
雷锋网AI研习社按: 人工智能技术开展迅猛的面前不只得益于庞大的数据量,更需求弱小的硬件支持。面对层出不穷的 AI 使用,曾经很难采用一种通用的硬件停止高效的数据计算和处置,这也促使了各品种型的 AI 芯片蓬勃开展。
近期,在雷锋网 AI 研习社线上地下课上,Thinker (AI 芯片) 团队深度学习平台担任人周鹏程分享了目前主流的散布式异构计算特性,区别和使用,并且引见了如何让以后盛行的大数据剖析引擎(如:Spark)从 AI 芯片的弱小计算才能中获益。视频回放:http://www.mooc.ai/open/course/479
周鹏程,Thinker (AI 芯片) 团队深度学习平台担任人,曾就职于阿里巴巴技术保证事业部,担任算法工程师;清华大学微电子硕士,次要研讨方向:面向可重构芯片的编译器后端优化,指令级并行,高并发编程模型以及散布式计算。
分享主题 :如何在集群中高效地部署和运用 AI 芯片
分享提纲:
关于Hadoop YARN资源管理零碎的引见
Spark散布式计算框架的引见
各种异构芯片不同的平台,特性,区别,以及使用
开源项目StarGate
这次直播分享首先为大家引见 Hadoop YARN 资源管理零碎。Hadoop YARN 资源管理框架,它次要管理集群中的 CPU 和内存。
YARN(Yet Another Resource Negotiator)是一个通用的资源管理平台,可为各类计算框架提供资源的管理和调度。
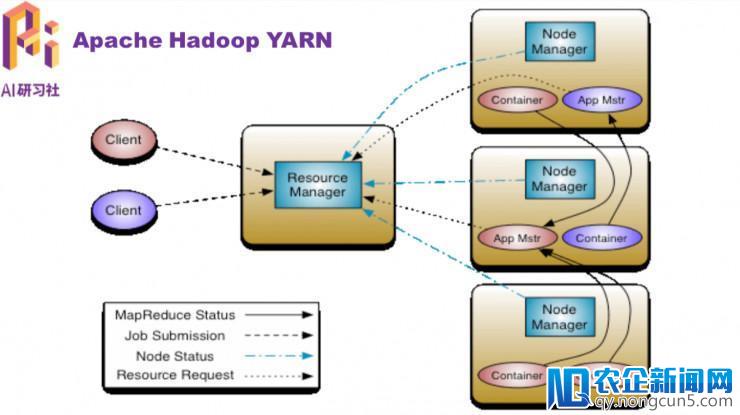
YARN 总体上是 Master/Slave 构造,次要由 ResourceManager、NodeMan本着网络面前人人平等的原则,提倡所有人共同协作,编写一部完整而完善的百科全书,让知识在一定的技术规则和文化脉络下得以不断组合和拓展。 ager、 ApplicationMaster 和 Container 等几个组件构成。
NodeManager (NM) 是每个节点上的资源和义务管理器。它会定时地向 RM 汇报本节点上的资源运用状况和各个 Container 的运转形态;同时会接纳并处置来自 AM 的 Container 启动/中止等恳求。
ApplicationMaster (AM) 用户提交的使用顺序均包括一个 AM,担任使用的监控,跟踪使用执行形态,重启失败义务等。ApplicationMaster 是使用框架,它担任向 ResourceManager 协调资源,并且与 NodeManager 协同任务完成 Task 的执行和监控。
Container 是 YARN 中的资源笼统,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当 AM 向 RM 请求资源时,RM 为 AM 前往的资源便是用 Container 表示的。YARN 会为每个义务分配一个 Container 且该义务只能运用该 Container 中描绘的资源。
