Jeff Dean连发十条推特,片面解读Cloud TPU
1. 谷歌已为那些想拜访高速减速器来训练机器学习模型的人们,推出了Cloud TPU的beta版。详细细节可参见博客:
https://cloudplatform.googleblog.com/2018/02/Cloud-TPU-machine-learning-accelerators-now-available-in-beta.html?m=1
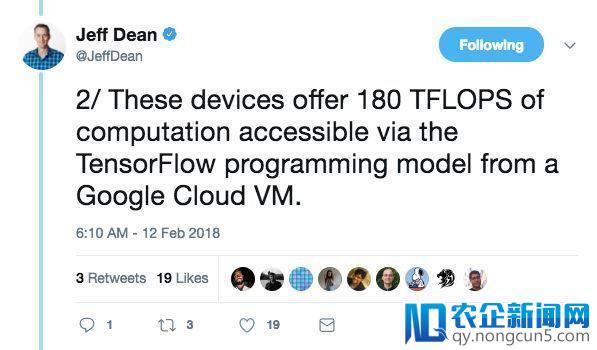
2. 经过谷歌云VM,这些安装经过TensorFlow编程模型提供180 tflops的计算才能。

3. 很多研讨员和工程师都遇到机器学习计算受限成绩,我们以为Cloud TPU将成为一个极好的处理方案。例如:一个Cloud TPU能在24小时内训练ResNet-50模型到达75%的精度。

4.拥有晚期拜访权限的用户看起来很开心。投资公司Two Sigma的CTO Alfred Spector说:“我们发现,将TensorFlow任务负载转移到TPU上,极大降低了编程新模型的复杂性,并且延长了训练工夫。”
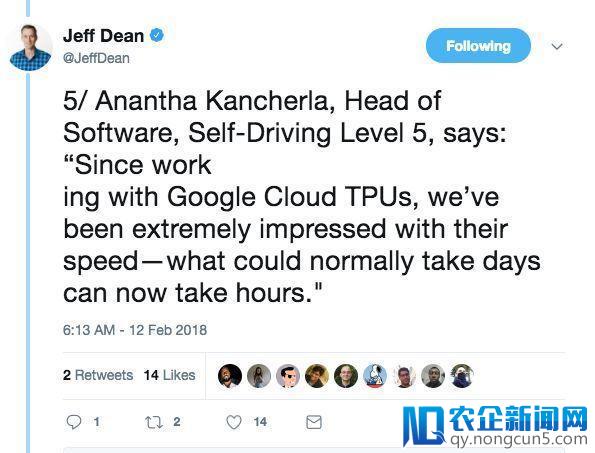
5.共享出行公司Lyft软件总监Anantha Kancherla说,“自从运用谷歌Cloud TPU,我们被它的速度惊呆了。以前需求花几天的事情,如今几小时就能完成。”

6. 如Resnet,MobileNet,DenseNet和SqueezeNet(物体分类),RetinaNet(对象检测)和Transformer(言语建模和机器翻译)等模型完成可以协助用户疾速入门:
https://github.com/tensorflow/tpu/tree/master/models/official
7、Cloud TPU最后在美国相关区域提供,价钱是每小时6.5美元。
8、你可以填表恳求Cloud TPU配额
9.《纽约时报》记者Cade Metz明天对此作了报道"Google Makes Its Special A.I. Chips Available to Others"(谷歌将其公用AI芯片普及化)
10.虽然我们已在外部运用了一段工夫,让内部用户也能用上Cloud TPU是谷歌很多人员任务的效果,包括谷歌云、数据中心、平台小组、谷歌大脑、XLA团队,和许多其他同事。
谷歌Cloud TPU测试版开放,数量无限,每小时6.5美元
即日起,Cloud TPU在谷歌云(GCP)上推出了beta版,协助机器学习专家更疾速训练和运转模型。
