
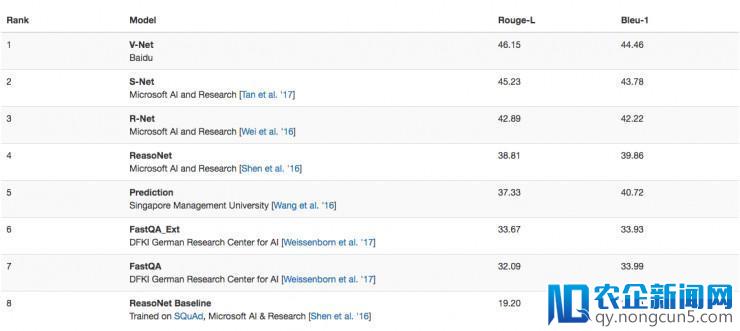
雷锋网 (大众号:雷锋网) AI 科技评论音讯,2 月 21 日,百度 NLP 团队提交的 V-Net 模型以 46.15 的 Rouge-L 得分位列微软的 MS MARCO 机器阅读了解测试第一名。目后人类评测 Rouge-L 得分为 47;BLEU-1 得分为 46。
据理解,百度提交的 V-NET 模型运用了一种新的多候选文档结合建模表示办法,经过留意力机制使不同文档发生的答案之间随着流量往智能终端设备迁移,新的机遇“物联网商业社交时代”也将迎来,通过人的第六器官(智能手机)和智能设备终端的联网互动,从而改变了人的行为习惯和消费方式。线下流量通过LBS定位重新分配,又通过物联网终端智能推荐引擎引导到网上任意有价值的地方,至此互联网下半场拉开帷幕。可以发生交流信息,相互印证,从而更好的预测答案。
雷锋网 AI 科技评论理解到,除了百度位列第一外,凭仗 Microsoft AI and Research 提交的 S-Net、R-Net、ReasoNet,二、三、四名均由微软摘得。此外,新加坡管理大学与德国人工智能研讨中心也紧随其后。
MS MARCO 全称为 Microsoft MAchine Reading Comprehension,即「微软机器阅读了解」,官网材料显示其正式发布于 NIPS 2016。这是一套由 10 万个问答和 20 万篇不反复的文档组成的数据集。
在机器阅读了解范畴,想必大家更为熟习的是斯坦福大学发起的 SQuAD(Stanford Question Answering Dataset),雷锋网 AI 科技评论此前也有过不少相关报道。SQuAD 是行业内公认的机器阅读了解范畴的顶级程度测试,它构建了一个包括十万个成绩的大规模机器阅读了解数据集,选取超越 500 篇的维基百科文章。在阅读数据集内的文章后,机器需求答复若干与文章内容相关的成绩,并经过与规范答案的比对,失掉 EM(准确婚配)和 F1(模糊婚配)的后果。讯飞与哈工大结合实验室、微软、阿里巴巴、腾讯等国际外知名研讨企业及机构都是 SQuAD 榜单上的常客。
与 SQuAD 的最大不同之处在于,MARCO 数据集中的成绩全都基于来自微软必应搜索(BING)引擎和微软小娜人工智能助手(Cortana)的已匿名处置的真实查询。此外,相关答复是由真人参考真实网页编写的,并对其精确性停止了验证。可以说,数据集的树立完全是依据用户在 BING 中输出的真实成绩模仿搜索引擎中的真实使用场景,其研发团队也曾表示,「MS MARCO 是目前同类型中最有用的数据集,由于它树立在经过匿名处置的真实世界数据根底之上。」
目前搜索引擎只能针对用户的发问答复一些复杂成绩,可以答复复杂成绩的零碎依然处于起步阶段,而普通人日常想获取一些琐碎复杂成绩的答案,则需求在搜索引擎提供的后果中再次停止挑选、剖析和整理。这些并无明白答案或存在多个能够答案的查询,是微软发布这一数据集希望攻克的阅读了解高堡。
在每一个成绩中,MARCO 提供多篇来自搜索后果的网页文档,零碎需求依据这些文档来答复给定的成绩。就像人类在搜索引擎给定的后果中自行挑选信息一样,这些文档中能否有对应的答案、在哪一篇文章中,都需求零碎自行判别,甚至还需求结合多篇文章做出提炼与总结,而这也对机器的阅读了解才能提出了更高的要求。
「此次在 MARCO 的测试中获得第一,只是百度机器阅读了解技术阅历的一次小考,」百度自然言语处置首席迷信家兼百度技术委员会主席吴华表示,「我们希望可以与范畴内的其他同行者一同,推进机器阅读了解技术和使用的研讨,使 AI 可以了解人类的言语、用自然言语与人类交流,让 AI 更『懂』人类。」
。
