
大众号/DeepTech深科技
身为全球最聪明的公司榜首,NVIDIA 不只在由麻省理工科技评论主办的 EmTech China 中宣布了精彩的演说,会后主讲者 NVIDIA 首席迷信家 Bill Dally 也在专访中向 DT 君揭露了 NVIDIA 目前在 GPU 产品、及相关计算生态的的规划。
NVIDIA 在 GeForce 256 芯片中添加了包括 Vertex Shader 以及 Pixel Shader 等可编程计算才能,并以 GPU 为相关绘图芯片产品定名,望文生义,GPU 是 Graphics Processor Unit,不像前代 RIVA 架构只能单纯停止绘图任务,GeForce256 的推出可说是重新定义其绘图芯片产品,绘图变成是其芯片功用的一部份,可编程的算力才是将来让 NVIDIA 发光发热的中心。

图丨Bill Dally的简介
不过往后数年,虽然具有了顺序设计才能,但实践上于计算范畴有所发扬也是 10 年后的事情。 这是由于事先 NVIDIA 凭仗成功的绘图架构获得市场抢先,且和 ATI 的市场大战正炽热,流处置计算还没有很好的使用之故,NVIDIA 也没有意会 GPU 的算力将来会有如此庞大的潜力。 2004年,由 Bill Dally 率领的斯坦福大学团队针对 GPU 的可编程局部设计了许多流处置技术的计算架构,这些研讨效果后来成为 CUDA 的根底。
后来 NVIDIA 也以相关研讨为根底,推出通用并行计算架构 CUDA,以及针对计算使用的 Tesla 产品线。Bill Dally 对此可说是面前的重要推手之一。
在 2009 年,Bill Dally 参加 NVIDIA 后,NVIDIA 在 GPU 计算的脚步更是飞快开展。

图丨Bill Dally在EmTech China上的演讲
GPU 从本来在各大学中单纯用来停止根底迷信研讨的辅佐角色,迅速成为各大超算、数据中心的计算中心,每年全球前五百大超算榜单之中采用 NVIDA 计算方案的简直都首屈一指。 而配合 CUDA 生态的成熟,更从 2016 年大热的AI 议题中,带起了机器学习与深度学习的使用热潮。
但是 GPU 在面对如此庞大的计算市场,以及此起彼落的应战者,能否还能维持荣景?Bill Dally 为深科技读者带来独家的观念。
DT 君:您可以复杂引见目前 NVIDIA 的主力产品线吗?
Bill Dally: 我们实践上有四个方向同时停止,有四条产品线。 其中包括了 GeForce、Quadro、Tesla 以及 Tegra。 辨别针抵消费性图形计算、专业图形计算、专业高效能计算、以及嵌入式计算平台,根本上都是以 GPU 为共通的架构根底,但针对不同使用停止微调,使之更合适不同的使用情境。
DT 君:针对 Volta 针对 AI 计算所做出的架构革新,比方说添加了 TensorCore,这会改动 GPU 的定位吗?
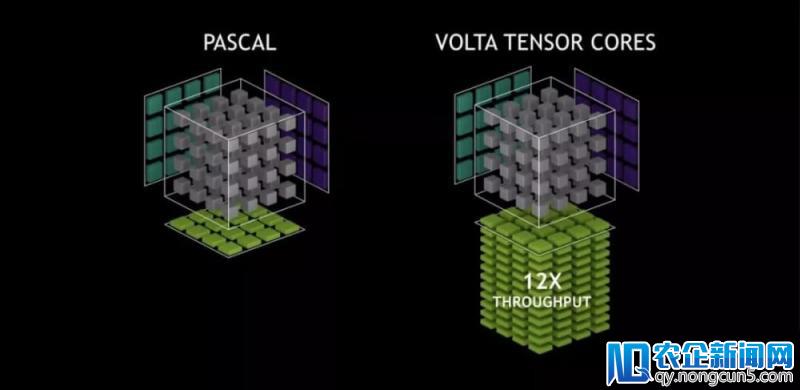
图丨TesorCore架构
Bill Dally: TensorCore 是个营销代号,其架构的真相就是添加一些绝对应的指令集,依托这些指令,让 GPU 可做半精度 (Half- precision) 的矩阵乘积聚积,而这是许多深度学习算法所运用的的外部循环根底逻辑。 而且它实践上并没有改动 GPU 的根本概念。Volta 依然是一个名副其实的 GPU,它在渲染图形方面的功能表现仍是一流程度,参加 TensorCore 并没有牺牲 GPU 自身的任何特性,反而是发明了双赢。如今 Volta 可以更好的针对深度学习使用,同时也能发扬百之百的绘图功能表现。
其实很多都是关于数据类型的选择和指令的选择。 GPU 架构实践上是一个框架,你可以在其中放入不同的数据类型和不同的指令来完成不同的使用顺序。 比方说,开普勒架构对推理任务不能很好的支持,它也不具有半精度浮点计算才能。
现在数据型态的支持是深度学习的关键,而开普勒会运用 FP32,招致计算本钱十分昂贵。从Pascal 我们开端支持推理计算以及 FP16 数据训练计算才能,但你不会说 Pascal 因而就不是GPU 了。Volta 参加 TensorCore 也是相似的情形。
Volta 依然是 GPU,可以做图形计算。 我以为GPU 是十分高效的并行计算架构。而我们并没有牺牲任何其他的事情来做到这一点。

