
雷锋网 (大众号:雷锋网) 随着中国经济向消费型模式的转型, 电子商务和移动电子商务的快速发展带来了支付行业强劲的增长。 AI 科技评论按:在神经网络的成功的带动下,越来越多的研讨人员和开发人员都开端重新审视机器学习,开端尝试用某些机器学习办法自动处理可以轻松采集数据的成绩。但是,在众多的机器学习算法中,哪些是又上手快捷又功用弱小、合适老手学习的呢?Towards Data Science 上一篇文章就引见了十种老手必看的机器学习算法,雷锋网 AI 科技评论全文编译如下。

机器学习范畴有一条“没有收费的午餐”定理。复杂解释下的话,它是说没有任何一种算法可以适用于一切成绩,特别是在监视学习中。
例如,你不能说神经网络就一定比决策树好,反之亦然。要判别算法优劣,数据集的大小和构造等众多要素都至关重要。所以,你应该针对你的成绩尝试不同的算法。然后运用保存的测试集对功能停止评价,选出较好的算法。
当然,算法必需合适于你的成绩。就比方说,假如你想打扫你的房子,你需求吸尘器,扫帚,拖把。而不是拿起铲子去开端挖地。
大的准绳
不过,关于预测建模来说,有一条通用的准绳适用于一切监视学习算法。
机器学习算法可以描绘为学习一个目的函数 f,它可以最好地映射出输出变量 X 到输入变量 Y。有一类普遍的学习义务。我们要依据输出变量 X 来预测出 Y。我们不晓得目的函数 f 是什么样的。假如早就晓得,我们就可以直接运用它,而不需求再经过机器学习算法从数据中停止学习了。
最罕见的机器学习就是学习 Y=f(X) 的映射,针对新的 X 预测 Y。这叫做预测建模或预测剖析。我们的目的就是让预测愈加准确。
针对希望对机器学习有个根本理解的新人来说,上面将引见数据迷信家们最常运用的 10 种机器学习算法。
1. 线性回归
线性回归能够是统计和机器学习范畴最广为人知的算法之一。
以牺牲可解释性为代价,预测建模的首要目的是减小模型误差或将预测精度做到最佳。我们从统计等不同范畴自创了多种算法,来到达这个目的。
线性回归经过找到一组特定的权值,称为系数 B。经过最能契合输出变量 x 到输入变量 y 关系的等式所代表的线表达出来。
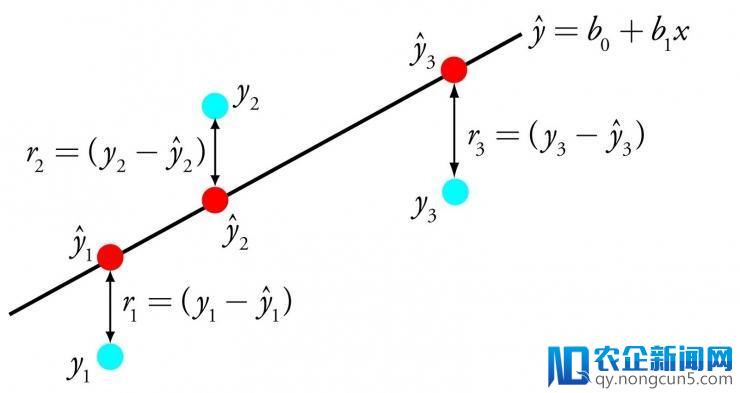
线性回归
例如:y = B0 + B1 * x 。我们针对给出的输出 x 来预测 y。线性回归学习算法的目的是找到 B0 和 B1 的值。
不同的技巧可以用于线性回归模型。比方线性代数的普通最小二乘法,以及梯度下降优化算法。线性回归曾经有超越 200 年的历史,曾经被普遍地研讨。依据经历,这种算法可以很好地消弭类似的数据,以及去除数据中的噪声。它是疾速且简便的首选算法。
2. 逻辑回归
逻辑回归是另一种从统计范畴自创而来的机器学习算法。