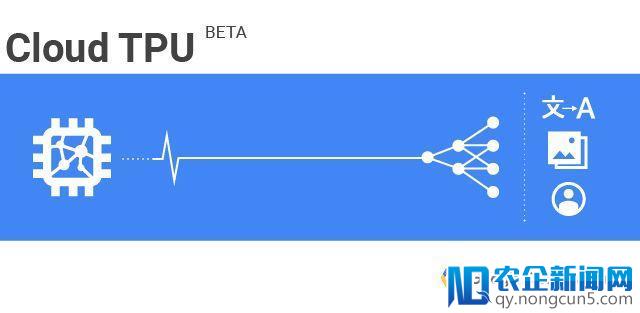
Cloud TPU是谷歌设计的硬件减速器,为减速、拓展特定tensorflow机器学习workload而优化。每个TPU里内置了四个定制ASIC,单块板卡的计算才能达每秒180 teraflops,高带宽内存有64GB。这些板卡既能独自运用,也可经过超高速公用网络衔接从而构成“TPU pod”。谷歌将于往年经过谷歌云供给这种更大的超级计算机。
-
谷歌设计Cloud TPU是为了给TensorFlow的workload提供差别化功能,并让机器学习工程师和研讨人员更疾速地停止迭代。例如:
你能经过可控制及可自定义的GoogleCompute Engine VM,对联网的Cloud TPU停止交互与专有的拜访权限,无需等候任务在共享计算集群(shared compute cluster )上排队。 - 你能在一夜之间在一组CloudTPU上训练出同一模型的若干变体,次日将训练得出最准确的模型部署到消费中,无需等几天或几周来训练关键业务机器学习模型。
- 只需求一个Cloud TPU,依据教程(https://cloud.google.com/tpu/docs/tutorials/resnet),一天之内就能在ImageNet上把ResNet-50模型训练到基准精度,本钱低于200美元。
传统上,给定制ASIC和超级计算机编程需求十分深沉的专业知识。而如今,你可以用初级TensorFlow API对Cloud TPU编程。谷歌还将一组高功能Cloud TPU模型完成停止了开源,帮您立刻上手,包括:
- ResNet-50及其他图像分类模型
- 机器翻译和言语建模的Transformer
- 物体检测的RetinaNet
Google在博客中说,经过对功能和收敛性的不时测试,这些模型都到达了规范数据集的预期精度。
当前,Google会逐步推出更多模型完成。不过,想要探险的机器学习专家也可以用他们提供的文档和工具,自行在Cloud TPU上优化其他TensorFlow模型。
如今开端用Cloud TPU,等到往年晚些时分Google推出TPU pod的时分,训练的工夫-精度比能失掉惊人的提升。
为了节省用户的工夫和精神,谷歌继续对功能和收敛性不时测试,模型都到达了规范数据集的希冀精度。
经过开展,谷歌将对更多模型完成停止开源。具有冒险肉体的机器学习专家或答应以用谷歌提供的文档和工具,本人在Cloud TPU上优化其他TensorFlow模型。
