
雷锋网按:本文为雷锋字幕组编译的论文解读短视频,原标题Learning Category-Specific Mesh Reconstruction from Image Collections,作者为Angjoo Kanazawa。
翻译 | 龙珂宇 字幕 | 凡江 整理 | 李逸帆 吴璇
论文标题:Learning Category-Specific Mesh Reconstruction from Image Collections
本篇引见的《从图像集合中学习特定类别的网格重建》是Angjoo Kanazawa最新论文的预印本。
Angjoo Kanazawa,加州大学伯克利分校BAIR(Berkeley AI Research)的博士后。她的论文《狮子、老虎、熊:从图像中捕获非刚性的3D平面外形》、《SfSNet :“在自然状况下”学习脸部外形、反射比、照明度》都被收录在CVPR 2018。
不断以来,Angjoo的研讨重点都是包括人类在内的植物单视图三维重建。比方,我们如何可以经过察看2D图像或视频,来推出三维模型?
如图所示,虽然这是一个二维的立体图片,但我们可以大致推断出它的3D轮廓,甚至可以想像出从另一个角度看它是什么样的。

在这次的任务中,我们的目的就是建造一个相似的计算模型。 从单张立体图片推断出3D模型的说法并不太精确,它仅在我们具有一只鸟长什么样的根底知识的状况下才能够完成。 原来的方法次要经过3D基准外形来取得这种根底知识,要么是绘制的分解图要么是物体的扫描图。 但不幸的是,这种扫描办法在实践上,很难用到活体对象下面,由于我们很难让他们配合我们的扫描,所以我们试图采用一种更自然的监视办法——就是少量的标注图片集合。

