

图片来源:视觉中国
试想一下,在一个喧闹的鸡尾酒会上,同时存在着许多不同的声源:多团体同时说话的声响、餐具的碰撞声、音乐声等等。如何在酒会上分辨出特定人物的声响,这关于我们人类来说非常复杂。
但关于计算机来说,要把一个音频信号联系成多个不同的语音来源,仍然有许多顺手的成绩需求处理。当许多人的语音交叠在一同的时分,AI时常措手不及。1953年Cherry提出“鸡尾酒会”成绩至今,依然没有人可以处理机器深度学习辨认别离人声的成绩。
但是,近日在Google Research软件工程师Inbar Mosseri和Oran Lang宣布的论文《Looking to Listen at the CocktailParty》中,采用了一个全新的视听模型为“鸡尾酒会”成绩提供了一个适宜的处理之道。
音频-视觉语音别离模型,处理“鸡尾酒会效应”
为理解决“鸡尾酒会”成绩,谷歌从YouTube上搜索了10万个高质量讲座和演讲视频生成训练样本,经过约2000 个小时的视频片段剖析,训练出基于多流卷积神经网络(CNN)的模型,将分解鸡尾酒会片段联系成视频中每个说话者的独自音频流。
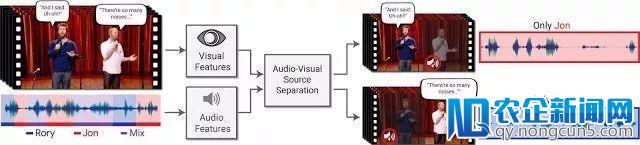
该实验中,输出是一名或多名发声对象,同时被其他对象或喧闹背景所搅扰的视频。输入的是将输出视频的音轨分解成纯洁的音轨,并对应上相应的说话者。
所谓的音频-视觉语音别离模型,就是增强选中人的语音,同时削弱同一工夫其别人的音量。该办法适用于具有单一(主)音轨的罕见视频,用户也可以自行选择倾听对象来生成对其的单一音轨,或许基于语境由算法停止对特定发声对象停止选择。
而在模型训练进程中,网络零碎(辨别)学习了视觉和音频信号的编码,然后将它们交融在一同构成一个音频-视觉表现。经过这种表现,网络零碎可以学会为每位发声对象对应输入时频掩码。输入的时频掩码与噪声输出频谱图相乘,随后转换成时域波形,从而构成每一位说话者独自纯洁的音频信号。
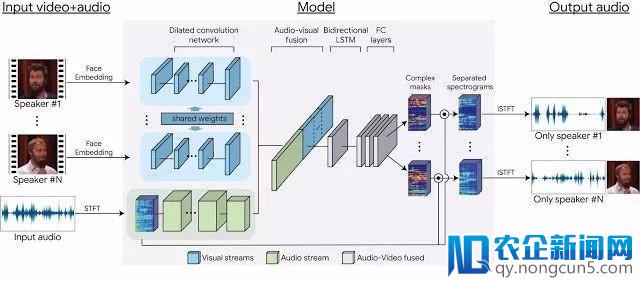
基于神经网络模型架构
此外,在多人发声的场景下,视觉信号除了无效提升语音别离的质量,还可以把别离之后的音轨和视频里的人物对应起来。此种方式为其后的语音辨认范畴提供了许多的能够性。
处理“鸡尾酒会效应”这一难题意味着什么?
