
雷锋网 AI 研习社按,日前,阿里机器翻译团队和 PAI 团队宣布博文,论述将 TVM 引入 TensorFlow,可以带来至多 13 倍的 batch 矩阵相乘(matmul)减速。雷锋网 AI 研习社将原文编译整理如下:
背景
神经机器翻译(NMT)是一种端到端的自动翻译办法,能够克制传统的基于短语的翻译零碎的缺陷。最近,阿里巴巴集团正努力于在全球电子商务中部署 NMT 效劳。
目前,我们将 Transformer( https://arxiv.org/pdf/1706.03762.pdf ) 作为 NMT 零碎的中心组成。相较于传统基于 RNN/LSTM 的办法,它更合适于高效的离线训练,有着相反或更高的精度。
Transformer 在工夫步长中打破了相关性,对离线训练更敌对,但在在线推理上,它并没有那么高效。我们在消费环境中发现初版 Transformer 的推理速度大约比 LSTM 版本慢 1.5 倍到 2 倍。为了进步推感性能,我们曾经停止了一些优化,包括图级别的 op 交融、循环不变节点外提(loop invariant node motion)。我们察看到一个特殊成绩:batch 矩阵相乘是 Transformer 中的一个关键成绩,目前它在 cuBLAS 中的完成并未失掉很好的优化。
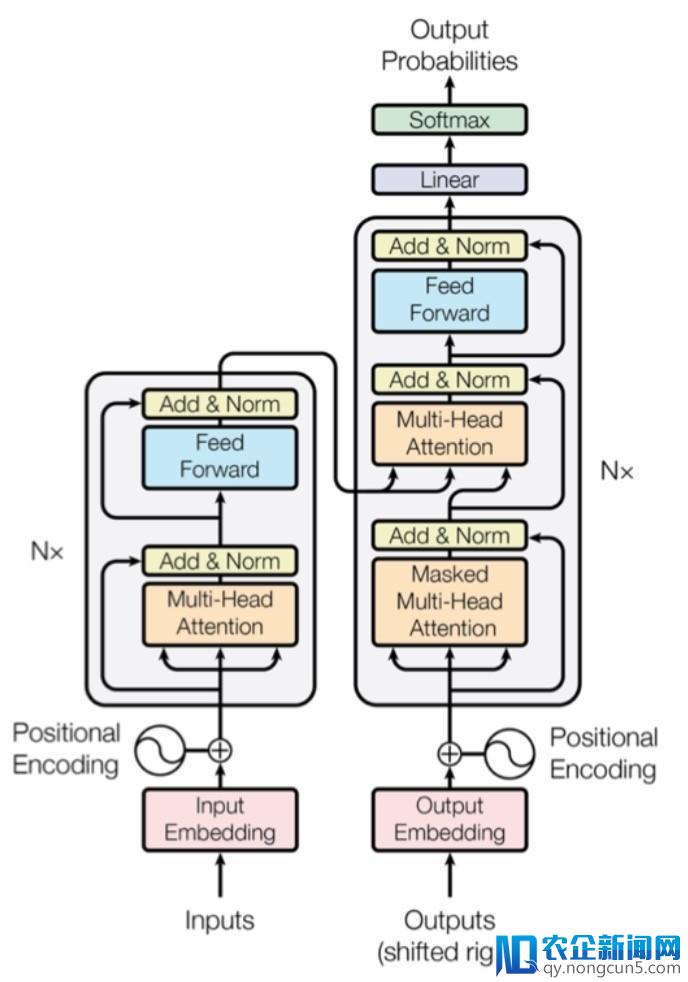
图1:Transformer 模型架构
下图标明,经过 TVM 生成的内核可以带来至多 13 倍的 batch 矩阵相乘减速,随同算子交融,速度将更快。
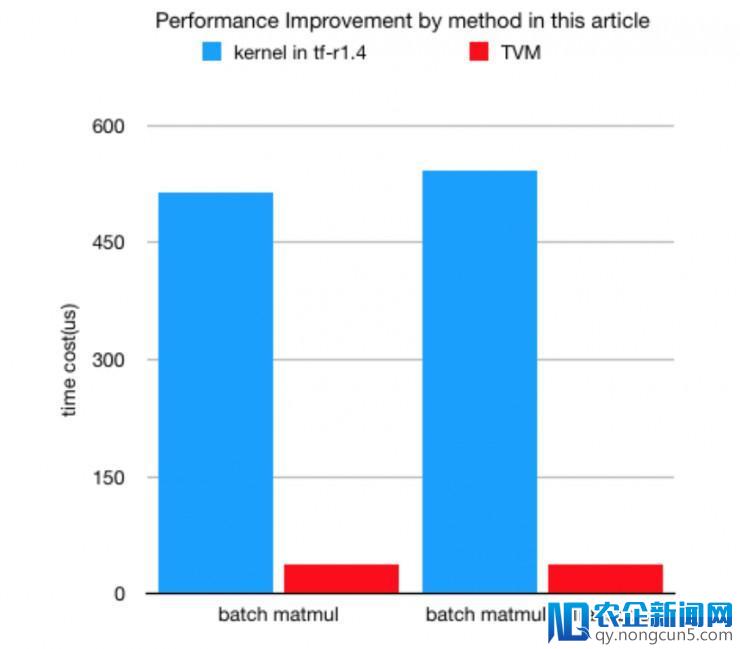
batch 矩阵相乘
为什么选择应用 batch 矩阵相乘
在 Transformer 中,batch 矩阵相乘被普遍使用于 multi-head attention 的计算。应用 batch 矩阵相乘,可以并行运转 attention 层中的 multiple heads,这有助于进步硬件的计算效率。
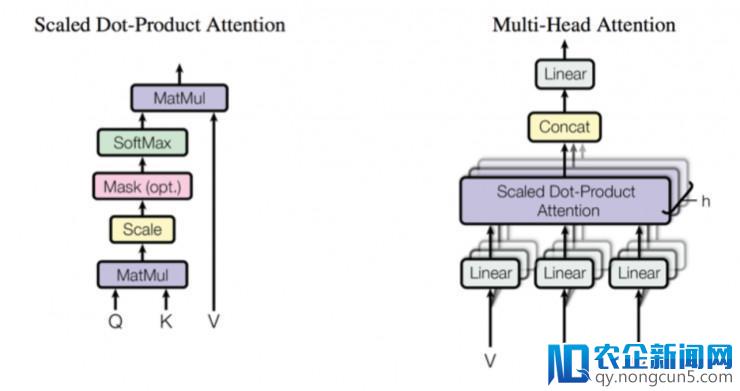
图2:左图为 Scaled Dot-Product Attention,右图为并行运转若干 attention 层的 Multi-Head Attention
我们在推理阶段对 Transformer 模型停止了片面剖析,后果标明,batch 矩阵相乘计算的开支到达 GPU 内核执行工夫的 30%。当运用 nvprof 对 cuBLAS batch 矩阵相乘内核做一些第一原理(first-principle)剖析,很分明,这种办法的表现并不好,同时我们还发现几个风趣的景象。
什么是 batch 矩阵相乘
通常,batch 矩阵相乘计算会在一批矩阵上执行矩阵-矩阵乘法。batch 被以为是「一致的」,即一切实例都具有相反的维度(M,N,K)、leading 维度 (lda,ldb,ldc) 和它们各自的 A、B、C 矩阵的转置。
batch 矩阵相乘计算详细可以描绘如下:
void BatchedGemm(input A, input B, output C, M, N, K, batch_dimension) {
for (int i = 0; i < batch_dimension; ++i) {
DoGemm(A[i],B[i],C[i],M,K,N)
}
}
batch 矩阵相乘外形
在言语翻译义务中,batch 矩阵相乘的外形比在其他任务负载下的惯例矩阵相乘计算要小得多。Transformer 的外形与输出语句的长度和解码器步长有关。普通来说小于 30。
