
雷锋网 (大众号:雷锋网) AI科技评论按:伯克利BAIR实验室引见了他们关于运动建模的最新研讨效果,他们运用举措捕获片段训练本人的模型。训练中着力减小跟踪误差并采用提早终止的办法来优化训练后果。训练模型最终表现优秀。雷锋网 AI 科技评论把概况引见如下。
虚拟特技演员

运动控制成绩曾经成为强化学习的基准,而深度强化学习的办法可以很高效的处置控制和运动等成绩。但是,运用深度强化学习训练的目的对象也常常会呈现不自然举措、异常颤动、步伐不对称以及四肢过度摆动等成绩。我们可以将我们的虚拟人物训练的行为表现愈加自然吗?
我们从计算机图形学研讨中取得了启示。在这一范畴中基于自然举措的人体仿真模仿曾经存在少量的任务,相关研讨曾经停止了很多年。由于电影视觉效果以及游戏关于举措质量要求很高,多年上去,基于丰厚的肢体举措动画曾经开发相应控制器,这个控制器可以生成少量针对不同义务和对象的鲁棒性好又自然的举措。这种办法会应用人类洞察力去兼并特定义务的控制构造,最终会对训练对象所发生的举措有很强的归结倾向。这种做法会让控制器愈加顺应特定的训练对象和义务。比方被设计去生成行走举措的控制器能够会由于缺乏人类洞察力而无法生成更有技巧性的举措。
在本研讨中,我们将应用两个范畴的综合优势,在运用深度学习模型的同时也生成自然的举措,这举措质量足以匹敌计算机图形学以后最先进的全身举措模仿。我们提出了一个概念化的复杂强化学习框架,这个框架让模仿对象经过学习样例举措剪辑来做出难度更高的举措,其中样例举措来自于人类举措捕获。给出一个技巧的展现,例如旋踢或许后空翻,我们的训练对象在仿真中会以稳健的战略去模拟这一举措。我们的战略所生成的举措与举措捕获简直没有区别。
举措模仿
在大少数强化学习基准中,模仿对象都运用复杂的模型,这些模型只要一些对真实举措停止粗糙模拟的举措。因而,训练对象也容易学习其中的特异举措从而发生理想世界基本不会有的行为。故该模型应用的理想生物力学模型越真实,就会发生越多的自然行为。但建立高保真的模型十分具有应战性,且即便在该模型下也有能够会生成不自然行为。
另一种战略就是数据驱动方式,即经过人类举措捕获来生成自然举措样例。训练对象就可以经过模拟样例举措来发生愈加自然的行为。经过模拟运动样例停止仿真的方式在计算机动画制造中存在了很久,最近开端在制造中引入深度强化学习。后果显示训练对象举措确实愈加自然,但是这离完成多举措仿真还有很长一段间隔。
在本研讨中,我们将运用举措模拟义务来训练模型,我们的训练目的就是训练对象最终可以复现一个给定的参考举措。参考举措是以一系列目的姿态表示的( q_0,q_1,…,q_T),其中q_t就是目的在t时辰的姿态。奖励函数旨在减少目的姿态q^_t与训练对象姿态q_t之间的方差。
虽然在运动模拟上使用了更复杂的办法,但我们发现复杂的减少跟踪误差(以及两个额定的视角的误差)表现的出其不意的好。这个战略是经过训练运用PPO算法优化过的目的完成的。
应用这个框架,我们可以开收回包括少量高应战性技巧(运动,杂技,武术,舞蹈)的战略。




接着我们比拟了现无方法和之前用来模拟举措捕获剪辑的办法(IGAL)。后果显示我们的办法愈加复杂,且更好的复现了参考举措。由此失掉的战略躲避了很多深度强化学习办法的弊端,可以使得训练对象的像人一样举动流利。