与线性回归相反。它的目的是找出每个输出变量的对应参数值。不同的是,预测输入所用的变换是一个被称作 logistic 函数的非线性函数。
logistic 函数像一个大 S。它将一切值转换为 0 到 1 之间的数。这很有用,我们可以依据一些规则将 logistic 函数的输入转换为 0 或 1(比方,当小于 0.5 时则为 1)。然后以此停止分类。
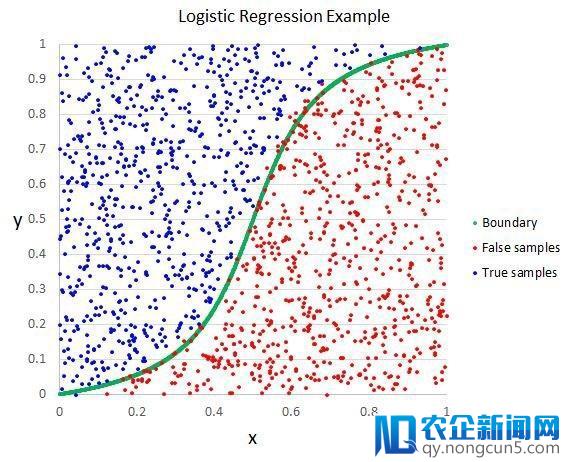
逻辑回归
正是由于模型学习的这种方式,逻辑回归做出的预测可以被当做输出为 0 和 1 两个分类数据的概率值。这在一些需求给出预测合感性的成绩中十分有用。
就像线性回归,在需求移除与输入变量有关的特征以及类似特征方面,逻辑回归可以表现得很好。在处置二分类成绩上,它是一个疾速高效的模型。
3. 线性判别剖析
逻辑回归是一个二分类成绩的传统分类算法。假如需求停止更多的分类,线性判别剖析算法(LDA)是一个更好的线性分类办法。
对 LDA 的解释十分直接。它包括针对每一个类的输出数据的统计特性。关于单一输出变量来说包括:
-
类内样本均值
-
总体样本变量
线性判别剖析
经过计算每个类的判别值,并依据最大值来停止预测。这种办法假定数据听从高斯散布(钟形曲线)。所以它可以较好地提早去除离群值。它是针对分类模型预测成绩的一种复杂无效的办法。
4. 分类与回归树剖析
决策树是机器学习预测建模的一类重要算法。
可以用二叉树来解释决策树模型。这是依据算法和数据构造树立的二叉树,这并不难了解。每个节点代表一个输出变量以及变量的分叉点(假定是数值变量)
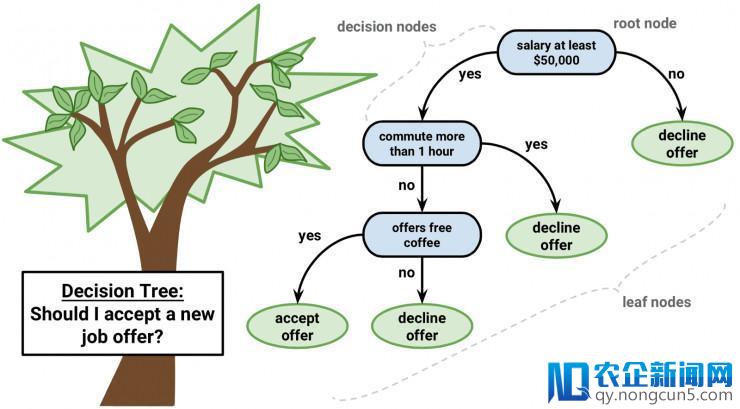
决策树
树的叶节点包括用于预测的输入变量 y。经过树的各分支抵达叶节点,并输入对应叶节点的分类值。
树可以停止疾速的学习和预测。通常并不需求对数据做特殊的处置,就可以运用这个办法对多种成绩失掉精确的后果。
5. 朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一个复杂,但是异常弱小的预测建模算法。
这个模型包括两种概率。它们可以经过训练数据直接计算失掉:1)每个类的概率;2)给定 x 值状况下每个类的条件概率。依据贝叶斯定理,一旦完成计算,就可以运用概率模型针对新的数据停止预测。当你的数据为实数时,通常假定听从高斯散布(钟形曲线)。这样你可以很容易地预测这些概率。
贝叶斯定理
之所以被称作朴素贝叶斯,是由于我们假定每个输出变量都是独立的。这是一个强假定,在真实数据中简直是不能够的。但关于很多复杂成绩,这种办法十分无效。
6. K 最近邻算法
K 最近邻算法(KNN)是一个十分复杂无效的算法。KNN 的模型表示就是整个训练数据集。很复杂吧?
