
置信每个小同伴都阅历过训练算法时在电脑前默默苦等的日子,看着损失像乌龟一样一点点的减小。很多时分不由在想,训练网络怎样会这么久啊!这篇文章的作者从优化的角度道出了神经网络训练耗时的本源,并论述了减小非线性优化成绩串行复杂度的一系列妨碍。
在八十年代的时分,训练卷积神经网络停止手写数字辨认的任务需求耗时一周甚至更长工夫,明天顶级会议对论文算法停止评价的训练数据ImageNet也需求在单卡高端GPU上停止一周左右的训练工夫。人们为了不时进步算法的功能,不时榨取硬件的计算才能并将训练工夫不时延伸。谷歌的工程师甚至应用10PFlop的TPU来停止MINST手写字符辨认算法的训练,人们总是会找到方法穷尽硬件一切的算力来训练更高的算法,这也意味着更长的工夫。
但是招致神经网络训练工夫低落的本源却值得我们细心的考虑,让我们先来看看上面这段代码:

下面这个优化进程看似复杂,但即便随着晶体管的数量指数级上升、假如你需求串行运转300万个循环,很多晶体管也只能袖手旁观你的训练速度只会局限在单线程的程度,而单线程的计算才能这些年却没有明显的添加。
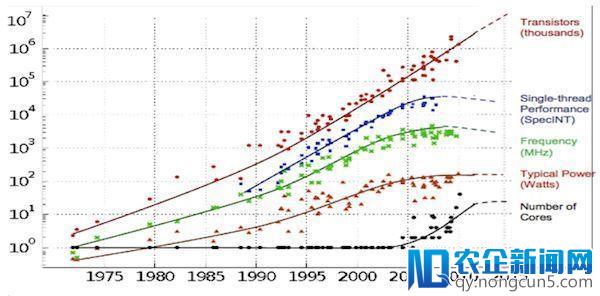
从图中我们可以看出,串行计算才能的峰值在2007年到达高峰随后下降,作者发现三年的老笔记本上训练Atari强化学习模型比在新的因特尔至强芯片上还快。
为了处置单线程越来越差的表现人们开端着力于增加优化迭代的次数,但循环次数却受以下三方面缘由的制约。
一、非线性
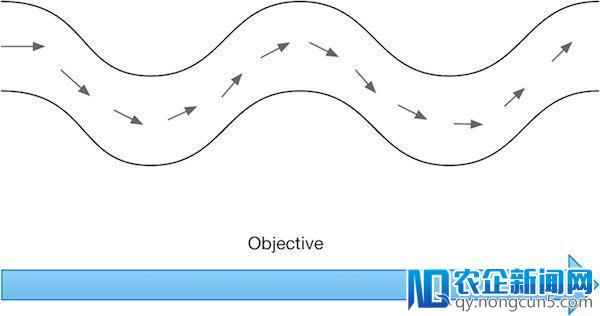
假如我们的优化成绩如下图所示,由于梯度下降法依赖部分信息,需求一定的迭代次数才干够寻觅到局域最小值。
非线性可由目的函数组成局部之间的互相作用表示出来,神经网络中的层数越多其非线性表示才能就越强。
让我们来看一个例子,将一系列的随机举证相乘并用恣意的输出ab来归一化后果:
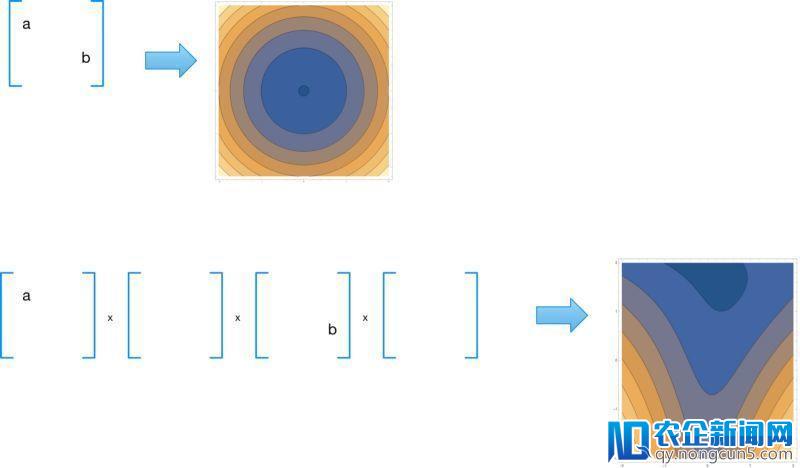
我们看到即便对这样地道的线性神经网络,层数变多了优化也演化成非线性成绩。
所以我们失掉结论,层数越多的神经网络非线性就越强:
二、部分条件数(输出敏理性)
让我们来思索一个形如椭圆方程的最小化成绩:
这一成绩的难点在于梯度并不指向最小值的方向,梯度下降法在运用进程中会构成“之”字形轨迹:
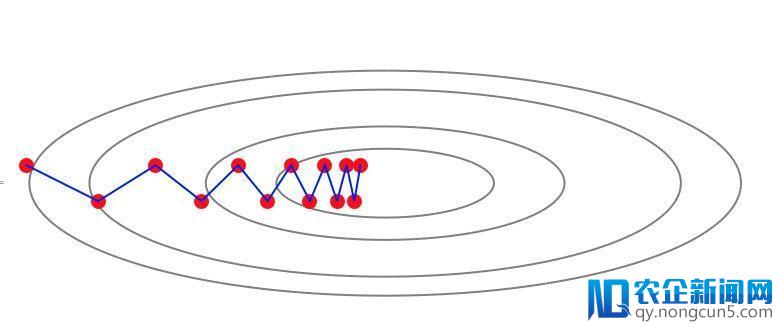
为了权衡梯度下降法关于这类成绩的处置难度,人们提出了一个成为“条件数”的目标来权衡,它定义为梯度成绩中最长轴和最短轴的比值,随着条件数的添加,需求优化的步数也线性添加。
下图辨别是条件数为1和10 的状况:

神经网络的优化为题形成了很差的条件数,参数越多使得条件数越差,需求的优化步骤也越多。详细内容可以参照文末论文1。
三、梯度乐音的水平
神经网络运用的优化算法是梯度下降法,随机梯度下降法由于条件数的缘由得不到精确的下降方向,然后又被乐音不时浓缩形成了很大的影响!
下图数乐音关于Rosenbrock方程最小值的优化进程影响:
没噪声

有噪声
噪声的添加源于参数空间不时添加的维度,最复杂的状况下可以视为高斯噪声,均方根误差随着维度的平方根而添加。详细请看文末参考误差。
关于这种方式的成绩,我们可以运用不时添加的三极管数量来并行计算并最终求取均匀值,而且误差随着样本数量的添加是可以减少的:
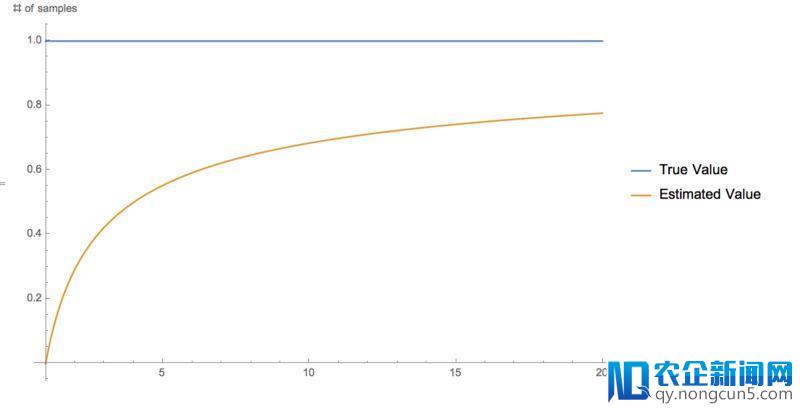
基于乐音和均值公式的平方根我们发现为了防止额定的噪声我们需求在坚持参数不变的状况下增大每一次batch的数量。总结来说就是越多参数越多乐音,但是关于并行计算来说,越大的batch越多样本的均匀则乐音也就越小。
总 结
关于这三种拉低神经网络训练速度的妨碍提出了不同的处理方法,关于第一种我们要减小非线性,应用Resnet和ReLU激活函数是其中一种先进的办法为数亿中文用户免费提供海量、全面、及时的百科信息,并通过全新的维基平台不断改善用户对信息的创作、获取和共享方式。;关于第二个妨碍我们需求对神经网络采取先进的线性估量办法如KFAC;关于第三种妨碍,可以采用更多的计算设备集成来克制。同时下一代针对深度学习更为高效的晶体管可以同时改善这三个方面。