
雷锋网 AI 科技评论按:Hinton 团队最近宣布了一篇关于「在线蒸馏」的新论文。论文里讲了什么呢?
我们为什么需求在线蒸馏?
近年来,随着深度学习技术的蓬勃开展,我们日常生活的每个角落都充溢了「人工智能」的影子,并由此催生了许多新的业态、以人工智能使用为中心产品的初创公司也如雨后春笋般在科技行业中崭露头角。是的,这也许是人工智能(特别是深度学习)最好的时代。
但是,深度学习作为当古人工智能范畴皇冠上最灿烂的明珠,假如要想将其推向工业级的使用,则往往需求可望而不可及的弱小算力!而这种算力则是由价钱昂扬的硬件、庞大而复杂的散布式计算环境、精妙高效的算法作为支撑的。可想而知,除了 Google、Amazon、阿里巴巴、百度等掌握弱小计算资源的科技巨头外,想取得这样的计算资源关于小型企业或许团体用户可谓是天方夜谭。实践上,在很多普通的初等院校和科研单位中,拥有像 Titan X 或 GTX 1080 Ti 这样的民用显卡曾经是很朴素的事情。更重要的是,由于根底架构的限制(散布式计算节点的通讯、同步、义务调度等成绩)、对模型停止优化求解的妨碍、集成学习环境下各模型的奉献缺乏好的决策,使得自觉的堆砌计算资源也能够触碰到模型功能的天花板(例如:散布式随机梯度下降(distrtibuted SGD))。
为此,「深度学习泰斗」Geoffrey E.Hinton 近年来在知识蒸馏(或许「暗知识提取」)方面做了一系列任务,试图经过这种从高计算才能要求、同时也具有高表现的模型中提取出一些隐含的知识,并且将其作为先验,经过设计新的网络构造和目的函数将这种知识「教授」给规模较小的深度学习网络,完成对网络模型的紧缩,以明显减少的网络规模和计算需求展示出尽量高的模型表现。最近,为了将这种思想部署在散布式环境中,用以打破如今经常被运用的散布式 SGD(同步和异步方式)的瓶颈,Hinton 团队又发布了名为 「 LARGE SCALE DISTRIBUTED NEURAL NETWORK TRAINING THROUGH onLINE DISTILLATION 」(经过在线蒸馏的神经网络大规模散布式训练) 的论文。在笔者看来,Hinton 的这一系列任务进一步降低了深度学习模型使用的门槛,之前的研讨对深度学习模型在挪动终端上的部署、这篇论文对进步大规模计算集群上的模型表现和计算效率都有深远意义。

论文地址: https://arxiv.org/abs/1804.03235
知识蒸馏的前世今生
要想了解「在线蒸馏」的概念,我们有必要回忆一下 Hinton 从 2014 年开端对 dark knowledge extraction(暗知识提取) 和 knowledge distillation(知识蒸馏)的相关任务,甚至更早的 Caruana et.al 所做的模型紧缩的任务。
为了提升神经网络模型的功能,Caruana 等人早在 2006 年(那时深度学习还没有大火)就提出了一种紧缩大规模复杂网络的办法。由于集成学习在传统的机器学习范畴大获成功,许多深度学习研讨人员很自然地想要应用集成学习的思想,将少量的模型聚合到一个神经网络中,经过暴力的训练,为不同的模型赋予不同的权值,对这些模型的输入停止加权均匀失掉最终的后果,以便充沛应用它们各自关于不同的义务所具有的优势。但是,这种暴力的训练进程和臃肿的网络构造需求耗费宏大的计算资源、形成额定的动力耗费。Caruana 等人提出了 MUNGE 的数据加强算法,将大规模模型学习到的函数紧缩进规模更小、训练更便捷的模型中。
受此启示,时隔 8 年后,当深度学习迎来春天、人们陶醉于大规模深度学习网络带来的人工智能在计算机视觉、自然言语处置等方面的成功使用的时分,宗师 Hinton 则以为,是时分回过头来看看 Caruana 的文章,考虑如何将这些「漂亮的」大规模的模型紧缩到小而快的模型中去。
由此,Hinton 提出了「dark knowledge」的概念。在他看来,这种被称为「暗知识」的东西才是深度学习实质上学到的知识(或许这也是寻求深度学习可解释性的一种途径)。Dark knowledge,望文生义,就是隐藏在深度学习外表上所展示出来的网络构造、节点之间的衔接权重、网络的输入这些看失掉的数据之下的知识。 假如可以找到一种途径,使得我们可以获取这种知识,并且将其包装成一种先验概率,迁移到更小的模型中去,能否可以提升小模型的功能呢?现实上,笔者以为,这也可以看作是在迁移学习的框架下,将大规模网络视作信息充沛的 source domain,将小规模网络视作需求大规模网络补充信息的 target domain,而我们提取到的 dark knowledge 则是两个义务之间的 common knowledge。
