
雷锋网 (大众号:雷锋网) AI 科技评论按:CVPR 2018 总投稿量超 4000 篇,最终录取数超 900 篇,录取率不到 23%。其中,优必选悉尼 AI 研讨院有 4 篇论文被录用为 poster。论文详细解读如下:
论文1:An Efficient and Provable Approach for Mixture Proportion Estimation Using Linear Independence Assumption
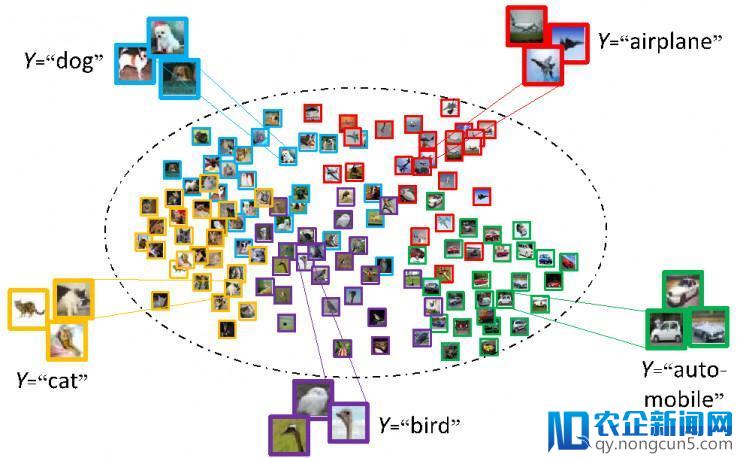
为了研讨混合散布中各个组成辨别的比例系数,假定各个组成散布满足线性独立的假定(即不存在一种组合系数,使得这些组成散布的线性组合所失掉的散布函数处处为0),并且假定每个组成散布中都可以采样到大批的数据。首先论证了组成散布线性独立(组成散布不相反即可)的假定要弱于现有的估量其比例办法的各种假定。其次,提出先将各个散布嵌入到再生核Hilbert空间,再应用最大均匀差别的办法求取各组成散布的比例系数。该办法可以(1)保证比例系数的独一性和可辨认性;(2)保证估量的比例系数可以收敛到最优解,而且收敛率不依赖于数据自身;(3) 经过求解一个复杂的二次规划成绩来疾速获取比例系数。这项研讨拥有普遍的使用背景,比方含有噪声标签的学习,半监视学习等等。
论文2:Deep Ordinal Regression Network for Monocular Depth Estimation
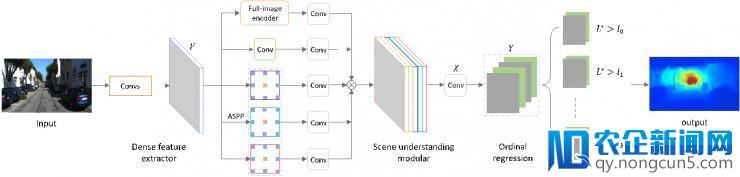
在3D视觉感知主题里,单目图像深度估量是一个重要并且困难的义务。虽然目前的办法曾经获得了一些不错的成果,但是这些办法普遍疏忽了深度间固有的有序关系。针对这一成绩,我们提出在模型中引入排序机制来协助更精确地估量图像的深度信息。详细来说,我们首先将真值深度(ground-truth depth)依照区间递增的办法预分为许多深度子区间;然后设计了一个像素到像素的有序回归(ordinal regression)损失函数来模仿这些深度子区间的有序关系。在网络构造方面,不同于传统的编码解码 (encoder-decoder)深度估量网络, 我们采用洞卷积 (dilated convolution)型网络来更好地提取多尺度特征和获取高分辨率深度图。另外,我们自创全局池化和全衔接操作,提出了一个无效的全局信息学习器。我们的办法在KITTI,NYUV2和Make3D三个数据集上都完成了以后最佳的后果。并且在KITTI新开的测试效劳器上获得了比官方baseline高出30%~70%的分数。
论文3:Self-Supervised Adversarial Hashing Networks for Cross-Modal Retrieval
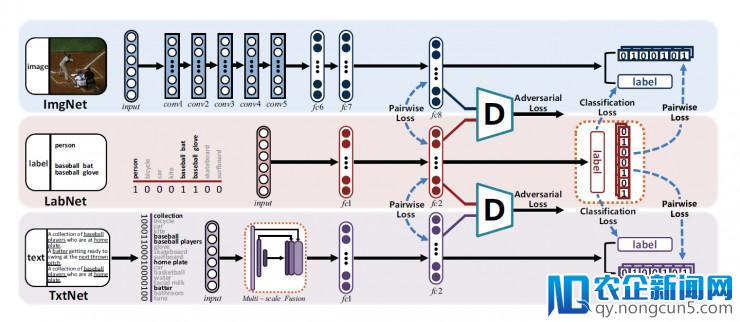
由于深度学习的成功,最近新生的改变世界的企业将会诞生,从而更好的服务整个人类世界,走向更高科技的智能化生活。跨模态检索取得了明显开展。但是,依然存在一个关键的瓶颈,即如何减少多模态之间的模态差别,进一步进步检索精度。本文提出了一种自我监视对立哈希(SSAH)办法。这种将对立学习以自我监视的方式引入跨模态哈希研讨,目前还处于研讨晚期。这项任务的次要奉献是采用了一组对立网络来最大化不同模态之间的语义相关性和表示分歧性。另外,作者还设计了一个自我监视的语义网络,这个网络针对多标签信息进一步发掘高层语义信息,运用失掉的语义信息作为监视来指点不同模态的特征学习进程,以此,模态间的类似关系可以同时在共同语义空间和海明空间两个空间内得以坚持,无效地减小了模态之间的差别,进而发生准确的哈希码,进步检索精度。在三个基准数据集上停止的少量实验标明所提出的 SSAH 优于最先进的办法。
论文4:Geometry-Aware Scene Text Detection with Instance Transformation Network
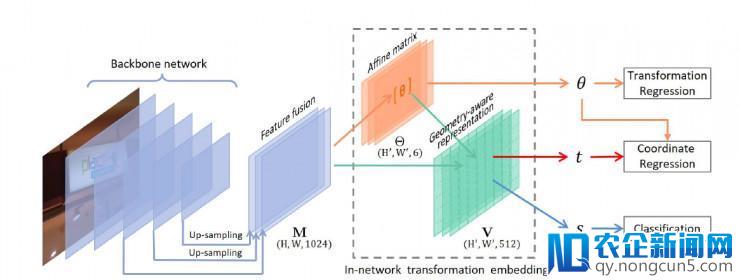
自然场景文字辨认由于其文字外形、规划非常多变,是计算机视觉中具有应战性的成绩。在本文中,我们提出了几何感知建模办法(geometry-aware modeling)和端对端学习机制(end-to-end learning scheme)来处置场景文字编码的成绩。我们提出了一种新的实例转换网络(instance transformation network),运用网内变换嵌入的办法学习几何感知编码,从而完成一次经过的文本检测。新的实例变换网络采用了转换回归,文本和非文本分类和坐标回归的端对端多义务学习战略。基准数据集上的实验标明了所提办法在多种几何构型下的无效性。
雷锋网版权文章,未经受权制止转载。概况见。
