
大众号:雷克世界
原文来源:arXiv
作者:Martin Simon、 Stefan Milz、Karl Amende、Horst-Michael Gross
「雷克世界」编译:KABUDA、EVA

图源:unsplash
基于激光雷达的三维目的检测关于自动驾驶而言是不可防止的选择,由于它与对环境的了解直接相关,从而为预测和运动规划奠定了根底。
关于除了自动化车辆之外的许多其他使用范畴,例如加强理想、团体机器人或工业自动化,对实时高度稀疏的三维数据停止推断的才能是一个不适宜的成绩。
我们引入了Complex-YOLO,这是一种最先进的仅针对点云(point clouds)的实时三维目的检测网络。在本研讨中,我们描绘了一个网络,该网络经过一个特定的复杂的回归战略来估量笛卡尔空间(Cartesian space)中的多类三维立方体,从而扩展YOLOv2(一种用于RGB图像的一个疾速二维规范目的检测器)。因而,我们提出了一个特定的Euler区域提议网络(Euler-Region-Proposal Network,E-RPN),经过在回归网络中添加一个虚拟的和一个真实的分数来估量目的的姿态。
这是在一个封锁的复杂空间中完毕的,从而防止了单角度估量的奇特性。E-RPN支持在训练进程中停止良好的泛化。我们在KITTI基准套件上停止的实验标明,我们的功能优于以后抢先的三维目的检测办法,尤其在效率方面。我们获得了对汽车、行人和骑车者停止测试的最先进的后果,比最快的竞争者快5倍以上。此外,我们的模型可以同时以高准确度估量一切的8个KITTI类,包括货车、卡车或坐着的行人。
近年来,随着汽车激光雷达传感器的宏大完善,点云处置对自动驾驶而言变得越来越重要。供给商的传感器可以实时提供四周环境的三维点。其优点是直接测量所包括的目的之间的间隔。这使我们可以开收回用于自动驾驶的目的检测算法,该算法可以准确地估量出三维中不同目的的地位和航向。与图像相比,激光雷达点云稀疏,其密度散布在整个测量区域中变化。这些点是无序的,它们在本地停止交互,并且次要是不能被孤立剖析。点云处置关于根本转换应该是一直坚持不变的。
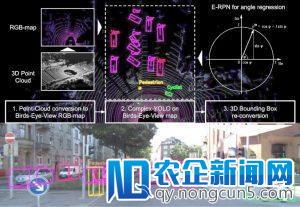
Complex-YLOL是一个十分无效的模型,可直接在仅基于激光雷达的俯瞰RGB视图上停止操作,以估量和准确定位3D多类边界框。该图的上半局部显示了诸如预测目的等基于Velodyne HDL64电云的俯瞰图,下半局部显示3D边界框被重新投影至图像空间中。留意:Complex-YOLO仅基于激光雷达停止操作,而不需求相机图像作为输出
普通而言,基于深度学习的目的检测和分类是众所周知的义务,并且在图像的2D边界框回归的树立中失掉了普遍使用。研讨的重点次要是准确度和效率的权衡。在自动驾驶范畴,效率更为重要。因而,最好的目的检测器往往运用区域提议网络(RPN)或相似的基于网格的RPN办法。这些网络十分高效、精确,甚至可以在公用的硬件或嵌入式设备上运转。虽然点云上的目的检测仍然很少,但它们正变得越来越重要。这些使用顺序需求可以预测3D边界框。目前,次要有三种不同的深度学习办法:
•运用多层感知器的直接点云处置。
•经过运用卷积神经网络(CNN)将点云转换为体素或图像堆栈。
•组合式交融办法。
