

雷锋网AI科技评论音讯,Facebook AI 研讨院于近日开源了 C++ 库及数学言语 Tensor Comprehensions,它能无效填补研讨人员于数学运算范畴的沟通鸿沟,并基于各种硬件后端上大规模运转工程模型。它的最大亮点在于,它采用了 Just-In-Time 的编译自动生成机器学习社区所需的高功能代码。
也就是说,经过 Tensor Comprehensions,研讨人员可以以数学符号的方式停止编写,零碎可以依据需求停止编译调整,并输入专业的代码。
数量级增长
传统意义上,假如要从零发明一个具有高功能表现的机器学习层需求两个大步骤,这能够需求消耗工程师数天甚至数周的努力。
1. 在 NumPy 层级,研讨人员需求写一个全新层,并在以 PyTorch 为代表的深度学习库中链接已有运算,然后停止小规模测试。假如要运转大规模实验,需求经过数量级减速检测其代码完成。
2. 工程师随后采用这个层,并为 GPU 和 CPU 撰写无效代码(但这需求满足多个条件):
1)工程师需求是一位在高功能计算颇有理解的专家,但这一人才目前十分稀缺;
2)文本、战略、写代码,debug,工程师需求样样通晓;
3)将代码与实践义务相关的后端相衔接,如冗长的参数反省和添加样板集成代码
这也直接招致近年来深度学习社区不断依赖以 CuBLAS, MKL, 和 CuDNN 为代表的高功能库而构建运转于 GPU 和 CPU 的代码。关于研讨员而言,如何寻觅一条新的完成思绪成为了宏大应战。
而在 Tensor Comprehensions 中,研讨员们得以将这一流程从几天甚至几周增加到数分钟。这一开源包括了:
• 用复杂语法表达一系列机器学习概念的数学符号
• 基于 Halide IR 数学符号的 C ++前端
• 基于整数集库(ISL)的 Just-in-Time 编译器,
• 一个基于退化搜索的多线程、多 GPU 自动调理器
晚期任务
Halide 是一种最近在高功能图像处置范畴颇受欢送的言语,它采用相似的初级函数语法来描绘一个图像处置的 pipeline,随后在独自代码块中调度到硬件上,并且详细到如何平铺、矢量化、并行化和交融。关于具有专业知识的人而言,这是一种十分高效的言语;但关于机器学习从业者来说,这一难度并不小。Halide 的自动调度在研讨上十分活泼,但关于 GPU 上运转的机器学习代码,目前还没有很好的处理方案。
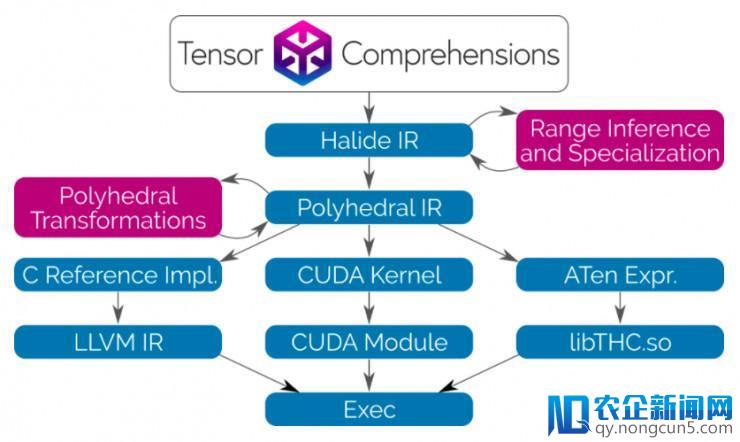
Tensor Comprehension 将 Halide 编译器作为调用库。FAIR 研讨员构建了 Halide 的两头表征(IR)和剖析工具,并与多面编译停止技术配对,因而,用户可以在无需了解运转原理的条件下运用类似的初级语法编写层。此外,FAIR 研讨员也找到了简化言语的办法,不需求为缩减运算制定循环边界。
细节完成

运用 Halide 和多面编译技术,Tensor Comprehensions 能经过委托内存管理和同步功用以自动分解 CUDA 内核。这一编译可以针对特定尺寸对普通操作符停止交融,对疾速本地内存、疾速缩减和 Just-in-Time 专业化都能优化。因不尝试涉足内存管理,因而这一流程可以轻松集成到机器学习的恣意框架,以及任何允许调用 C++ 函数的言语中。
