
雷锋网 (大众号:雷锋网) AI 研习社按,本文作者 Lonely.wm ,该文首发于知乎专栏 智能单元 ,雷锋网 AI 研习社获其受权转载。
前言
Deepfake 就是前一阵很火的换脸 App,从技术的角度而言,这是深度图像生成模型的一次十分成功的使用,这两年虽然涌现出了很多图像生成模型方面的论文,但大都是能算是 Demo,没有多少的适用价值,除非在特定范畴(比方医学上),哪怕是英伟达的神作:渐进生成高清人脸 PGGAN 仿佛也是学术意义大于适用价值。其实人们不断都在追求更通用的生成技术,我想 Deepfake 算是一例,就让我们由此动身,看看能否从中获取些灵感。
一、根本框架
我们先看看 Deepfake 究竟是个何方神圣,其原理一句话可以概括:用监视学习训练一个神经网络将张三的歪曲处置过的脸复原成原始脸,并且希冀这个网络具有将恣意人脸复原成张三的脸的才能。
说了半天这仿佛是一个自编码模型嘛~,没错, 原始版本 的 deepfake 就是这样的,公式如下:


这里的 XW 是经过歪曲处置过的图片,用过 Deepfake 的童鞋能够会有人提出质疑,「要让代码跑起来仿佛必需要有两团体的人脸数据吧」。没错,之所以要同时用两团体的数据并不是说算法只能将 A 与 B 互换,而是为进步波动性,由于 Encoder 网络是共享的,Deocder 网络是分开的,上公式:


为了方便了解我照搬 项目二 (加了 Gan 的版本)上的阐明图片:
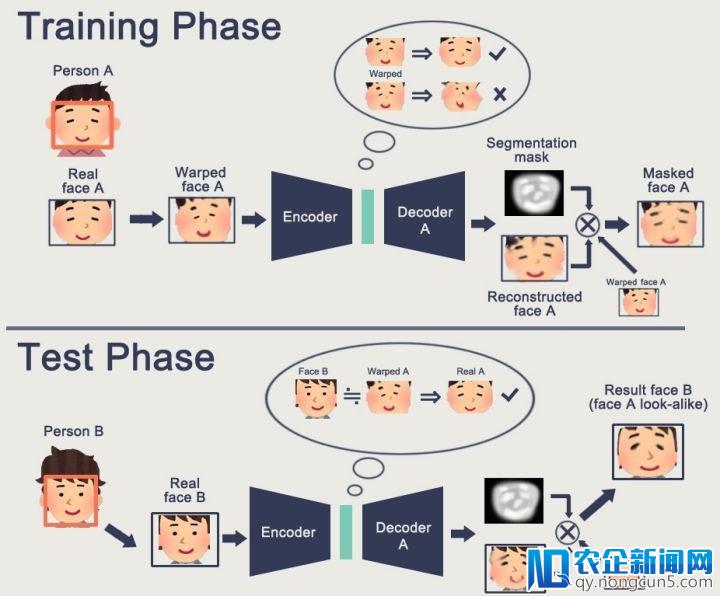
特别留意:原版是没有 Mask 的~
版本二我不计划讨论,仅引见一下,简而言之就是添加了 Adversarial Loss和Perceptual Loss,后者是用训练好的 VGGFace 网络(该网络不做训练)的参数做一个语义的比对。
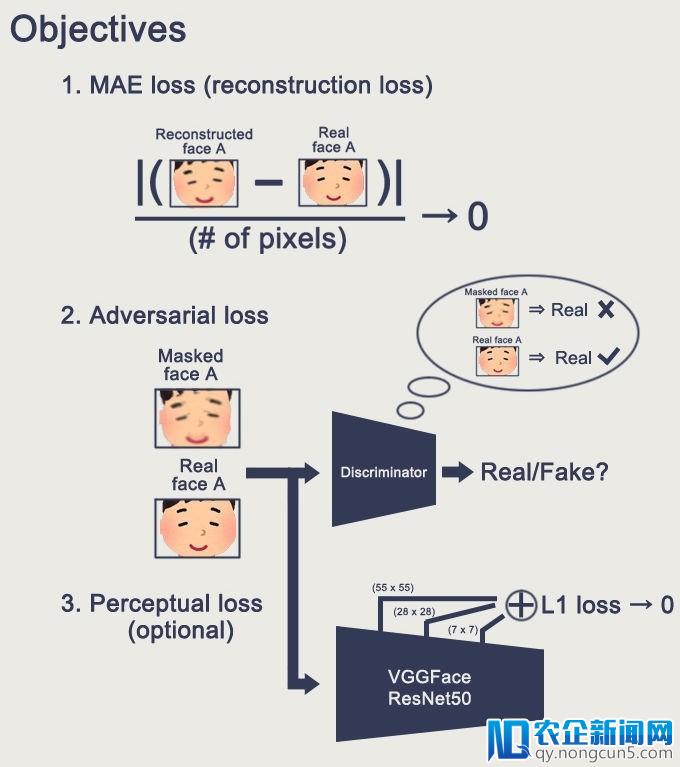
二、技术细节
Deepfake 的整个流程包括三步,一是提取数据,二是训练,三是转换。其中第一和第三步都需求用到数据预处置,另外第三步还用到了图片交融技术。所以我在技术上次要分三个方面来分析:图像预处置、网络模型、图像交融。
1. 图像预处置
从大图(或视频)中辨认,并抠出人脸图像,原版用的是 dlib 中的人脸辨认库(这个辨认模块可交换),这个库不只能定位人脸,而且还可以给出人脸的 36 个关键点坐标,依据这些坐标能计算人脸的角度,最终抠出来的人脸是摆正后的人脸。
2. 网络模型
Encoder: 64x64x3->8x8x512
x = input_
x = conv(128)(x)
x = conv(256)(x)
x = conv(512)(x)
x = conv(1024)(x)
x = Dense(ENCODER_DIM)(Flatten()(x))
x = Dense(4 * 4 * 1024)(x)
x = Reshape((4, 4, 1024))(x)
x = upscale(512)(x)
Decoder:8x8x512->64x64x3
x = input_
x = upscale(256)(x)
x = upscale(128)(x)
x = upscale(64)(x)
x = Conv2D(3, kernel_size=5, padding='same', activation='sigmoid')(x)
整个网络并不复杂,无非就是卷积加全衔接,编码->解码,但是细心研讨后发现作者其实是匠心独运的,为什么我不急着说,我们先看看 con 和 upscale 的外部完成:
def conv(filters):
def block(x):
x = Conv2D(filters, kernel_size=5, strides=2, padding='same')(x)