关于新数据点的预测则是,寻觅整个训练集中 K 个最类似的样本(邻居),并把这些样本的输入变量停止总结。关于回归成绩能够意味着均匀输入变量。关于分类成绩则能够意味着类值的众数(最常呈现的那个值)。
窍门是如何在数据样本中找出类似性。最复杂的办法就是,假如你的特征都是以相反的尺度(比方说都是英寸)度量的,你就可以直接计算它们相互之间的欧式间隔。
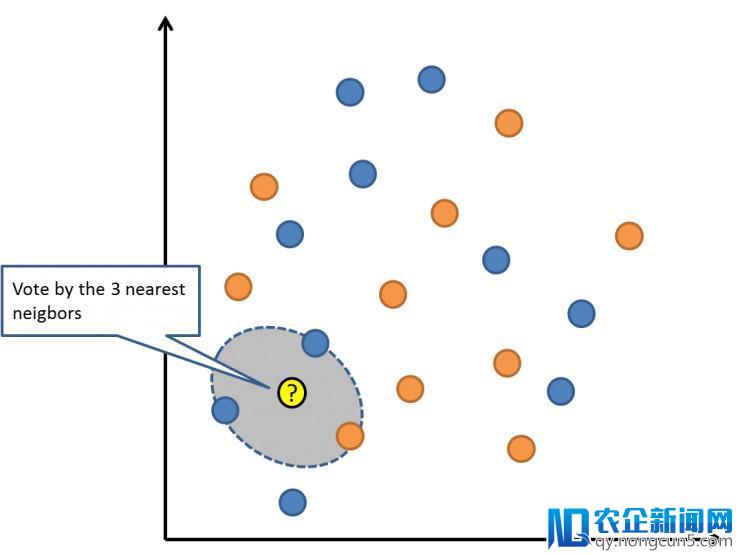
K 最近邻算法
KNN 需求少量空间来存储一切的数据。但只是在需求停止预测的时分才开端计算(学习)。你可以随时更新并组织训练样本以保证预测的精确性。
在维数很高(很多输出变量)的状况下,这种经过间隔或相远程度停止判别的办法能够失败。这会对算法的功能发生负面的影响。这被称作维度灾难。我建议你只要当输出变量与输入预测变量最具有关联性的时分运用这种算法。
7. 学习矢量量化
K 最近邻算法的缺陷是你需求存储一切训练数据集。而学习矢量量化(缩写为 LVQ)是一团体工神经网络算法。它允许你选择需求保存的训练样本个数,并且学习这些样本看起来应该具有何种形式。
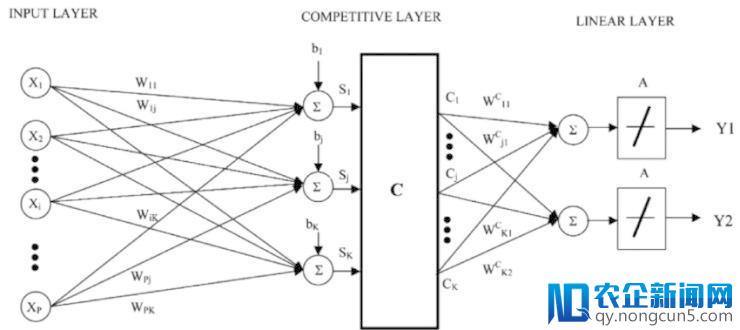
学习矢量量化
LVQ 可以表示为一组码本向量的集合。在开端的时分停止随机选择。经过多轮学习算法的迭代,最初失掉与训练数据集最相配的后果。经过学习,码本向量可以像 K 最近邻算法那样停止预测。经过计算新数据样本与码本向量之间的间隔找到最类似的邻居(最契合码本向量)。将最佳的分类值(或回归成绩中的实数值)前往作为预测值。假如你将数据调整到相反的尺度,比方 0 和 1,则可以失掉最好的后果。
假如你发现关于你的数据集,KNN 有较好的效果,可以尝试一下 LVQ 来增加存储整个数据集对存储空间的依赖。
8. 支持向量机