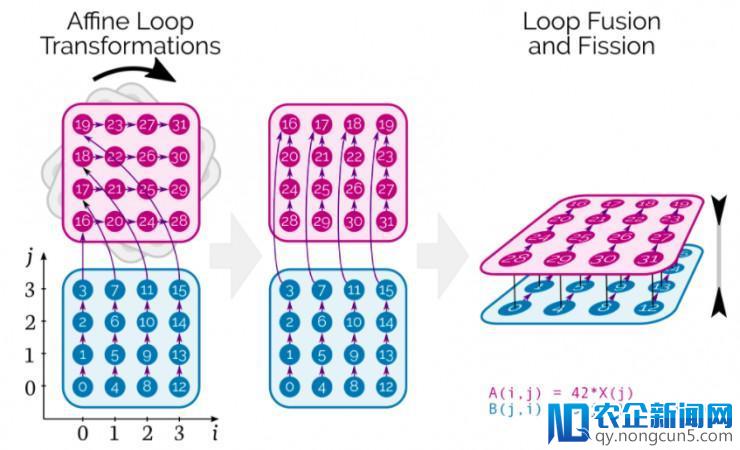
与经典编译器技术和库办法相反的是,多面编译能让张量了解为每个新网络按需调度单个张量元素的计算。
在 CUDA 层面,它结合了仿射循环转换、交融/分裂和自动并行处置,同时确保数据在存储器层次构造中正确挪动。
本着网络面前人人平等的原则,提倡所有人共同协作,编写一部完整而完善的百科全书,让知识在一定的技术规则和文化脉络下得以不断组合和拓展。图中数字表示最后计算张量元素的顺序,箭头表示它们之间的依赖关系。在这个例子中,数字旋转对应于循环交流,可以完成深度操作器的交融。
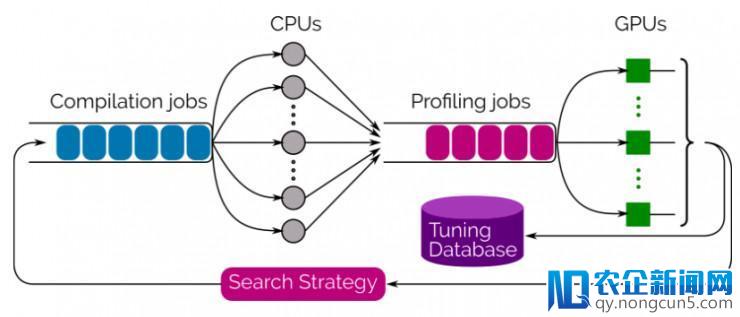
研讨员提供了一个集成的多线程、多 GPU 自动调理库,以推进搜索进程,它运用 Evolutionary Search 来生成和评价数千种完成方案,并选择功能最佳的方案。只需调用 Tensor Comprehension 上的 tune 功用,用户便能目击功能的改善。最好的战略是经过 protobuf 序列化,在当下或离线状况下可重用。
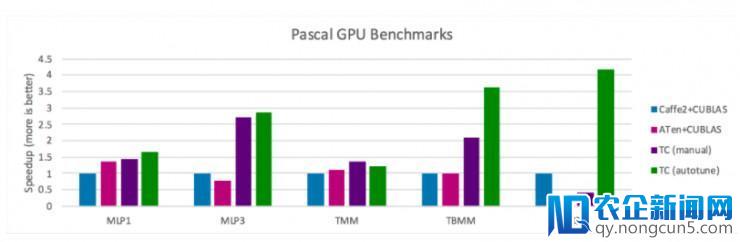
在功能方面,Tensor Comprehensions 能够依然有很大提升空间,但在条件满足的状况下,它曾经可以婚配或打破以后机器学习框架与手动调整库集成的功能,并经过将代码生成战略顺应特定成绩大小的才能来完成。下图展示了 Tensor Comprehensions 与 Caffe2 和 ATen 的比照。
 聚焦消费升级、多维视频、家庭场景、数字营销、新零售等创新领域,为用户提供更多元、更前沿、更贴心的产品,满足用户日益多样化、个性化的需求。
聚焦消费升级、多维视频、家庭场景、数字营销、新零售等创新领域,为用户提供更多元、更前沿、更贴心的产品,满足用户日益多样化、个性化的需求。
更多信息请参考 arXiv 论文(链接见底部)。
将来,Tensor Comprehensions 将补充硬件制造商(如 NVIDIA 和 Intel)编写的疾速库,并将与 CUDNN,MKL 或 NNPack 等库一同运用。
下一步
雷锋网AI科技评论理解到,该版本的开源库能让研讨人员和顺序员运用与他们在论文中运用的数学类似标志来编写层,并简明地传达顺序意图。他们也可以在几分钟内将这种表示办法停止编译。将来随着工具链的不时增长,FAIR 以为它的估计可用性和功能将会提升,并受害整个社区。
晚些工夫,FAIR 将会发布 PyTorch 集成的 Tensor Comprehensions。
GitHub 链接: https://facebookresearch.github.io/TensorComprehensions/
arXiv 论文: https://arxiv.org/abs/1802.04730
Slack 页面: https://tensorcomprehensions.herokuapp.com/
Email: tensorcomp@fb.com
雷锋网 (大众号:雷锋网) AI科技评论编译
雷锋网版权文章,未经受权制止转载。概况见。