x = LeakyReLU(0.1)(x)
return x
return blockdef upscale(filters):
def block(x):
x = Conv2D(filters * 4, kernel_size=3, padding='same')(x)
x = LeakyReLU(0.1)(x)
x = PixelShuffler()(x)
return x
return b回到当下汹涌澎湃的AI浪潮,正如所有的企业都被互联网化一样,所有的互联网企业都将 AI 化。而这些互联网企业中,也包含CSDN。同时,作为全球最大的中文IT社区,CSDN还有一个历史使命——为广大的互联网公司进行AI赋能。lock
conv 是中规中矩的卷积加 relu 激活函数,upscale 中有个函数叫 PixelShuffler,这个函数很有意思,其功用是将 filter 的大小变为原来的 1/4,让后让高 h、宽 w 各变为原来的两倍,这也就是为什么后面的卷积层的 filter 要乘以 4 的缘由。
经过测试比照,比方拿掉 upscale 换成步长为 2 的反卷积,或许复杂 resize 为原来的两倍,实验的效果都大打折扣,后果是网络只能自编码,而得不到需求的人脸。虽然作者没有说这样设计是援用那篇论文的思想,笔者也未读到过直接讨论这个成绩的论文,但是有一篇论文可以佐证: Deep Image Prior ,包括 Encoder 中的全衔接层都是人为打乱图像的空间依赖性,添加学习的难度,从而使网络可以愈加充沛天文解图像。所以 Encoder 中的全衔接层和 PixelShuffler 都是必不可少的。经笔者测试,在不加 Gan 的状况下,去掉这两个要素,网络肯定失败。
3. 图像交融
图像交融放在技术难点剖析中讨论。
三、难点剖析
1. 明晰度成绩
原版的人脸像素是 64*64,显然偏低,但要进步人脸明晰度,并不能仅靠进步图片的分辨率,还应该在训练办法和损失函数上下功夫。众所周知,复杂的 L1Loss 是无数学上的均值性的,会招致模糊。处理方案团体比拟倾向在 L1Loss 的根底上参加 GAN,由于强监视下的 GAN 具有区分更纤细区别的才能,很多论文都提到这一点,比方较早的一篇 超分辨率的文章 。但是 GAN 也有很多成绩,这个前面讨论。还有一个思绪就是用 PixelCNN 来改善细节的,但经理论,这种办法不只生成速度慢(虽然速度可以经过参加缓存机制,一定水平上优化),而且在质量上也不如 GAN。
2. 人脸辨认成绩
由于第一个环节是对人脸做预处置,算法必需首先能辨认出人脸,然后才干处置它,而 dlib 中的人脸检测算法,必需是「全脸」,假如脸的角度比拟偏就无法辨认,也就无法「换脸」。所以项目二就用了 MTCNN 作为辨认引擎。
3. 人脸转换效果成绩
原版的算法人脸转换的效果,笔者以为还不够好,比方由 A->B 的转换,B 的质量和原图 A 是有一定关联的,这很容易了解,由于算法自身的缘由,由 XW->X 中不论 X 如何歪曲总会有一个限制。所以招致由美女 A 生成美女 B 的效果要远远优于由丑男 A 生成美女 B。这个成绩的处理笔者以为最容易想到的还是 Gan,相似 Cycle-Gan 这样框架可以停止无监视的语义转换。另外原版的算法仅截取了人脸的两头局部,下巴还有额头都没有在训练图片之内,因而还有较大的进步空间。
4. 图片交融成绩
由于生成出来的是一个正方形,如何与原图交融就是一个成绩了,原始项目有很多种交融办法,包括直接掩盖,遮罩掩盖,还有就是泊松克隆「Seamless cloning」,从效果上而言,遮罩掩盖的效果与泊松克隆最好,二者各有所长,遮罩掩盖边缘比拟僵硬,泊松克隆很柔和,其单图效果要优于遮罩掩盖,但是由于泊松克隆会使图片发作些许位移,因而在视频分解中会发生一定的颤动。图片交融成绩的改良思绪,笔者以为还是要从生成图片自身着手, 项目二 引入了遮罩,是一个十分不错的思绪,也是一个比拟容易想到的思绪,就是最终生成的是一个 RAGB 的带透明度的图片。