但是,该从哪里下手,获取这种知识呢?Hinton 敏锐地察看到:我们在绝大少数的预测义务的深度学习网络中,都会运用 softmax layer 为少量的标签分配概率散布。但是这种处置方式存在一个负作用:与正确标签相比,模型为一切的误标签都分配了很小的概率;但是实践上关于不同的错误标签,其被分配的概率依然能够存在数个量级的悬殊差距。例如:在图片分类成绩中,我们要将图片分红猫、狗、老虎三类。在一次训练中,我们给三类分配的概率辨别为 [0.0010, 0.0001, 0.9989],从而最终失掉 [0,0,1] 的 one-hot 编码作为分类后果(即 hard-target),我们以为图片所代表的是一只老虎。但是,softmax 函数输入的概率往往包括着类别之间潜在的相关性。在这个例子中,我们可以看到,图片能够是猫的概率比图片是狗的概率更接近图片是老虎的概率,这阐明猫和老虎之间存在的内在联络愈加弱小。相似地,Hinton 也举例说:在辨认一辆宝马汽车的图片时,分类器将该图片辨认为清洁车的概率是很小的,但是这种概率比起将其辨认为胡萝卜的能够是会大出很多。由于在微观上由于这些概率都很小,这一局部的知识很容易在训练进程中吞没,这无疑是糜费了重要的可以用于将大规模网络的知识迁移到小规模网络中去的珍贵先验概率。
为了充沛应用这品种类别之间的相关性,我们需求经过某种方式去改动概率散布,使其愈加陡峭。而 Hinton 仅仅对我们常常运用的 softmax 函数停止了一点点修正,就到达了这一目的,他终究是怎样做的呢?
现实上,如上面的公式所示,Hinton 向 softmax 函数添加了一点「佐料」——参数「T, 温度」(如今 T 曾经成为了许多深度学习模型的标配,例如在生成文本的 RNN 中进步 T 可以添加生成文本的多样性):

其中,z 为每一个类别输出的 logit。式中 T=1 时,退步成传统的 softmax;T无量大时,后果趋近于 1/C,即一切类别上的概率趋近于相等。T>1 时,我们就能取得 soft target label。经过进步 T,softmax层的映射曲线愈加陡峭,因此实例的概率映射将更为集中,便使得目的愈加地「soft」。
有了这个 distillation 的内核,Hinton 依照以下的步骤对大规模网络停止「蒸馏」:
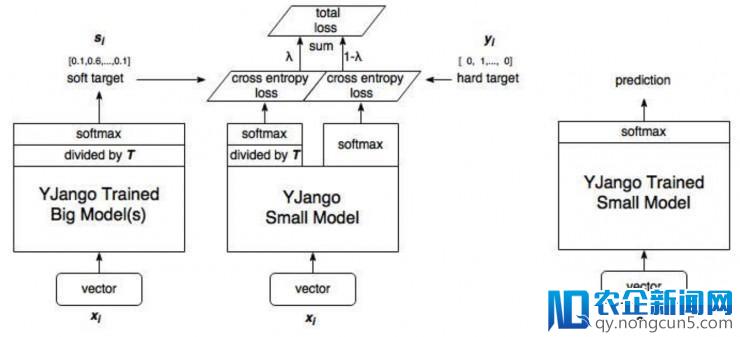
知识蒸馏表示图(图片来自网络: https://www.zhihu.com/question/50519680,本图作者YJango)
1. 训练大模型:先用 hard target(相似于 [0,0,1] 的 one-hot 编码)的样本训练。
2. 计算 soft target:应用训练好的大模型来计算 soft target 。也就是大模型「硬化后」再经过 softmax 的输入。
3. 重新创立一个小的网络,该网络最初有两个 loss,一个是 hard loss,即传统的 softmax loss,运用 one-hot label;另外一个是 soft loss,即 T>1 的 softmax loss,运用我们第二步保管上去的 soft target label。
全体的 loss 如下式:
其中
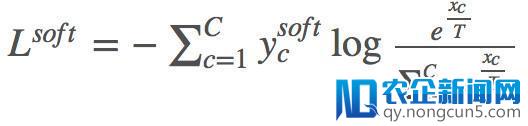
为第二步输入的 soft label。
用「硬化」训练集训练小模型。训练小模型时 T 不变依然较大,训练完之后 T 改为1。
4. 预测时,将训练好的小模型按惯例方式运用。
如今我们可以把 Hinton 的办法和下图所示的最后 knowledge distillation 的由来作个比照。
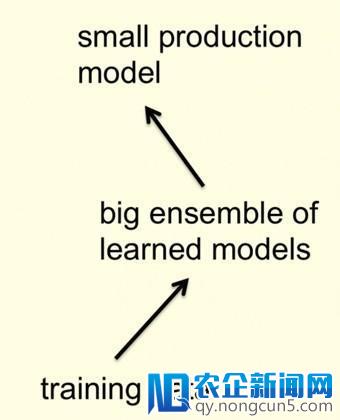
可见,实质上这相当于对数据停止了加强(augmentation),参加了类别之间的关联性的先验信息。将大规模网络学习到的这种关系包装在数据中,用这种更强的数据来训练小规模的模型,充沛思索到了类间的间隔和类内的方差信息。从而提升了小规模模型的功能,到达了「蒸馏」的效果。与直接运用预训练模型的构造和权重相比,这是一种绝对更「初级」的知识迁移的方式。
在线蒸馏?新瓶装旧酒?
