
雷锋网 (大众号:雷锋网) AI 科技评论按:言语词汇的多义性曾经是一个越发让人头疼的成绩。比方女生对男冤家说:“生日礼物我想要MAC”,原本心胸等待地推测他买来的唇彩会是什么色,后果收到的能够是一台苹果笔记本电脑…… 苹果电脑自身当然并没有哪里不好,但词语指代弄混的时分还是挺让人舒服的。
人类尚且有了解不对词语类别的时分,人工智能自然也还没能攻克这个成绩。不过雷锋网 AI 科技评论理解到,OpenAI 近期新设计的 AI 在结合上下文的词语判别上做出了打破,测试中的表现相比已有的其它 AI 也有了大幅提升。

「The prey saw the jaguar across the jungle」(猎物看到了穿越丛林的美洲豹)

「The man saw a Jaguar speed on the highway」(这团体看到美洲豹奔驰在高速公路上)
OpenAI 在近期的一篇论文中引见了本人新设计的神经网络 Type,它可以尝试了解句子中的单词,把它归类到大约一百个自动学到的非独占性类别中。OpenAI 想到的典型例子是「jaguar」或许「美洲豹」,比方关于下面两个句子,这个零碎不会立刻把两个「jaguar」都一致断定为跑车、植物或许别的东西中的某一种,而是根据预选择的类别解一组 20 个贝叶斯成绩,推理失掉判别后果。相比之前的零碎,Type 在数个实体分辨(entity disambiguation)数据库上的测试后果都有大幅提升。
在 OpenAI 的训练数据中,「jaguar」这个词大约有 70% 的状况是指跑车,29% 的状况是指植物,还有 1% 的状况是指美洲豹攻击机。依据 Type 判别,「The man saw a Jaguar speed on the highway」中的「jaguar」的各种语义呈现的能够性变化并不大,看起来模型觉得一只大猫在高速公路上跑步也没什么不妥;但「The prey saw the jaguar across the jungle」中,模型的判别就发作了很大变化,十分一定这是一只大猫,毕竟捷豹跑车基本不合适在森林里开。
模型在 CoNLL(YAGO)数据集上的测试精确率为 94.88%,此前的顶级模型的表现为 91.5% 和 91.7%;在 TAC KBP 2010 应战赛数据集上的精确率为 90.85%,此前的顶级模型的表现为 87.2% 和 87.7%。之前的这些办法运用的是散布式表征,OpenAI 的 Type 在这些义务中都有明显的提升,间隔完满的类别预测精确率 98.6% 到 99% 越来越近。
Type 总体引见
这个零碎以如下的步骤运转:
-
从单词的维基百科页面提取一切的内链,确定这个词能够指代的实体都有什么。比方,关于 https://en.wikipedia.org/wiki/Jaguar 这个维基百科的链接,经过火析之后确定这个页面的内容的确是「jaguar」这个词的一个意思。
-
爬维基百科的分类树(借助 Wikidata 的知识图),从而确定每一个实体都能被归入哪些类别。比方在 https://en.wikipedia.org/wiki/Jaguar_Cars 捷豹汽车的页面底部,有上面「英国品牌」、「汽车品牌」、「捷豹汽车」几个类别分类(而且每个类别都还有本人所属的类别,比方属于汽车)