至于 batch 维度,当给定推理 batch 大小时,它是固定数字。例如,假如 batch size 是 16,beam size 是 4,batch 维度是 16 * 4 * #head (在 multi-headattention 中 head 的数目,通常为 8)。矩阵 M、K、N 的范围在 [1, max decode length] 或 [1, max encode length] 内。
batch 矩阵相乘的功能成绩
首先,我们在实际上对 batch 矩阵相乘内核停止了 FLOP 剖析。后果十分风趣:一切 batch 矩阵相乘的计算强度都是受限的(TFLOP 数少于 1)。
然后,我们经过 nvprof 描绘了多外形 batch 矩阵相乘的 cuBLAS 功能。上面的表格中是运用 NVIDIA M40 GPU(CUDA 8.0)失掉的一些目标。

即便外形不同(在 M、N、K 间变化),一切 maxwell_sgemmBatched_128x128_raggedMn_tn 调用执行的都是相反的 FLOP 数,这比实际值大得多。从中可以推断,一切这些不同的外形最终都会被填充成确定的外形。在一切的外形中,即便在最好的状况下,实际 FLOP 只占实践执行 FLOP 的 2.74%,因而大少数计算都是多余的。相似地,调用另一个 cuBLAS 内核 maxwell_sgemmBatched_64x64_raggedMn_tn 也呈现相反状况。
不言而喻,cuBLAS batch 矩阵相乘的执行效率很低。基于这个缘由,我们在 NMT 中运用 TVM 生成高效的 batch 矩阵相乘内核。
batch 矩阵相乘计算
在 TVM 中,普通 batch 矩阵相乘计算声明如下:
# computation representation
A = tvm.placeholder((batch, M, K), name='A')
B = tvm.placeholder((batch, K, N), name='B')
k = tvm.reduce_axis((0, K), 'k')
C = tvm.compute((batch, M, N),
lambda b, y, x: tvm.sum(A[b, y, k] * B[b, k, x], axis = k),
name = 'C')
调度优化
在声明计算之后,我们需求细心地设计调度来更好地发扬功能。
调理 block/线程数的参数
# thread indices
block_y = tvm.thread_axis("blockIdx.y")
block_x = tvm.thread_axis("blockIdx.x")
thread_y = tvm.thread_axis((0, num_thread_y), "threadIdx.y")
thread_x = tvm.thread_axis((0, num_thread_x), "threadIdx.x")
thread_yz = tvm.thread_axis((0, vthread_y), "vthread", name="vy")
thread_xz = tvm.thread_axis((0, vthread_x), "vthread", name="vx")
# block partitioning
BB, FF, MM, PP = s[C].op.axis
BBFF = s[C].fuse(BB, FF)
MMPP = s[C].fuse(MM, PP)
by, ty_block = s[C].split(BBFF, factor = num_thread_y * vthread_y)
bx, tx_block = s[C].split(MMPP, factor = num_thread_x * vthread_x)