支持向量机(SVM)能够是最常用并且最常被谈到的机器学习算法。
超立体是一条划分输出变量空间的线。在 SVM 中,选择一个超立体,它能最好地将输出变量空间划分为不同的类,要么是 0,要么是 1。在 2 维状况下,可以将它看做一根线,并假定一切输出点都被这根线完全分开。SVM 经过学习算法,找到最能完成类划分的超立体的一组参数。
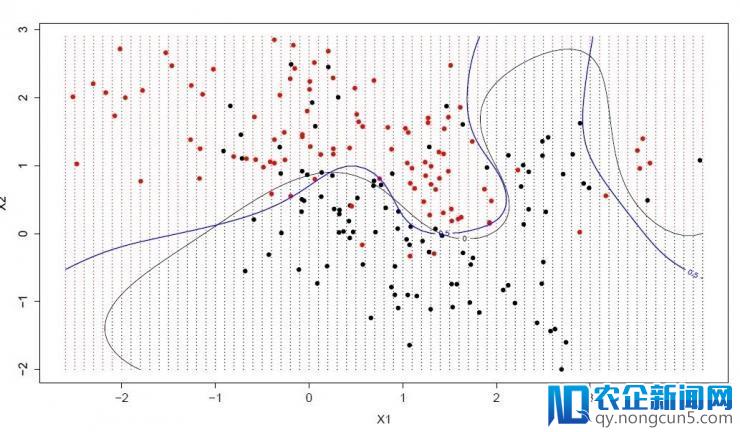
支持向量机
超立体和最接近的数据点的间隔看做一个差值。最好的超立体可以把一切数据划分为两个类,并且这个差值最大。只要这些点与超立体的定义和分类器的结构有关。这些点被称作支持向量。是它们定义了超立体。在实践运用中,优化算法被用于找到一组参数值使差值到达最大。
SVM 能够是一种最为弱小的分类器,它值得你一试。
9. Bagging 和随机森林
随机森林是一个常用并且最为弱小的机器学习算法。它是一种集成机器学习算法,称作自举会聚或 bagging。
bootstrap 是一种弱小的统计办法,用于数据样本的预算。比方均值。你从数据中采集很多样本,计算均值,然后将一切均值再求均匀。最终失掉一个真实均值的较好的估量值。
在 bagging 中用了类似的办法。但是通常用决策树来替代对整个统计模型的估量。从训练集中采集多个样本,针对每个样本结构模型。当你需求对新的数据停止预测,每个模型做一次预测,然后把预测值做均匀失掉真实输入的较好的预测值。
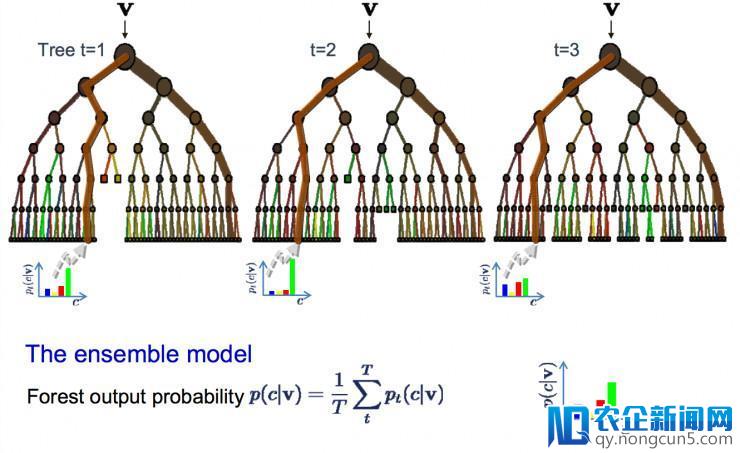
随机森林
这里的不同在于在什么中央创立树,与决策树选择最优分叉点不同,随机森林经过参加随机性从而发生次优的分叉点。
每个数据样本所创立的模型与其他的都不相反。但在独一性和不异性方面依然精确。结合这些预测后果可以更好地失掉真实的输入估量值。