-
选出大约 100 个类别作为模型的类别零碎,然后优化对类别的选择,以便让它们可以完全掩盖就任何实体。我们曾经晓得了从实体到类别的映射,所以关于恣意给定的类别零碎,都可以把每个实体表征为一个大约 100 维的二进制向量,其中的每一维就对应着能否属于某个类别。
-
依据每个维基百科的内链和上下文文本生成训练数据,其中会把单词和文本内容映射到方才提到的大约 100 维的二进制向量,然后训练一个神经网络预测这种映射。这一步就把后面的几步联络起来了, 维基百科的链接可以把单词映射到一个实体,然后从第二步晓得每个实体的类别,第三步选出了这个分类零碎外面要用的类别 。
-
到了测试的时分,给定一个词和上下文,这个神经网络的输入就可以看作是这个词属于每个类别的概率。假如确切晓得了类别零碎的内容,就可以减少范围,确定到某一个实体(假定类别是经过精心选择好的)。不过也必需经过基于概率的一组 20 个成绩组成的判别进程,经过贝叶斯实际计算出这个词被分辨为各个能够的类别的概率辨别是多少。
一些类别分辨的例子
「 蓝莓 是一种可以食用的水果,又属杜鹃花科越橘属植物产出。」
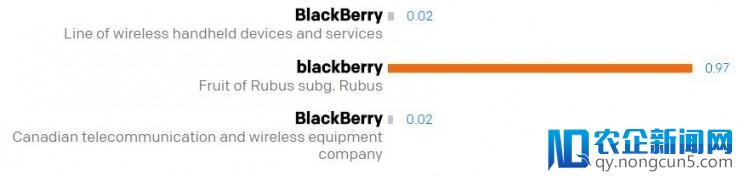
「在 2013 财年的第二季度, 黑莓 售出了 680 万台手持设备,但同时也初次被竞争对手诺基亚的 Lumia 系列的销量逾越。」
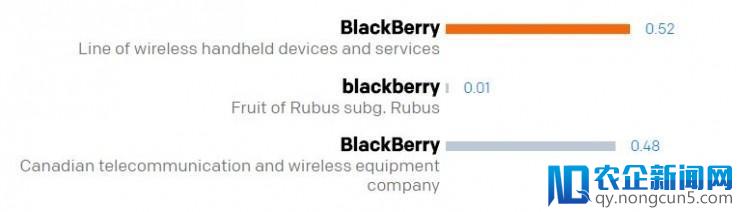
「在 Python 中可以可以操作 string 。」

「 Python 普通是无毒的。」

数据清洗
Wikidata 的知识图经过转换后可以作为实体到类别映射的细粒度训练数据源。OpenAI 的研讨人员们递归运用其中的「instance of」(是 xxx 的一个实例)关系以确定恣意给定的实体都可以属于哪些类型,比方,每个「人类」上面的无效节点都属于「人类」类型。维基百科也可以经过「category link」功用提供实体到类别的映射。
从维基百科的外部链接失掉的统计后果可以很好地预测特定的词汇指代某个实体的概率如何。不过数据里有很多噪声,由于维基百科常常会链接到类型的某个实例而不是这个类型自身,比方会把「国王」链接到「英国查尔斯王子一世」(回指),或许链接到一个昵称上去(转喻)。这就让有联络的实体的数量大爆炸,也让链接呈现的频率变得混乱(比方「国王」有 974 个相关的实体,「皇后」链接到皇后乐队有 4920 次,链接到伊丽莎白二世有 1430 次,而链接到君主只要 32 次)。
最复杂的处置办法是对不常常呈现的链接剪枝,不过这也会带来丧失信息的成绩。所以 OpenAI 的研讨人员们转而运用 Wikidata 的属性图,启示式地把链接转换为它们的「普通」意思,像下图这样。
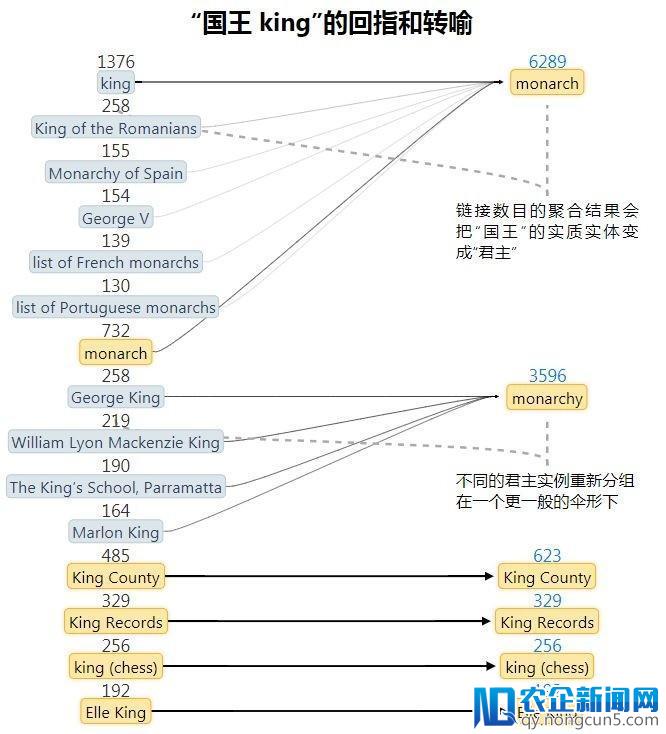
经过这样处置之后,「国王」相关的实体就从 974 大幅下降到了 14 个,同时「皇后」到「君主」的链接数目也从 32 个添加到了 3553 个。
学习一个好的类别零碎
我们希望学到最好的类别零碎和参数,这样才干让分辨单词的精确率最大化。能够的类别品种组合有有数多种,找到一个准确解似乎难以完成。所以 OpenAI 的研讨人员们运用了启示式搜索或许随机优化(演化算法)的办法选出一个类别零碎,然后用梯度下降训练出一个类别分类器,用来预测类别零碎的表现。