s[C].bind(by, block_y)
s[C].bind(bx, block_x)
vty, ty = s[C].split(ty_block, nparts = vthread_y)
vtx, tx = s[C].split(tx_block, nparts = vthread_x)
s[C].reorder(by, bx, vty, vtx, ty, tx)
s[C].reorder(by, bx, ty, tx)
s[C].bind(ty, thread_y)
s[C].bind(tx, thread_x)
s[C].bind(vty, thread_yz)
s[C].bind(vtx, thread_xz)
我们交融了 batch 矩阵相乘的内部维度,例如 op 维的 BB 和 FF 在 batch 矩阵相乘计算中通常称为「batch」维,我们用一个因子 (number_thread * vthread) 联系内部和外部维度。
在 batch 矩阵相乘中不需求 Strided 形式,因而将虚拟线程数(vthready 和 vthreadx)都设置为 1。
找到 number_thread 的最佳组合
上面的后果是基于 NVIDIA M40 GPU(CUDA 8.0)。
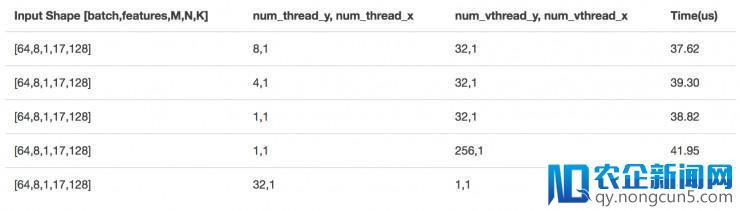
基于过来的经历,找到 num_thread_y 和 num_thread_x 最佳组合的办法是经过暴力搜索(brute-force search)。经过暴力搜索后,可以找到以后外形的最佳组合,在以后的计算中,num_thread_y = 8,num_thread_x = 32。
将 batch 矩阵相乘与其他运算交融
现有的「黑盒」cuBLAS 库调用普通会作为常用的「op 交融」优化战略的边界。但是,应用生成的高效 batch 矩阵相乘内核,交融边界极易被打破,将不只仅是各个元素之间的交融,因而可以取得更好的功能改良。
从计算图中可以看出,batch 矩阵相乘之后总是随同着播送加法运算或转置运算。
经过将「加法」或「转置」运算与 batch 矩阵相乘交融,可以增加内核启动开支和冗余内存拜访工夫。
batch 矩阵相乘和播送加法交融计算的声明如下:
# computation representation
A = tvm.placeholder((batch_size, features, M, K), name='A')
# the shape of B is (N, K) other than (K, N) is because B is transposed is this fusion pattern
B = tvm.placeholder((batch_size, features, N, K), name='B')
ENTER = tvm.placeholder((batch_size, 1, M, N), name = 'ENTER')
k = tvm.reduce_axis((0, K), 'k')
C = tvm.compute(
(batch_size, features, M, N),
lambda yb, yf, m, x: tvm.sum(A[yb, yf, m, k] * B[yb, yf, x, k], axis = k),
name = 'C')
D = topi.broadcast_add(C, ENTER)
batch 矩阵相乘和转置交融计算的声明如下:
# computation representation
A = tvm.placeholder((batch_size, features, M, K), name='A')