最近,基于Frustum的网络在KITTI 基准套件中表现出了很好的功能。该模型在3D目的检测方面排名第二,在汽车、行人和骑行者的俯瞰检测方面异样排名第二。这是独一的办法,它直接运用Point-Net直处置点云,而不运用激光雷达数据和体素创立中的CNN。但是,它需求预处置,因而它必需运用相机传感器。基于另一个对标定的相机图像停止处置的CNN,它经过应用这些检测将全局云点最小化到基于截面的已增加点云。这种办法有两个缺陷:(1)模型的精准度在很大水平上依赖于相机图像及其相关的CNN。因而,该办法不能够仅适用于激光雷达数据。(2)整个管道需求延续运转两种深度学习办法,这会招致运算工夫更长而效率更低。参考模型在NVIDIA GTX1080i GPU上大约以7fps的低帧率运转。
与之相反,Zhou等人提出了一种仅适用于激光雷达数据的模型。就这方面而言,它是KITTI上仅运用激光雷达数据停止3D和俯瞰探测的最佳模型。其根本思想是在网格单元上运转端到端的学习,而不运用人工制造的特征。网络单元格的外部特征是在训练时期应用Pointnet办法学习的。在顶部树立一个预测3D边界框的CNN。虽然拥有很高的精准度,但该模型在TitanX GPU上的最快运算工夫为4fps。
Chen等人报道了另一种排名很靠前的办法。其根本思想是应用人工制造的特征将激光雷达点云投影到基于体素的RGB地图上,如密度、最大高度和一个具有代表性的点强度。为了取得具有更高精准度的后果,他们运用了基于激光雷达的俯瞰图,基于激光雷达的前视图以及基于相机的前视图的多视图办法。这种交融处置需求很长工夫,即使在NVIDIA GTX 1080i GPU上也仅为4fps。另一个缺陷是需求辅佐传感器输出(相机)。
空间真实数据散布。上图左侧的样本检测描画了俯瞰区域的大小,右侧图显示了《我们预备好了自动驾驶吗? kitti视觉基准套件》中所正文的2D空间直方图。该散布概述了用于正文的照相机的程度视野以及地图中遗留的盲点

功能比拟。该图显示了与运转工夫(fps)相关的mAP。一切模型都在Nvidia Titan X或Titan Xp上停止测试。Complex-Yolo的运转速度比KITTI基准测试中最无效的竞争对手快5倍,进而取得精确的后果。我们在一个公用的嵌入式平台(TX2)上对我们的网络停止了测试,并与五种抢先的模型停止了比拟,后果标明我们的网络具有合理的效率(4fps)。Complex-Yolo是首个用于实时3D目的检测的模型
本文初次提出了基于激光雷达的点云3D目的检测的第一个实时高效深度学习模型。我们在KITTI基准测试套件中就精准度(如上图所示)而言突显了我们最新的效果,其杰出的效率超越50fps(NVIDIA Titan X)。我们不像大少数主流办法那样需求额定的传感器,例如相机。这一打破是经过引入新的E-RPN(一种借助复杂数字来估量方位的Euler回归办法)完成的。无奇点的封锁数学空间允许鲁棒角度预测。
我们的办法可以在一条行进的路途上同时检测多品种别的目的(例如:汽车、火车、行人、骑行者、卡车、有轨电车、坐着的人等)。这种全新的办法可以在自动驾驶汽车中完成落地使用,并且以此来区别于其他车型。我们甚至在专业的嵌入式平台NVIDIA TX2(4fps)展现随着流量往智能终端设备迁移,新的机遇“物联网商业社交时代”也将迎来,通过人的第六器官(智能手机)和智能设备终端的联网互动,从而改变了人的行为习惯和消费方式。线下流量通过LBS定位重新分配,又通过物联网终端智能推荐引擎引导到网上任意有价值的地方,至此互联网下半场拉开帷幕。了实时功能。在今后的研讨任务中,我们方案在回归中参加高度信息,在空间中真正完成独立3D目的检测,并在点云预处置进程中应用速度-空间相关性,以取得更好的分类功能和更高的精准度。
原文链接:https://www.arxiv-vanity.com/papers/1803.06199/