如今开端运用Cloud TPU,当谷歌在往年晚些时分推出TPU pod后,客户可以由于工夫到准确度的明显进步而取得极大的收益。正如我们在NIPS 2017上宣布的那样,ResNet-50和Transformer训练工夫在完好的TPU pod上从大半天下降到不到30分钟,无需更改代码。
投资管理公司Two Sigma的CTO Alfred Spector对谷歌Cloud TPU的功能和易用性做出了如下评价。
“我们决议把我们的深度学习研讨的重点放在云上,缘由有很多,但次要是为了取得最新的机器学习根底设备,Google Cloud TPU是支持深度学习创新、技术疾速开展的一个例子,我们发现将TensorFlow任务负荷转移到TPU上,大大降低了编程新模型的复杂性和训练工夫,从而进步了任务效率。运用Cloud TPU替代其他减速器集群,我们可以专注于构建本人的模型,不必在管理集群复杂的通讯形式上分散留意力。”
、、、、
Cloud TPU还简化了计算和管理ML计算资源:
- 为团队提供最先进的ML减速,并依据需求的变化静态调整容量(capacity)。
- 剩下设计、装置和维护具有专门的电源、散热、网络和存储要求的on-site ML计算群集所需的资金、工夫和专业知识,受害于谷歌多年来在大规模、严密集成的ML根底设备的经历。
- 无需装置驱动顺序,Cloud TPU全部预配置完成
- 享用一切Google云效劳异样复杂的平安机制和理论的维护。
共享出行公司Lyft的软件总监Anantha Kancherla表示,“自从运用Google Cloud TPU以来,我们对其速度印象十分深入,以前通常需求几天,而如今能够需求几个小时。深度学习正成为使自动驾驶车辆得以运转的软件的中坚力气。”
在Google Cloud上,谷歌希望为客户提供最合适每个机器学习任务负载的云,并将与Cloud TPU一同提供各种高功能CPU(包括Intel Skylake)和GPU(包括NVIDIA Tesla V100)。
目前,Cloud TPU的数量无限,运用费用为每小时6.50美元。
云端机器学习功能大PK,谷歌Cloud TPU或将破局
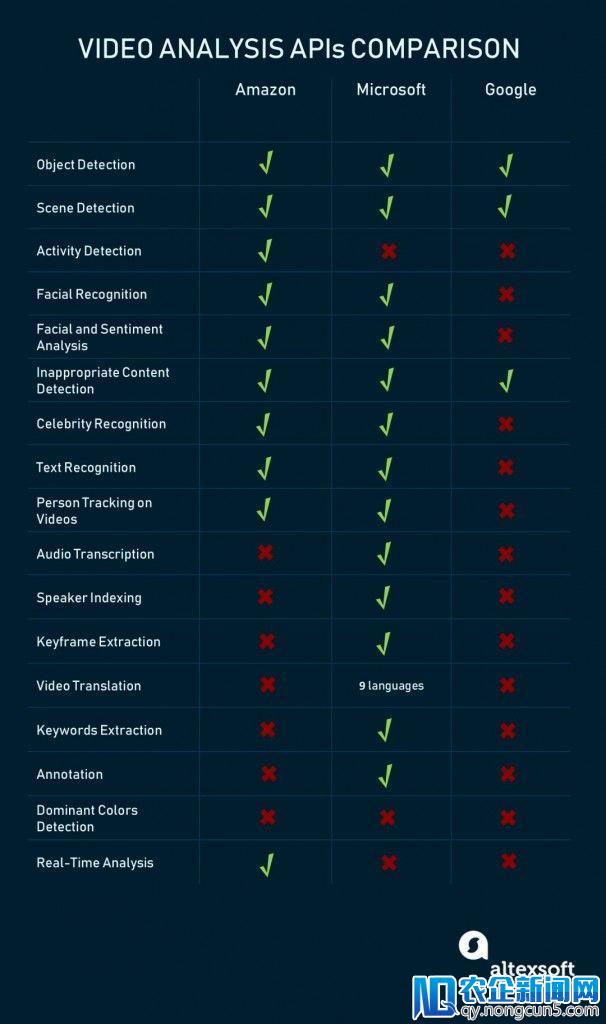
随着谷歌Cloud TPU的发布,谷歌在云端提供机器学习的效劳进一步加强。亚马逊机器学习、微软Azure机器学习和Google Cloud AI是三种抢先的机器学习即效劳(MLaaS),允许在很少或没无数据迷信专业知识的状况下停止疾速模型培训和部署。
以下是亚马逊、微软和谷歌次要机器学习即效劳平台的次要概略比照:

亚马逊机器学习效劳有两个层面:Amazon ML的预测剖析和数据迷信家的SageMaker工具。
用于预测剖析的亚马逊机器学习是市场上最自动化的处理方案之一,该效劳可以加载来自多个来源的数据,包括Amazon RDS,Amazon Redshift,CSV文件等。一切数据预处置操作都是自动执行的:该效劳标识哪些字段是分类的,哪些是数字的,并且不要求用户选择进一步数据预处置的办法(降维和白化)。
Amazon ML的预测才能限于三种选择:二元分类、多类分类和回归。也就是说,这个Amazon ML效劳不支持任何无监视的学习办法,用户必需选择一个目的变量在训练集中标志它。并且,用户不需求晓得任何机器学习办法,由于亚马逊在检查提供的数据后自动选择它们。
这种高度自动化程度既是亚马逊ML运用的优势也是优势。假如您需求全自动但无限的处理方案,该效劳可以满足您的希冀。假如没有,那就是SageMaker工具。
亚马逊SageMaker和基于框架的效劳:
SageMaker是一个机器学习环境,经过提供疾速建模和部署工具来简化同行数据迷信家的任务。例如,它提供了Jupyter(一款创作笔记本),用于简化数据阅读和剖析,而无需效劳器管理。亚马逊还有内置算法,针对散布式零碎中的大型数据集和计算停止了优化。
假如不想运用这些功用,则可以经过SageMaker应用其部署功用添加本人的办法并运转模型。或许可以将SageMaker与TensorFlow和MXNet深度学习库集成。
通常,亚马逊机器学习效劳为经历丰厚的数据迷信家和那些只需求完成任务而不深化数据集预备和建模的人提供足够的自在。关于那些曾经运用亚马逊环境并且不计划转移到另一家云提供商的公司来说,这将是一个不错的选择。
Microsoft Azure机器学习:
Azure机器学习的目的是为老手和经历丰厚的数据迷信家树立一个弱小的场景。微软的ML产品名单与亚马逊的产品类似,但就如今而言,Azure在现成算法方面似乎更为灵敏。
ML Studio是次要的MLaaS包。简直Azure ML Studio中的一切操作都必需手动完成。这包括数据探究、预处置、选择办法和验证建模后果。
运用Azure完成机器学习需求一些学习曲线。另一方面,Azure ML支持图形界面以可视化任务流程中的每个步骤。也许运用Azure的次要益处是可以运用各种算法。 Studio支持大约100种处理分类(二元+多分类)、异常检测、回归、引荐和文本剖析的办法。值得一提的是,该平台有一个聚类算法(K-means)。