图丨英伟达Volta
DT 君:所以我们依然可以等待 TensorCore 可以在图形义务中发扬功用吗?
Bill Dally : 是的,现实上,深度学习和图形学之间有很大的协同作用,我们的发现是,经过深度学习,我们可以使图形更好 。然后停止视频研讨,开发图像抗锯齿和去噪的新算法,并提供图像的工夫波动性,这些都是基于深度学习。因而,经过拥有深沉的学习推理才能,芯片如今实践上在图形表现方面会比没有 TensorCore 更好。
本次涌现的 AI、区块链和物联网热潮不同于以往,将对产业、社会和生活产生真正堪称“颠覆性”的变革。IT 技术人员需要全方位地“换脑”:对原有的知识结构进行全面刷新,全面升级。 DT 君:您如何对待在深度学习范畴的应战者,比方说 FPGA?
Bill Dally : 我不是很担忧 FPGA。 假如你想处理某个成绩,并且你情愿投入少量的工程工夫,那么干脆直接开发 ASIC 就好了。我是这么看 FPGA 的,假如你在 ASIC 上设计了一个门,那么把同一个门放在一个 FPGA 上,占用的芯片面积和功耗都会是相差很多。
所以关于实践上你必需用随机门任务的东西,FPGA 比 ASIC 要分明更弱。FPGA 只能在 FPGA中运用少量硬件模块的成绩上做得很好。所以,假如你曾经硬衔接一些 FPGA 有 18 个 beta 算术单元来停止 DSP 操作,其他的有 14 个点单元。
当你不得不运用 FPGA 上的栅极时,它的表现会变得差强者意。也因而我们不以为它们是十分有竞争力的。

图丨Tesla V100
DT 君:若 FPGA 并不是个值得担忧的对手。那么您会担忧什么?
Bill Dally :有很多创业公司正在树立专门的深度学习芯片,我们当然也很关注这些开展。但是我的哲学总是“我们应该做我们以为可以做到最好的任务”,而他们的选择根本限制了他们的开展空间,致使于不能做得更好,由于我们正在尽力做到最好。
假如我们以三个细分类别的方式细分深度学习的话 ,辨别是训练、推理和 IoT 设备的推理。
关于训练, 我们不断在做的是专注于深度学习的 GPU。 所以假如你光是单纯为了深度学习而树立一个芯片,那使用能够会过于狭隘,无法统筹到其他能够的使用。而在我们的架构中,由于 HMMA 的操作,Volta 架构所集成的 TensorCore 可以做到很庞大的数学计算,它只需求一条指令即可完成 128 个浮点计算步骤,可以统筹更多使用。
我们的确有一些对深度学习协助不是那么大的额定的芯片区块 ,比方说针对图形绘制任务的光栅化 (rasterization) 和纹理映射和分解 (texture mapping and compositing) 局部,但是这个局部并不大,若是构建一个公用芯片,他们确实可以摆脱一小局部芯片上的非计算必要区块,实际上芯片本钱会更有优势。
虽然我们也可以这样做,只是没有任何商业意义,我们的想法是,最好是做一个芯片,并可以做很多事情。不管是绘图或许是用在数据中心,我们想要运用该芯片来尽量做到更多的事情。

图丨正在参与EmTech圆桌的Bill Dally
DT 君:EmTech 大会上量子计算成为另一个热点,那您怎样看这件事?NVIDIA 有方案停止相关范畴的开发方案吗?
Bill Dally : 我们成立了一个研讨小组,研讨量子计算的停顿察看。从迷信的角度来看,这是一个很有意思的范畴。
近来人们曾经获得了很大的提高,如今人们曾经超越了 50 量子比特,并且维持量子态的工夫可以做到更长。但是,关于一个可行的商业使用顺序来说,依然无数量级的需求。量子优势在于,在量子计算机上运转的算法,没有方法在传统计算机上以相反的功能运转。
所以算法的进程就是模仿量子计算机。 但那并不重要。人们关怀的是可以运转模仿量子化学这样的算法,或许运转诸如将复合数字分解成两个部落的算法来破解编码。这两者所需的量子比特都是数千以上。所以我们离这个成绩还有很远的间隔。
虽然我们以为量子计算还没有到适用的境地,但我们仍十分细心地关注相关技术的开展脚步,藉此防止发作我们无法掌握的变化。

DT 君:目前 NVIDIA 正积极打造自动驾驶平台,但汽车对功耗的控制其实相当注重,业界也都提出不少竞争产品,您怎样看现有的方案?
Bill Dally : 我们实践上提供的不只仅是架构,也同时为自动驾驶汽车提供完好的处理方案。 比方说基于 Xavier 架构的 Drive PX。这是最无效的计算平台,我的意思是,其 30 Tera Ops 的深度学习功能仅需求 10 瓦左右的功耗,所以每瓦计算才能超越 3 Teraflops。而 DLA 中的局部是每瓦特超越 4 Teraflops。所以这是一个效率十分高的平台。
最重要的是,作为 Drive PX 零碎的一局部,我们有一个完好的软件平台,包括用于感知的神经网络,相机和激光雷达以及雷达,然后是用于途径规划和控制的软件车辆。
我们本人测试车队的自动驾驶汽车曾经完全运转 NVIDIA 软件。我们也向汽车厂商提供该硬件和该软件。我们在车里也有一个以前叫做 Co-Pilot 的软件,如今重新命名为 Drive IX,它的次要功用就是监视着司机,它有眼睛跟踪和头部跟踪,它要是看到司机心猿意马,或过度劳累就可要求汽车做出过度警示。它有手势辨认,所以你可以用手势来控制汽车。我们同时也为汽车制造商提供完好的自动驾驶处理方案。 我以为这是业界目前能取得最具竞争力的处理方案。
DT 君:您看来不是很担忧来自业界的竞争?
Bill Dally :我总是担忧我们的竞争对手。 但是我们的理念是向前看,而不是频频回头,所以我们是抢先的,我们想要做的就是弄清楚我们如何可以尽能够高效地运转,不管是市场战略或产品架构。