工夫的车轮一眨眼就驶向了 2018 年,随着挪动终端上的深度学习等使用的呈现,网络模型紧缩成为了一个广受关注的范畴,少量的研讨者在 Hinton 的启示下,加入了 distillation 的诸多变形,停止了深化的优化。Hinton 则自始自终地尝试开辟更多新的深度学习范式;当然也能够是谷歌的计算资源太过充足所以遇到了他人没无机会遇到的成绩(给跪),Hinton 开端尝试在大规模散布式计算环境下运用「在线蒸馏(online distillation)」办法。这是由于目前的散布式 SGD 办法遇到了瓶颈。而本地的「蒸馏」算法也因其对数据管道的计算操作过于复杂而暴显露越来越多的成绩。
详细而言,在散布式 SGD 中,由于边沿效益递加的规律,添加参与训练的机器数量而取得的计算效率的提升渐突变小,直到毫有效果。另一方面,他们也想运用集成的深度学习模型进步预测的精确率。为了在不添加测试工夫本钱的状况下取得与集成学习同等的收益,他们对一个 n 路集成模型停止蒸馏(distill),失掉一个单一模型,这包括两个阶段:
-
运用 M 机器来训练散布式 SGD 的 n 路集成模型,然后运用 M 机器(T 不变)来训练 student 网络(小规模网络),这个小规模网络会模仿这个 n 路集成模型。
-
经过在训练进程中运用更多机器,蒸馏会添加训练工夫和计算复杂度,以换取接近更大的 teacher 集成模型的质量改良。
Hinton 他们将这种在线的蒸馏方式称为「codistillation」:即散布式环境中的每个节点之间都可以互为 teacher 和 student,并且相互提取内在的知识,用以提升其它节点的模型功能,详细的算法如下:

如算法 1 中所示,为了打破散布式 SGD 的瓶颈,Hinton 他们应用蒸馏算法进步了模型的训练效率。运用蒸馏办法更新一个网络的参数只需求对其他网络的预测后果,这些网络可以应用其他网络权重的正本停止本地计算。
值得留意的是,即便教员模型和先生模型是同一神经网络的两个实例,蒸馏也有益处,只需它们有足够的区别(比方,不同的初始化、以不同的顺序接纳输出样本;可以参见论文第 3 节的经历证据)。这也阐明这种「在线蒸馏」的办法是具有很强的普适性的。
Hinton 他们在这个任务中将蒸馏技术和散布式 SGD 相结合,从而使一个散布式 SGD 的任务组内的各个节点可以交流反省点(checkpoint)保管的网络信息,应用这种信息作为蒸馏出来的知识,经过「教师-先生」的训练,减速先生网络的训练。在这个进程中,先生节点和教师结点的角色是互换的,因而,各个网络相互促,进从而完成共同的蒸馏。
其实,就算「在线蒸馏」是新瓶装旧酒,那也是一个十分恰当的,闪闪发光的新瓶子。它应用蒸馏技术,降低了散布式 SGD 的通讯开支,成功进步了预测的精确率,提升模型的计算功能!
结语
笔者经过这篇文章和大家一同回忆了知识蒸馏的相关知识,并且深刻地理解了 Hinton 在这个范畴所做的最新任务。我们可以看到,Hinton 作为一代宗师,每次都可以以超越常人的目光发现研讨的新方向,并且提出复杂、美、效果杰出的处理方案,这与他对自然、对生物的神经零碎、对生活、对所面临的成绩的犀利的察看是密不可分的。这鼓励着一切的人工智能研讨者开辟视野、放飞心灵,充溢发明力地去探究新的未知范畴。雷锋网 AI 科技评论这样的学术媒体也会不时地把最新的学术研讨停顿引见给大家。
论文地址: https://arxiv.org/abs/1804.03235 ,雷锋网 (大众号:雷锋网) AI 科技评论报道
。