接上去引见一个特殊的 applicationmaster,它就是 Spark。这个计算框架十分盛行,可以支持流式计算,图计算,数据库查询。更多关于 Spark 的引见,大家可以参考官网,本文次要引见如何让 spark 使用在异构计算平台上。
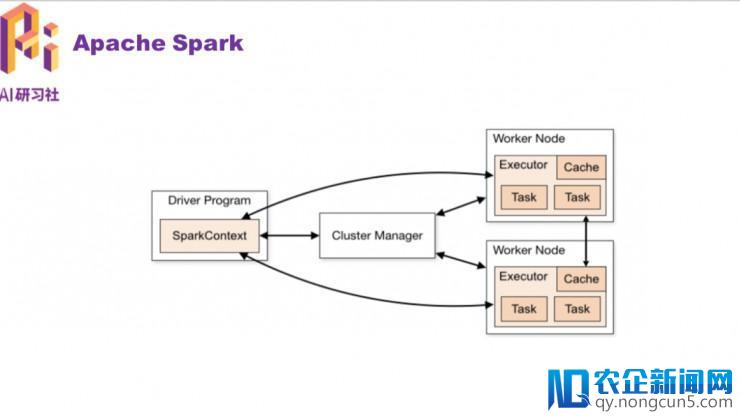
Spark 的数据构造 RDD (Resilient Distributed Dataset)
RDD 是 Spark 提供的中心笼统,全称为 Resillient Distributed Dataset,即弹性散布式数据集。可以笼统地以为它是在一个集群环境中的一个大数组,这个数组不可变,但又可以切分很多的小数组,每一个小数组(partition)被分发到集群中的几个节点,这样就完成了数据的并行,然后把计算推送到无数据的节点上,就完成了一次散布式计算。

RDD 通常经过 Hadoop 上的文件,即 HDFS 文件或许 Hive 表,来停止创立;有时也可以经过使用顺序中的集合来创立。
RDD 最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过去。即假如某个节点上的 RDD partition,由于节点毛病,招致数据丢了,那么 RDD 会自动经过本人的数据来源重新计算该 partition。这一切对运用者是通明的。
RDD 的数据默许状况下寄存在内存中的,但是在内存资源缺乏时,Spark 会自动将 RDD 数据写入磁盘。
Spark on YARN 形式的计算瓶颈是底层芯片上,关于这局部可观看回放 视频 引见。
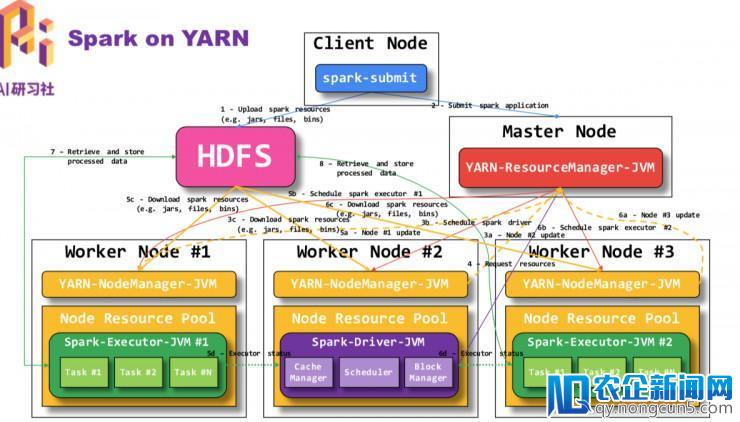
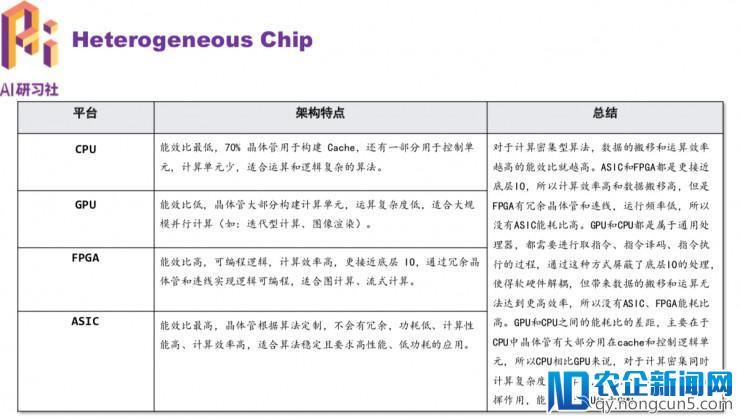
接上去是CPU,GPU,FPGA,AI芯片在不同的使用上的区别。

图中绿色的局部是 GPU 计算中心,GPU 的计算单元特别丰厚,但是控制逻辑单元十分少,这就招致它只能适用于比拟规则的计算类型,比方卷积运算,这品种型的运算只是复杂且反复的做矩阵乘法。因而,最合适用GPU了。
FPGA 和 GPU 的不一样在于,FPGA 首先设计资源遭到很大的限制,例如 GPU 假如想多加几个中心只需添加芯片面积就行,但 FPGA 一旦你型号选定了逻辑资源下限就确定了(浮点运算在 FPGA 里会占用很多资源),其次,FPGA 外面的逻辑单元是基于 SRAM-查找表,其功能会比 GPU 外面的规范逻辑单元差好多。最初,FPGA 的布线资源也受限制(有些线必需要绕很远),不像 GPU 这样走 ASIC flow 可以随意布线,这也会限制功能。