假如在高方差的算法(比方决策树)中失掉较好的后果,你通常也可以经过袋装这种算法失掉更好的后果。
10. Boosting 和 AdaBoost
Boosting 是一种集成办法,经过多种弱分类器创立一种强分类器。它首先经过训练数据树立一个模型,然后再树立第二个模型来修正前一个模型的误差。在完成对训练集完满预测之前,模型和模型的最大数量都会不时添加。
AdaBoost 是第一种成功的针对二分类的 boosting 算法。它是了解 boosting 的最好的终点。古代的 boosting 办法是树立在 AdaBoost 之上。少数都是随机梯度 boosting 机器。
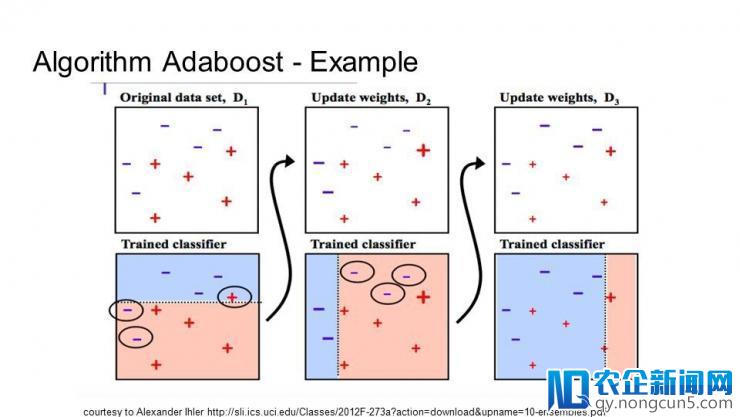
AdaBoost
AdaBoost 与短决策树一同运用。当第一棵树创立之后,每个训练样本的树的功能将用于决议,针对这个训练样本下一棵树将给与多少关注。难于预测的训练数据给予较大的权值,反之容易预测的样本给予较小的权值。模型按顺序被树立,每个训练样本权值的更新都会影响下一棵树的学习效果。完成决策树的树立之后,停止对新数据的预测,训练数据的准确性决议了每棵树的功能。
由于重点关注修正算法的错误,所以移除数据中的离群值十分重要。
结语
当面对各种机器学习算法,一个老手最常问的成绩是「我该运用哪个算法」。要答复这个成绩需求思索很多要素:(1)数据的大小,质量和类型;(2)完成计算所需求的工夫;(3)义务的紧迫水平;(4)你需求对数据做什么处置。
在尝试不同算法之前,就算一个经历丰厚的数据迷信家也不能够通知你哪种算法功能最好。虽然还有很多其他的机器学习算法,但这里罗列的是最常用的几种。假如你是一个机器学习的老手,这几种是最好的学习终点。
via towardsdatascience.com ,雷锋网 AI 科技评论编译
。