在这里,理想的类型零碎该当有足够的区分度(这样可以疾速减小能够的实体散布),同时还该当易于学习(这样单词的上下文可以包括足够的信息,足以让神经网络揣测合适什么类型)。OpenAI 的研讨人员们用了两种启示式办法停止类别零碎的搜索,一种是基于可学习性的(训练出的分类器预测类别所在的均匀 AUC),另一种是先见精确率(假如网络预测对了一切类型,那么区分实体的才能如何)。
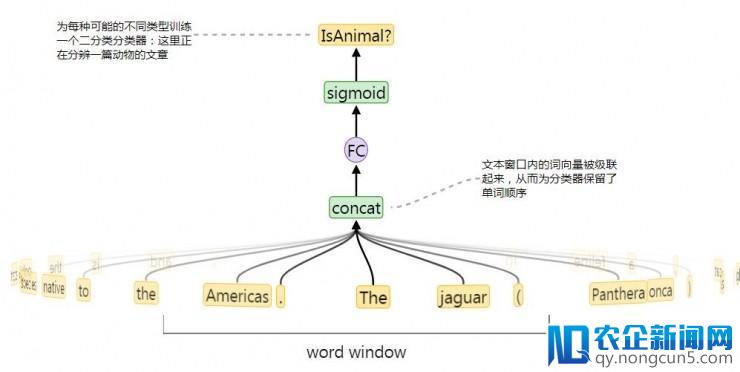
类型零碎的退化
OpenAI 的研讨人员们为数据集中最罕见的 15 万个类别辨别训练了二分类分类器,分类器的输出就是上图中文本窗口对应的一段。分类器的 AUC 就看作为这个类型的「可学习性」分数。高 AUC 表示表示很容易从上下文中揣测出所属类型,不好的表现就意味着训练数据不够,又或许设定的文本窗口并没有起到什么协助(在 ISBN 之类的非自然类型预测中很容易发作)。完好的模型需求好几天赋能训练好,所以他们也同步设计了一个小得多的模型作为「可学习性」分数的代理模型,只需求 2.5 秒就可以完成训练。
「可学习性」分数和计数统计都可以用来估量把某一组类别作为类别零碎之后的模型表现。穿插熵办法的优化表示图如下。
每步优化中运用了 100 个样本。更多的样本可以让优化后果更精确,但破费的工夫也更长、模型大小也更大。图示的优化失掉的后果如下图
整个模型的穿插熵如下
神经类型零碎
依据类型零碎优化失掉的最好后果,OpenAI 的研讨人员们接上去就可以用类型零碎生成的标签给维基百科的数据做标注。失掉了这样的数据后(在 OpenAI 的实验中,他们共用了英语和法语的各 4 亿句)就可以训练双向 LSTM,独立地预测每个单词的一切类型的契合状况。在维基百科的源文本上只要网站内链是可以确认运用的,但是这也曾经足以训练出一个类别预测首位预测精确率超越 0.91 的深度神经网络。
风趣的是,在束搜索失掉的某个分类零碎中,除了包括了典型的航空、穿着、游戏之类的分类之外,还令人不测地包括了一些十分详细的分类,比方「1754 年在加拿大」,意味着 1754 年在用来训练网络的一千多篇维基百科文章中是十分空虚风趣的一年。
下一步研讨
OpenAI 表示本人的这项研讨和以往尝试处理这个成绩的办法有许多的不同,他们也很感兴味散布式表征的端对端学习相比他们开发的基于类别推理的零碎最好能有什么样的表现。而且论文中的分类零碎只是用了维基百科数据集的很小的一局部创立出的,假如扩展到整个维基百科的规模,有能够可以树立出有更宽广使用空间的分类零碎。
论文地址: https://arxiv.org/abs/1802.01021
开源地址: https://github.com/openai/deeptype
via OpenAI ,雷锋网 AI 科技评论编译
相关文章:
约请函or应战书?OpenAI 喊你研讨 7 个未解 AI 成绩
OpenAI 开源最新工具包,模型增大 10 倍只需额定添加 20% 计算工夫
AI能看懂英文,阿里巴巴夺实体发现测评全球第一
雷锋网版权文章,未经受权制止转载。概况见。
