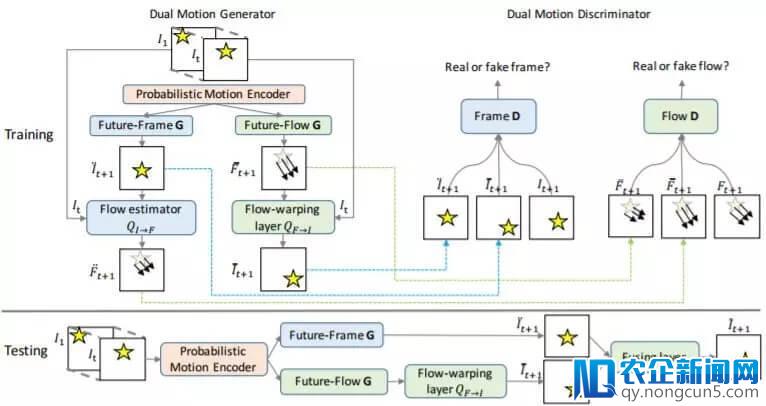
图 1:我们提出的对偶运动 GAN 运用了一种对偶对立学习机制来处理将来帧预测和将来流预测义务。首先将一个视频序列 I1,…, It 送入概率运动编码器 E 以失掉隐含表征 z。对偶运动生成器(左侧的 Future-frame G 和 Future-flow G)对 z 停止解码,以分解将来帧和流。对偶运动鉴别器(右侧的 frame D 和 Flow D)辨别学习分类真实的和分解的帧或流。流估量器 QI→F 依据预测帧
和真实帧 It 来估量流
,这又会进一步失掉 Flow D 的评价。流变形层 QF→I 会运用预测失掉的流
来对真实帧 It 停止变形操作,从而生成变形后的帧
,然后又会经过 frame D 评价。上图中的下局部是测试阶段。
网络架构
图 2 和图 3 辨别给出了生成器和鉴别器网络的概况。为了简约,图中略去了池化层、批标准化层和两头卷积层之后的 ReLU 层。
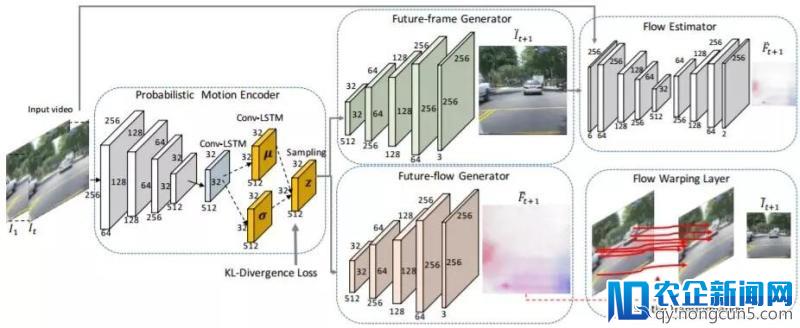
图 2:对偶运动生成器。给定序列中的每一帧都会被循环地送入概率运动编码器 E,其中包括 4 个卷积层、1 个两头 ConvLSTM 层和 2 个用于失掉均值图和方差图的 ConvLSTM 层,以用于对 z 采样。接上去,将来帧生成器 GI 和将来流生成 GF 会辨别解码 z 以失掉将来帧
和将来流
。然后流估量器 QI→F 会生成 It 和
之间估量的流。执行差分 2D 空间变换的流变形层 QF→I 会依据将 It 变形为
。
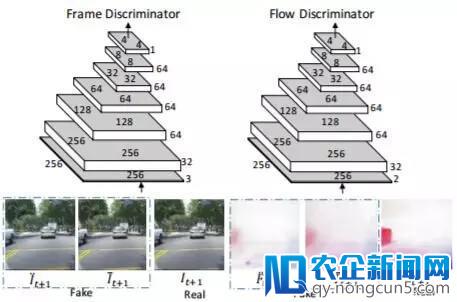
图 3:两个对偶运动鉴别器的架构。帧鉴别器和流鉴别器辨别学习分类真实的和分解的帧和流。
实验
表 1:经过 KITTI 数据集的训练之后,在 Caltech 和 YouTube 剪辑上的视频帧预测表现(MSE 和 SSIM)
表 2:在 UCF-101 和 THUMOS-15 上的视频帧预测表现(PSNR 和 SSIM)

图 4:在 YouTube 剪辑上的定性后果。为了更好地比拟,我们用白色框和蓝色框突出展现了两辆以相反方向行进的车辆的预测区域

图 5:在来自 Caltech 数据集的车载摄像头视频上,与 Prednet [18] 的下一帧预测后果的定性比拟
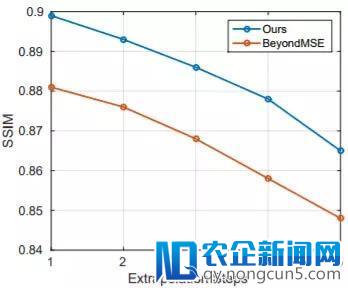
图 6:在 Caltech 数据集上的多帧预测表现的比拟

图 7:我们的模型在 Caltech 序列上的 5 个工夫步骤的多帧预测后果

图 8:我们的模型在来自 KITTI 数据集的两个序列上失掉的一些将来帧预测和将来流预测示例

表 3:在 KITTI 数据集上的流估量和预测的起点误差。这里值更低表示表现更好。
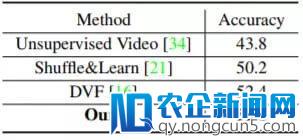
表 4:在 UCF-101 上的举措辨认的分类精确度
论文:用于将来流嵌入式视频预测的对偶运动生成对立网络(Dual Motion GAN for Future-Flow Embedded Video Prediction)

链接地址:https://arxiv.org/abs/1708.00284
视频的将来帧预测是无监视视频表征学习的一个很有出路的研讨方向。视频帧是基于视频中的外观和运动静态,依据之前的帧经过固有的像素流而自然生成的。但是,已有的办法都重在直接想象像素值,从而会失掉模糊的预测。在这篇论文中,我们开发了一种对偶运动生成对立网络架构,可经过一种对偶学习机制来学习明白地强迫将来帧预测与视频中像素层面的流分歧。其原始的将来帧预测和对偶的将来流预测可以构成一个闭环,从而能为彼此生成信息丰厚的反应信号,进而完成更好的视频预测。
为了使分解的将来帧和流都与理想状况难以区分,我们提出了一种对偶训练办法以确保将来流预测可以协助推理逼真的将来帧,而将来帧预测又反过去能协助失掉逼真的光流。我们的对偶运动 GAN 还能运用一种新的概率运动编码器(基于变分自编码器)来处置不同像素地位的自然的运动不确定性。
我们停止了少量实验,后果标明我们提出的对偶运动 GAN 在分解新视频帧和预测将来流上表现优于之前最佳的办法。我们的模型能很好地泛化到不同的视觉场景上,并且表现出了在无监视视频表征学习方面的优越性。