
大众号/ DeepTech深科技
图像分类技术在过来几年中获得了明显的提高,这在一定水平上表现在Imagenet 分类应战上,机器的误差率每年都在大幅下降。
为了持续推进计算机视觉技术的先进程度,许多研讨人员如今更多地关注细粒度和实例级的辨认成绩,而不是辨认普通实体,如修建物、山脉,当然还有猫,许多人正在设计可以辨认埃菲尔铁塔、富士山或波斯猫的机器学习算法。
但是,这一范畴研讨的一个严重妨碍是缺乏少量带正文的数据集。
而就在明天,谷歌在其官方博客宣布,发布 Google-Landmarks 数据集来推进实例级的辨认,这也是世界上最大的人工和自然地标辨认数据集。
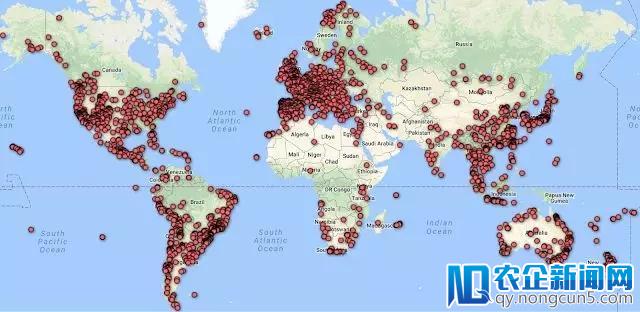
Google-Landmarks 将作为 Kaggle 网站上地标辨认和地标检索应战发布,这将是 CVPR 18 地标研讨会的重点。
该数据集包括二百万多幅图像,描画了来自世界各地的三万处共同的地标,数据集类别的数量比常用的数据集大 30 倍。此外,为了促进这一范畴的研讨,我们是开源的深度本地特征( DELF ),我们以为这是一种十分好的本地特征描绘办法,特别合适于这类义务。
地标辨认与其他成绩有一些明显的区别。例如,即便在大型带标注的数据集中,关于一些不太抢手的地标,也能够没有太多的训练数据。此外,由于地标通常是不动的物体,所以外部变化很小(换句话说,地标的大多数人都曾因不佳的交通状况而迟过到、叫过苦。经济的快速发展带动的是社会各方面的全面提升,但在此过程中,交通的发展却没跟得上前进的步幅,各类交通难题让交管部门伤透脑筋,如何利用AI来解决相关难题已成当务之急。外观在不同的图像中变化不大)。

因而,变化只会由于图像捕捉条件而发生,如遮挡、不同的视角、天气和光照,这与其他图像辨认数据集不同,其中特定类别的图像(如狗)的变化能够更大。这些特征也与其他实例级辨认成绩(如艺术品辨认)有共同之处,
因而,谷歌希望这个新的数据集也能对其他图像辨认成绩的研讨有所协助。
这两项 Kaggle 应战将为研讨人员处理这些成绩提供了获取带标注的数据的途径。 辨认轨迹应战是在测试集中树立辨认正确地标的模型,而检索应战则要求参与者检索包括相反地标的图像。 经过 Kaggle 网站就能拜访到这个新的数据集。
-End-
编辑:LXQ 校审:黄珊
参考:
https://research.googleblog.com/2018/03/google-landmarks-new-dataset-and.html?m=1