Azure ML的另一大局部是Cortana Intelligence Gallery。它是由社区提供的机器学习处理方案的集合,供数据迷信家探究和重用。 Azure产品是从机器学习动手并将其功用引入新员工的弱小工具。
Google预测API
数据迷信家的机器学习引擎和高度自动化的Google预测API。不幸的是,谷歌预测API最近已被弃用,谷歌将在2018年4月30日取消插件。
Predicion API相似于Amazon ML。它的繁复办法减少到处理两个次要成绩:分类(二元和多类)和回归。训练好的模型可以经过REST API接口停止部署。
谷歌没有发布哪些算法被用于绘制预测,也没有让工程师自定义模型。另一方面,Google的环境最合适在紧迫的期限内停止机器学习,并且晚期推出ML方案。但是这个产品似乎并没有Google所希冀的那么受欢送,运用Prediction API的用户将不得不运用其他平台来“重新创立现有模型”。
预测API的高度自动化是以灵敏性为代价的。Google ML Engine正好相反。它投合了经历丰厚的数据迷信家,并建议运用TensorFlow的云根底设备作为机器学习驱动顺序。因而,ML Engine准绳上与SageMaker十分类似。
TensorFlow是另一个Google产品,它是一个开源的机器学习库,包括各种数据迷信工具,而不是ML-as-a-service。它没有可视化界面,TensorFlow的学习曲线会十分峻峭。
似乎Azure目前在MLaaS市场上拥有功用最多的工具集。它涵盖了大少数与ML相关的义务,为构建自定义模型提供了一个可视化界面,并且为那些不想用裸手掌握数据迷信的人提供了一组牢靠的API。但是,它依然缺乏亚马逊的自动化才能。
除了成熟的平台之外,开发者还可以运用初级API。 这些都是在训练有素的模型下的效劳,API不需求机器学习专业知识。 目前,这三家厂商的API大致可分为三大类:
1)文本辨认,翻译和文本剖析
2)图像+视频辨认和相关剖析
3)其他,包括特定的未分类效劳
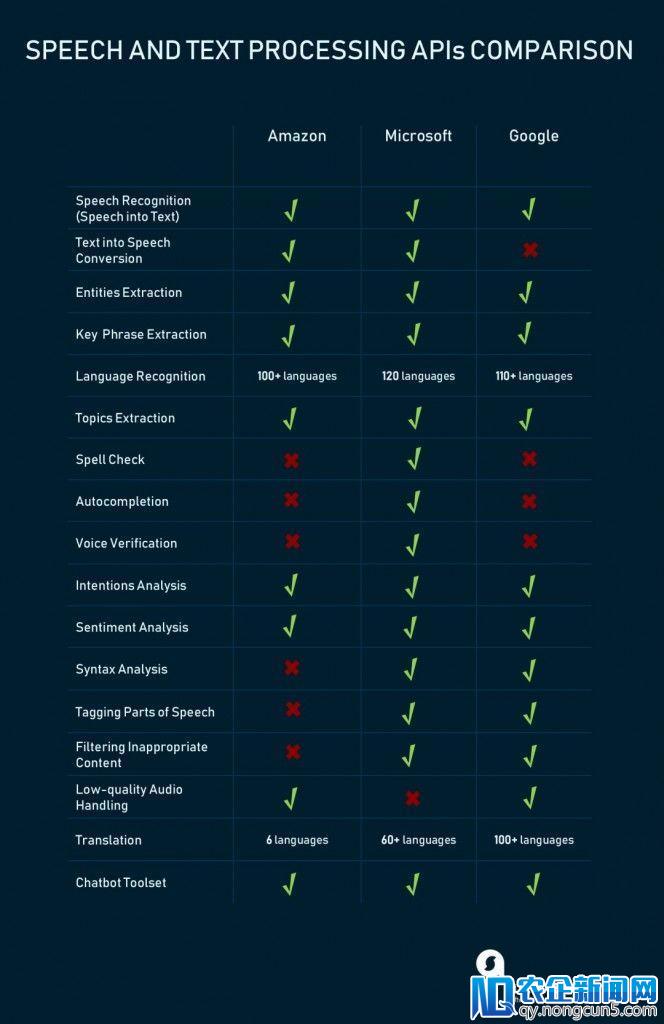
除了文字和语音外,亚马逊、微软和谷歌还提供用于图像和视频剖析的通用API。
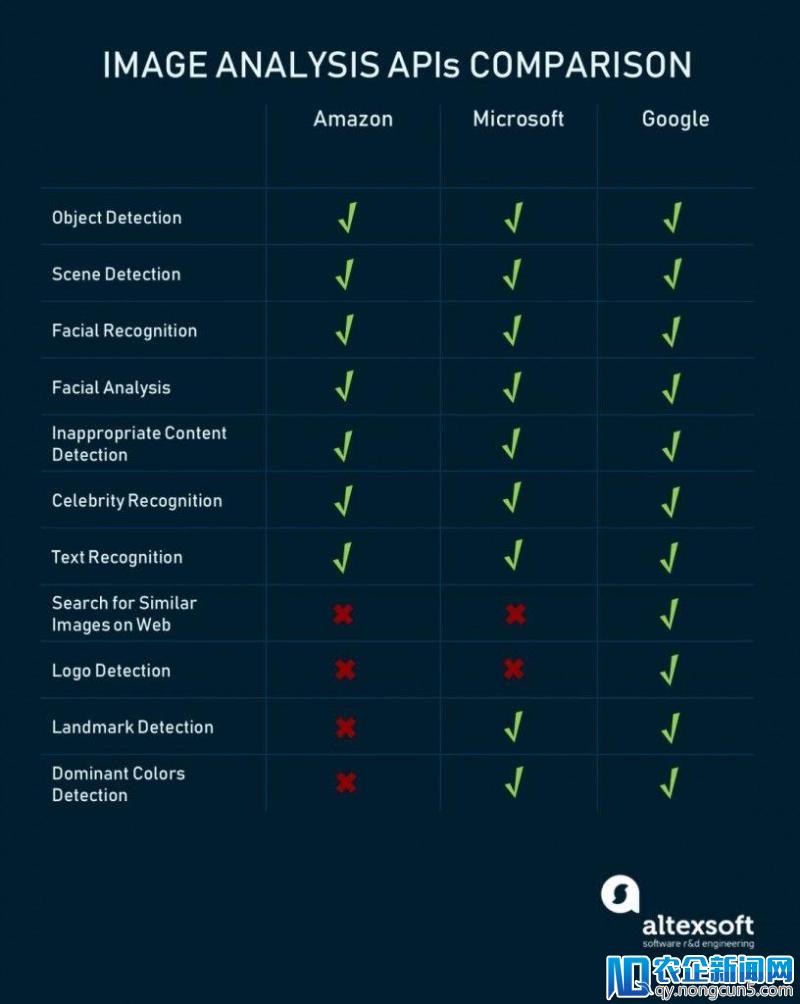
虽然图像剖析与视频API亲密相关,但许多视频剖析工具仍在开发或测随着中国经济向消费型模式的转型, 电子商务和移动电子商务的快速发展带来了支付行业强劲的增长。试版本中。 例如,Google建议对各种图像处置义务提供丰厚的支持,但相对缺乏微软和亚马逊曾经提供的视频剖析功用。