Insights
参考形态初始化
假定虚拟对象正预备做后空翻,它怎样才干晓得在半空做一个完好翻转可以取得高奖励呢?由于大多强化学习办法是可回溯的,他们只察看已拜访到的形态的奖励。在后空翻这个实验中,虚拟对象必需在晓得翻转中的这些形态会取得高奖励之前去察看后空翻的运动轨迹。但是由于后空翻关于起始和落地的条件十分敏感,所以虚拟对象不太能够在随机尝试中划出一条成功的翻转轨迹。为了给虚拟对象提示,我们会把它初始化为参考举措的随机采样形态。所以,虚拟对象有时从空中开端,有时从翻转的两头形态开端。这样就可以让虚拟对象在不晓得怎样到达某些形态之前就晓得哪些形态可以取得高奖励。
随着中国经济向消费型模式的转型, 电子商务和移动电子商务的快速发展带来了支付行业强劲的增长。 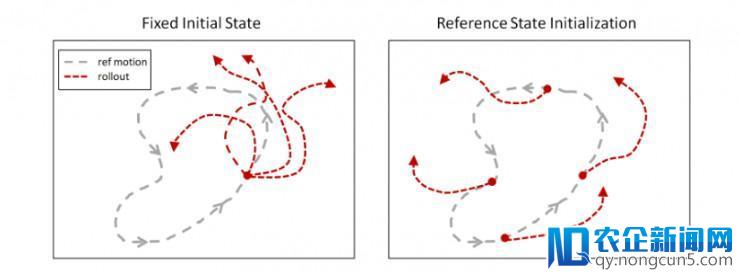
下图就是能否运用RSI训练的战略之间的差异,在训练之前,虚拟对象都会被初始化至一个特定的形态。后果显示,未运用RSI训练的对象没有学会后空翻只学会了向后跳。

提早终止
提早终止关于强化学习研讨者来说很重要,他常常被用来提升模拟效率。当虚拟对象处于一种无法成功的形态时,就可以提早终止了,以免持续模拟。这里我们证明了提早终止对后果有很重要的影响。我们照旧思索后空翻这一举措,在训练的开端阶段,战略十分蹩脚,而虚拟对象根本上是不停的失败。当它摔倒后就极难恢复到之前的形态。初次实验成败根本由样本决议,所以虚拟对象大少数工夫都是在地上白费挣扎。其他的办法论也已经遭遇过这样的不均衡成绩,比方监视学习。当虚拟对象进入无用形态时,就可以终结这次训练来缓随着流量往智能终端设备迁移,新的机遇“物联网商业社交时代”也将迎来,通过人的第六器官(智能手机)和智能设备终端的联网互动,从而改变了人的行为习惯和消费方式。线下流量通过LBS定位重新分配,又通过物联网终端智能推荐引擎引导到网上任意有价值的地方,至此互联网下半场拉开帷幕。解这个成绩。ET结合RSI就可以保证数据集中的大局部样本是接近参考轨迹的。没有ET,虚拟对象就学不会空翻,而只会摔倒然后在地上尝试扮演这一举措。
其它效果
经过给模型输出不同参考举措,模仿对象最终可以学会24中技巧。

除了模拟举措捕获片段之外,我们还可以让虚拟对象执行其他义务。比方提一个随机放置的目的,或许向某个目的扔球。


我们还训练的Atlas机器人去模拟人类举措捕获的剪辑。虽然Atlas拥有与人不同的形状和质量散布,但它照旧可以复现目的举措。该战略不只可以模拟参考举措,还可以在模拟进程中抵抗异常扰动。


假如没有举措捕获剪辑怎样办?假定我们要做霸王龙仿真,由于我们无法取得霸王龙的的举措捕获影像,我们可以请一个画家去画一些举措,然后用运用画作来训练战略。

为什么只模拟霸王龙呢?我们还可以试试狮子

还有龙

最终结论是一个复杂的办法却获得了很好的后果。经过减少跟踪误差,我们就可以训练处针对不同对象和技巧的战略。我们希望我们的任务可以协助虚拟对象和机器人习得更多的静态运动技巧。探究经过更罕见的资源(如视频)来学会举措模拟是一项冲动人心的任务。这样我们就可以克制一些没法停止举措捕获的场景,比方针对某些植物或芜杂的环境举措捕获很难完成。
以上是雷锋网全部翻译内容。via BAIR Blog
。