假定我们关于一个物体类别有少量的图片集,但关于每一个集体都只包括一个角度,每一张图片都被添加了一组语义描绘和正确的联系蒙版。从这个图片合集和蒙版上的标注,我们学习到一个预测器F,在给定一张新的未标注图片时,F可以推断它的3D外形并用网格表示,可以推断其观测视角,以及其网格构造。经过这些推断和预测,我们就失掉了关于这个物体3D外形的一个表示。从任何一个视角渲染这个模型,都可以把它直观地可视化。
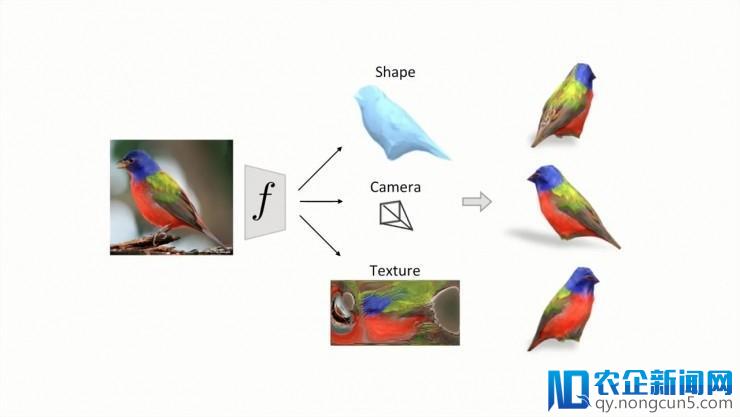
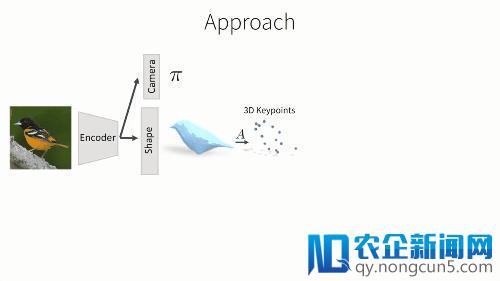
F是一个CNN神经网络,包括一个图像解码器和三个预测模块。 首先我们预测相机的观测视角,其参数由弱透视投影变化决议。第二个输入是物体的3D外形,它是一个和类别有关的形变模型。我们将学习到的该类级别模型和以后输出的预测形变相结合,然后取得输入的3D外形。这样一个类级别模型的益处在于——我们可以学习到如何关联语义标注和网格的格点,同时也能从预测外形中,取得3D关键点的地位。最初,我们还可以经过一张正则形状空间中的RGB图像表达,预测出它的纹理构造。
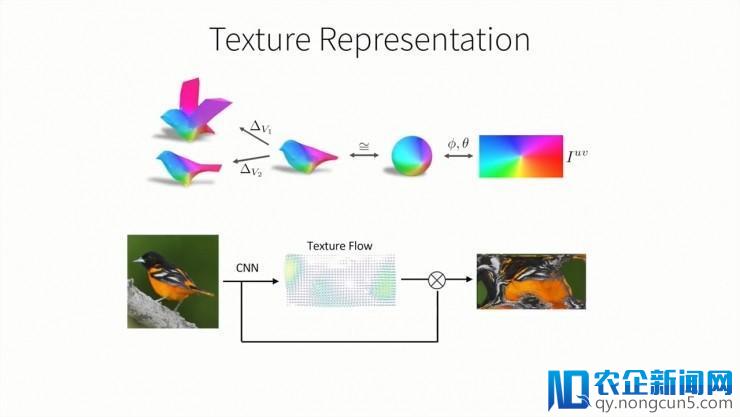
那么该如何,从这张二维图片中看出,我们对纹理构造的预测呢?我们留意到,一个类别中的不同外形其实只是均匀外形的一个形变,而其均匀外形可以被视为一个球体,其纹理可以用一张UV纹理图片来表示,就像把一个球体展开到二维立体上。UV图也可以被映射到球体上,然后被变化到均匀外形或许任何预测出的外形上。所以,为了预测外形的纹理,我们只需求预测UV图中的颜色,所以我们经过一个CNN构造来完成它。我们将输出图片编码后传入CNN,这里,我们并不是直接预测,纹理图片的像素信息,而是预测他的纹理流。
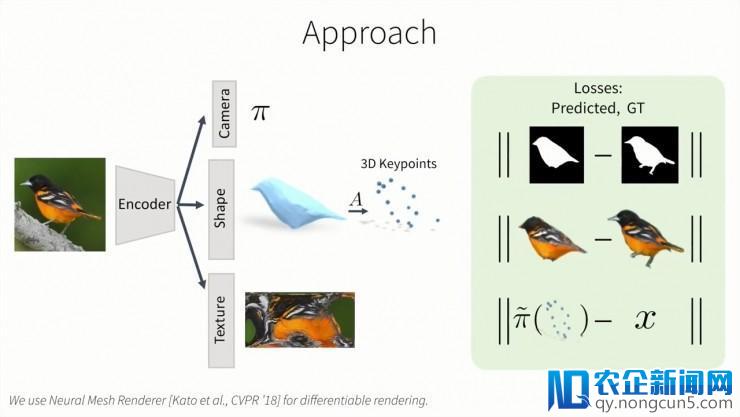
在取得预测信息之后,我们用异样的方法表示出我们的目的物体,然后使得预测值更接近真实值。我们最小化预测后果和真实后果的渲染蒙版,渲染图片和投影关键点之间间隔。我们运用神经网格渲染器,所以。一切损失函数都是可微的。同时我们也在模型中包括了一些先验信息,如对称性,外表的润滑性等等。
如今我们在测试集上向大家展现一些训练后果,给定一张输出图片,我们可以推断其在构造中的外形,这里展现了不同视角下的后果。我们的模型也可以捕获到不同的外形,比方说翅膀,和不同的尾部。我们也可以运用我们的后果,将一只鸟的纹理变化到另外一只鸟。比方说,给定这两只鸟的图片,我们首先重建它们的构造和纹理。由于纹理图是在正则形状空间中表示的,我们可以复杂地交流它们的纹理图。然后把第二只鸟的纹理变化到第一只鸟身上,反之同理,即便在鸟的外形不同的时分,我们也可以停止纹理变化的操作。比方说这里我们向大家展现一些不同测试数据上的重建后果,大家可以看到它们的360°图片。

雷锋网 (大众号:雷锋网) 雷锋网
视频旧址 https://www.youtube.com/watch?v=cYHQKtBLI3Q
论文旧址
https://arxiv.org/pdf/1803.07549.pdf
。