“鸡尾酒会效应”难题的处理为语音辨认范畴的许多成绩提供了考虑途径,同时视觉-音频网络辨认零碎的提出,也为人声别离提供了视觉+听觉的处理方式。
随着技术落地,当人声别离技术真正使用于市场中会对产品有哪些改动呢?智能绝对论剖析师柯鸣以为,其在以下四个方面会有较大打破。
- 一、助力CC(隐藏式字幕)开展
隐藏字幕(Closed Captioning)是电视节目和电影中为有特殊状况或许需求的观众预备的字幕,其可以起到用解释性言语描绘画面的作用。
Caption 这个词,有辅佐听力妨碍的人士意图。Caption普通还包括了效果音的提示,这些声响正常人可以分辨,而关于妨碍人士则必需经过字幕。
比方美国的「谣言终结者」节目,除了可以看到「TV PG」分级标签以外,也显示了 CC 标志标明节目提供隐藏式字幕,以此来效劳那些需求特殊协助的群体。
《谣言终结者》
异样,谷歌人声别离技术关于促进CC开展有较大前景。多通道零碎中关于特定人声的别离可以简化节目、电影制造流程,其在语音辨认的预处置,以及视频字幕方面能发生良好效果。
关于视频自动字幕加载零碎而言,多名发作者同时发声招致的语音堆叠景象是一项已知的应战,与此同时,将音频别离至不同的源也有助于出现愈加精确和易读的字幕。人声别离技术可以在语音原声的根底上直译出各个对话主题的声响,并将其分开,应用AI完成字幕自动化,这极大水平上保证了字幕的同步性与精确性。
- 二、降低AI同传“乌龙率”
在2018年博鳌论坛上,腾讯AI同传搞了一个大乌龙。除了翻译不精确的成绩不测,现场还被曝光翻译零碎解体“抽风”,呈现乱码的状况,让现场相当为难。
预先,腾讯指出:呈现此种乌龙的缘由在于中英双语切换频率的成绩。当声源在两种言语之间不时转换时,后台中、英文辨认引擎就会同时开端任务,这会招致两种辨认引擎相互“掐架”,语音辨认混乱。最终翻译后果只能选择一种言语停止输入,招致引发错误。
而人声别离技术的使用,似乎为AI同传中的人声辨认提供了一个无效的处理途径。关于多种言语的辨认流利化后,AI同传的质量也相应会失掉一定的进步。
- 三、或可为智能音响提供“保险箱”
智能音箱的问世,使得普通家庭进入了语音互动的时代,其运用的简易性甚至超越了智能手机。有业者以为,智能音箱将会取代智能手机,成为家庭自动化或许智能家居生活的入口,自然言语对话将成为主流和高效率的用户界面。
与此同时,智能音响在使用进程中,也面临着诸多应战,其次要表现在语音辨认技术、声纹辨认等诸种技术上。目前,智能音箱的技术难题在于语音辨认技术如何在喧闹的环境中辨认语音指令——包括酒吧和体育场等人声鼎沸的场景。
为此,微软在Xbox上部署了一款名为Voice Studio的使用,专门搜集人们在玩游戏或看电影时的对话信息。为了吸援用户奉献本人在玩游戏进程中的对话内容,该公司为参与其中的用户提供了各种各样的奖励,包括点卡和游戏道具。
但是,效果并不尽善尽美。如何在喧闹环境辨认人声、如何辨别多人声响仍然是智能音箱的难题。日后,随着智能家居的普及,智能音响成为了物联网环境下与其他家居沟通的“钥匙”,而AI人声别离技术的使用,攻克技术成绩的同时也为智能音响提供了一个平安性较强的“保险箱”。
- 四、为无人驾驶提供仿生启示
“鸡尾酒会效应”在植物界的使用为无人驾驶提供一定启示。以蝙蝠规避妨碍和捕食为例,其在飞行进程中会发射一系列超声波,超声波遇到妨碍后反射回来,蝙蝠经过感知反射信号抵达两耳的工夫差来判别妨碍物的方向,经过感知反射信号的强度来判别妨碍物的间隔。
蝙蝠收回的超声信号普通是在110kHz的一个扫频信号,经过感知不同频率信号的衰减水平,就可以区分妨碍物的材质,进而可以判别妨碍物能否为捕食对象。
蝙蝠是如何区分本人和别人收回的超声波信号的呢?迷信家经过研讨发现,蝙蝠并没有改动收回的超声频率,而是经过叫声变大,继续工夫变长,发射频率增多等方式来处理的。
植物界的“鸡尾酒会效应”启示无人驾驶:想进步雷达的定位精度,进步信噪比是基本。比方,蝙蝠叫声变大,相当于进步了信号的能量;而叫声继续工夫变长和叫声频率增多,则是添加了信号的样本点数。在噪声不相关的状况下,经过复杂的均匀就可以降低噪声的影响。
这一点,将会为机器人和无人驾驶汽车带来了新的启示。

无人驾驶的激光雷达探测
此外,视觉-音频语音辨认别离模型使用于无人驾驶范畴能大水平进步雷达、激光等间隔传感器测量出路面信息的功能,而这正是无人驾驶平安保证的根底。
随着日后无人驾驶的普及,人声别离形式或可衍生出“雷声别离”,将雷达误收风险降到最低,从而保证无人驾驶妨碍辨认方面的平安性。
固然,新技术的使用需求一段工夫。谷歌官方目前也表示:“正在探究运用这个技术到谷歌系列产品中去”。随着“鸡尾酒会”难题的处理,AI语音辨认将会有长足停顿。详细投入产品后表现怎样,还需求市场来检验。(本文首发钛媒体)
【钛媒体作者:智能绝对论(微信id:aixdlun),文/柯鸣】
更多精彩内容,关注钛媒体微信号(ID:taimeiti),或许下载钛媒体App