B = tvm.placeholder((batch_size, features, K, N), name='B')
k = tvm.reduce_axis((0, K), 'k')
C = tvm.compute( 本次涌现的 AI、区块链和物联网热潮不同于以往,将对产业、社会和生活产生真正堪称“颠覆性”的变革。IT 技术人员需要全方位地“换脑”:对原有的知识结构进行全面刷新,全面升级。
(batch_size, M, features, N),
lambda yb, m, yf, x: tvm.sum(A[yb, yf, m, k] * B[yb, yf, k, x], axis = k),
name = 'C')
交融内核功能
测试生成代码功能时,外形选择为 [batch=64, heads=8, M=1, N=17, K=128]。选择 17 作为序列长度是由于它是我们消费中的均匀输出长度。
-
tf-r1.4 BatchMatmul: 513.9 us
-
tf-r1.4 BatchMatmul + Transpose (separate): 541.9 us
-
TVM BatchMatmul: 37.62 us
-
TVM BatchMatmul + Transpose (fused): 38.39 us
内核交融优化带来了 1.7 倍的减速。
集成 TensorFlow
在我们的任务负载中,batch 矩阵相乘的输出外形是无限的,易于提早枚举。有了这些预定义的外形,我们可以提早生成高度优化的 CUDA 内核(固定外形的计算可以带来最佳优化潜能)。同时,还将生成一个合适大少数外形的通用 batch 矩阵相乘内核,为没有提早生成内核的外形提供回退机制。
我们将生成的针对特定外形的高效内核和回退机制集成到 Tensorflow 中。我们开发了一些交融操作,例如 BatchMatMulTranspose 或 BatchMatMulAdd——运用 TVM runtime API 为确定输出外形启动特定生成的内核或调用回退内核。
经过执行图优化 pass,可以应用交融操作自动交换原始batch matmul + add/transpose。同时,经过结合更保守的图优化 pass,我们尝试应用 TVM 为长尾操作形式生成更高效的交融内核,以进一步提升端到端功能。
总结
在阿里巴巴,我们发现 TVM 是十分无效的开发高功能 GPU 内核的工具,可以满足我们的外部需求。
在本博客中,我们以 Transformer 模型为例,阐明了我们应用 TVM 的优化战略。
首先,我们经过第一原理剖析确定了 Transformer 模型的关键成绩。然后,我们运用 TVM 生成高度优化的 CUDA 内核来取代 cuBLAS 版本(此时到达 13 倍的减速)。
接上去,应用 TVM 的内核交融机制来交融 batch 矩阵相乘的前/后操作,以带来进一步的功能改良(功能提升 1.7 倍)。端到端的功能改善到达 1.4 倍。基于这些生成的内核,我们开发了一个图优化 pass,自动用 TVM 交融内核交换掉原有的计算形式,确保优化对终端用户通明。
最初,一切这些优化都以松懈耦合的方式集成到 TensorFlow 中,这展现了将 TVM 与不同深度学习框架集成的潜在方式。
目前我们还有一项正在停止的任务——将 TVM 整合为 TensorFlow 的 codegen 后端。我们希望未来与社群分享更多效果。
via: http://www.tvmlang.org
雷锋网 (大众号:雷锋网) AI 研习社编译整理。
雷锋网版权文章,未经受权制止转载。概况见。