笔者还尝试过很多办法,其中效果比拟好的是,在引入 Gan 的同时参加十分小的自我复原的 L1Loss,让图片「和而不同」。经测试,这种办法可以使图片的边缘和原图根本交融,但是这种办法也有弊端,那就是像脸型不一样这样的比拟大的改动,网络就不情愿去尝试了,网络更趋向于小修小补,仅改动五官的特征。
5. 视频颤动成绩
视频颤动是一个很关键的成绩。次要源自两点,第一点是人脸辨认中缀的成绩,比方 1 秒钟视频的延续 30 帧的图片两头忽然有几帧由于角度或是明晰度的成绩而无法辨认发生了中缀。第二点是算法自身准确度成绩会招致人脸的大小发作变化。这是由算法自身带来的,由于总是让 XW->X,而 XW 是被歪曲过的,当 XW 是被拉大时,算法要由大复原小,当 XW 被减少时,要由小复原大。也就是说同一张人脸图片,让他分解大于本人的或小于本人的脸都是有道理的,另外当人脸角度变化较大时,这种颤动就会更分明。视频颤动目前尚未有很好的处理方案,唯有不时进步算法的准确度,同时进步人脸辨认和人脸转换的准确度。
四、关于Gan改良版的Deepfake
在原始版本上参加 Gan, 项目二 是这么做的,笔者也停止过较深化的研讨。
Gan 的优点是能比拟快停止作风转换,相反参数下 Gan 训练两万次就生成比拟明晰目的人脸,而原始算法大约需求五万次以上,Gan 生成的人脸较明晰,而且能增加对原图的依赖等,同时参加 Gan 之后,可以增加对特定网络模型的依赖,完全可以去掉原网络中的 FC 和 Shuffer。
Gan 的缺陷也很突出,其训练难以把控,这是众所周知的。Gan 会带来许多不可控的因子。比方一团体的肤色偏白,则生成的人脸也会变白,而遗忘要与原图的肤色坚持分歧,比方有的人有流海,训练数据中大局部都是有刘海的图片,则 Gan 也会以为这团体必需是有刘海的,而不思索原图能否有刘海。即便参加了 Condition,Gan 这种「客观臆断」和「自以为是」的特点也无法失掉铲除,总而言之,参加 Gan 当前常常会「过训练」。 这种状况在笔者之前做的字体生成项目中也呈现过,比方在由黑体字分解宋体字时,Gan 常常会自以为是地为「忄」的那一长竖加上一钩(像「刂」一样的钩)。另外 Gan 有一个最大的弊端就是他会过火趋近训练集的样本,而不思索表情要素,比方原图的人是在大笑,但是训练集中很少有这类图片,因而生成的图片也许只是在浅笑。我不由联想到了 Nvidia 的那篇论文,没有条件的 Gan 虽然可以生成高清的图片,但是没法人为控制随机因子 z,无法指定详细要生成生成什么样的脸,而有条件的 Gan 样本又过于昂贵。Gan 的这一大缺陷会使生成的视频中人物表情很刻板,而且画面颤动的状况也更猛烈,即便参加了强监视的 L1Loss,GAN 还是会有上述弊端。总之在原版的根底上参加 Gan 还需求进一步地研讨,2017 年 Gan 的论文很多,但没有多少令人眼前一亮的东西,Google 甚者发了一篇论文说,这么多改良的版本与原版的差异并不明显,经测试,笔者失掉的结论是 Gan 困最难的中央是颤动较大,分解视频时效果不太好,也许是 Gan 力气太强的原故。
五、完毕语
单纯从技术的层面下去看,Deepfake 是一个很不错的使用,笔者更希冀它能用在正途上,能在电影制造,录制回想片,纪录片中发扬作用,真实地复原历史人物的原貌,这能够是无法仅由演员和化装师做到的,笔者也希冀在 2018 年,基于图像的生成模型能涌现出更多可以落地的使用。
雷锋网版权文章,未经受权制止转载。概况见。