理想中有很多使用,不是都合适用 GPU 来处置,比方图计算。我们都晓得图是由很多的节点和边组成,假如用一个节点表示一个算子,节点之间的边表示数据相关或数据依赖的话,我们就构建了一个计算图,也可以称为数据流图(DFG)本次涌现的 AI、区块链和物联网热潮不同于以往,将对产业、社会和生活产生真正堪称“颠覆性”的变革。IT 技术人员需要全方位地“换脑”:对原有的知识结构进行全面刷新,全面升级。。之所以说图计算不合适用 GPU 来做的,是由于它没有方法高效处置这种数据依赖,只能经过访存来传递这种依赖。而假如把这种数据流图映射到 FPGA 上,就可以经过计算单元之间的连线构造来传递和处置这种依赖,而且不同的计算单元可以执行不同的算子,再使用流水线技术,便可以大大降低访存的压力,大幅度进步功能。这就是 FPGA 比拟适用于不规则使用(如:图计算、流式计算)的缘由所在。
CPU,GPU,FPGA,ASIC 的架构特点
下图是我们团队研发的三款芯片,次要用于深度学习使用的减速。

英特尔FPGA的开发流程
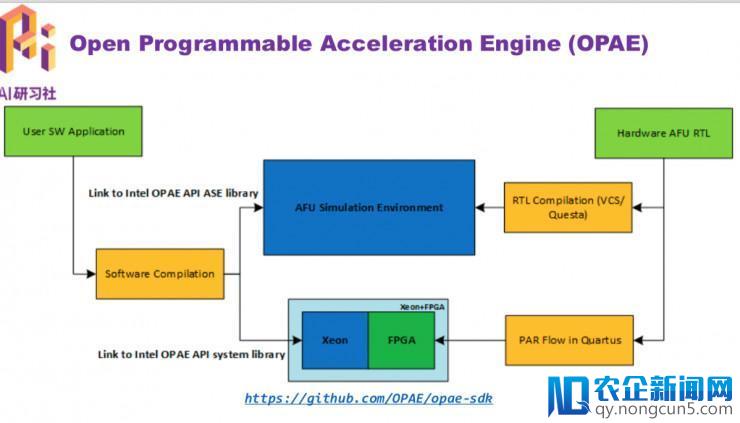
理解芯片的根本开发流程后,我们接上去要思索的是如何高效地管理和运用效劳器上曾经装置好的各种减速器资源。为了完成这个目的,需求设计和完成对应的组件或许效劳,比方需求一个监控组件用于实时监控减速器的各种形态和资源运用状况,同时还需求一个调度器组件担任为多个使用顺序分配相应的减速器资源。总之,我们需求一个停止资源管理的效劳。
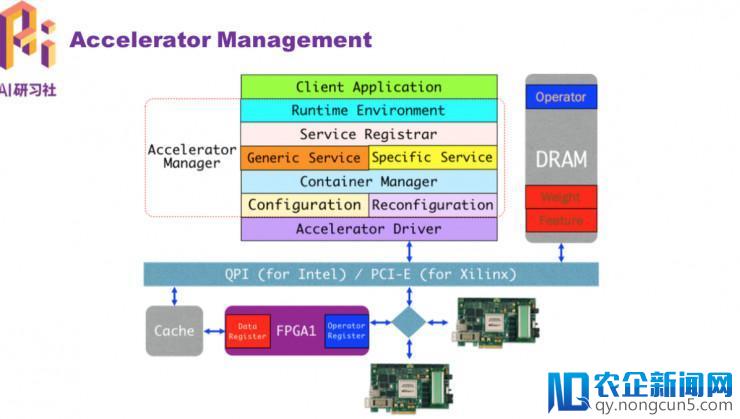
这是我们团队自主研发的 StarGate 开源项目。地址: http://github.com/stargate-team/stargate

StarGate 的次要架构
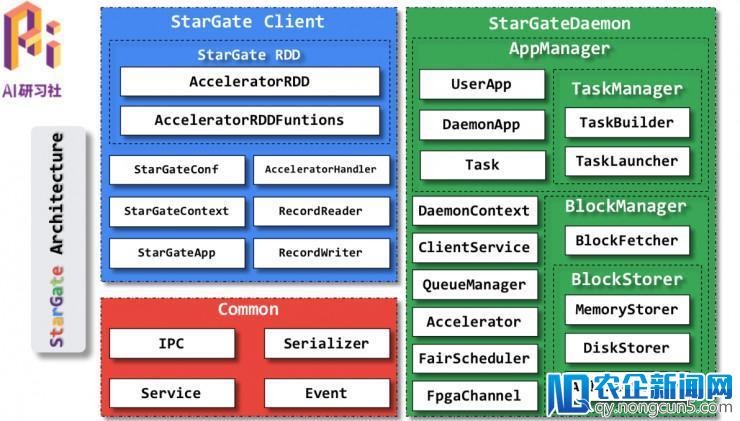
接上去是 Spark on StarGate 局部的解说,由于篇幅限制,这里不再做文字内容回忆,感兴味的同窗可以直接观看视频回放。视频地址链接:http://www.mooc.ai/open/course/479
总结
以后盛行的大数据消费零碎的计算瓶颈存在于底层芯片上,而芯片可以在很大水平上缓解计算压力。为了阐明 AI 芯片弱小的计算才能,辨别引见 AI 芯片的根本架构、特性以及适用场景。但是不同的 AI 芯片对以后主流的大数据消费零碎的支持水平不同,很多时分需求扩展以后的消费零碎才干集成现有的 AI 芯片。为了最小化 AI 芯片在数据中心部署的代价并且高效天时用 AI 芯片的弱小计算才能,我们设计并开发了开源项目 StarGate。
以上就是本次雷锋网 AI 研习社地下课的全局部享内容。更多视频直播课程关注微信大众号:AI 研习社
雷锋网 (大众号:雷锋网) 出品
。
