
雷锋网 AI 科技评论按:以后,整团体工智能范畴对自然言语处置技术的热情可谓绝后低落。一方面,这是由于借着深度学习的西风,计算机在各种自然言语处置义务中的表现有了日新月异的进步;另一方面,人们生活中少量的信息检索、语音辨认、文本剖析等使用对粒度更细、精度更高的公用自然言语模型提出了越来越高的要求。可以预见,随着信息时代数据量的不时增长以及人类社会中语料资源的不时丰厚,自然言语处置研讨将不时面临新的应战。
已于近日完毕的 ICLR 2018 中的一篇关于智能问答零碎的论文《QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension》以优秀的表现吸引了我们的留意。在详细引见论文之前,我们也先对智能问答零碎这个研讨课题稍作回忆。
什么是问答零碎?
问答零碎实质上是一个信息检索(IR)零碎,只是它从文具中获取更多信息,前往愈加精准的答案。传统的问答零碎将依照以下的流程任务:(1)成绩解析(2)信息检索(3)答案抽取。成绩解析的任务包括分词、词性标注、句法剖析、命名实体辨认、成绩分类、成绩扩展等;信息检索则是以成绩解析模块的后果作为输出,从底层知识库重前往一系列相关的排序后的文档;答案抽取,望文生义,就是从文档中抽取出最终的答案。
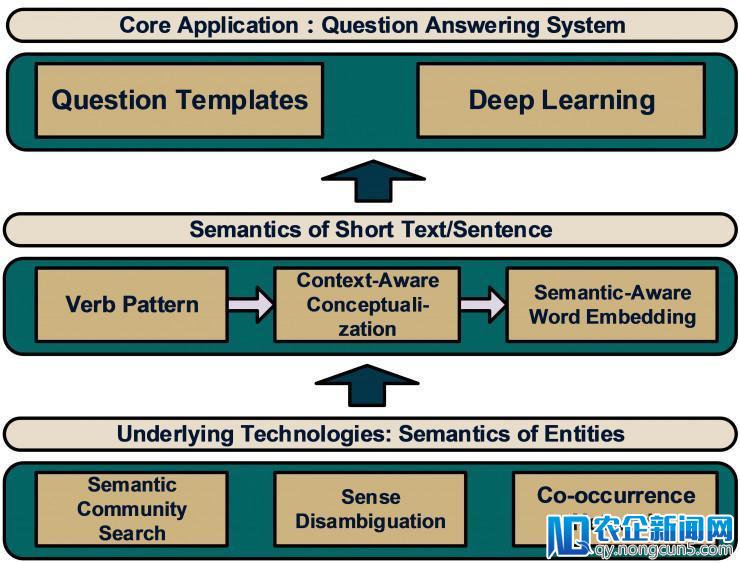
图 1. 传统问答零碎根本框架。最上层为实体层,为下层模型提供计算单元(语义社区搜索、语义消歧、词共现等);第二层为语义层,包括了具有一定语义信息的文本,提取出了一局部语义特征;第三层则是最终的中心使用局部。
不好看出,传统的问答零碎模型工序复杂,对人工的要求也较高,实行起来较为困难。每一道工序的质量都能够成为制约最终模型功能的要素,并且由于其级联误差的积聚,往往会招致模型的失败。而当今大热的深度学习关于序列性的成绩有着自然的优势(应用少量的训练数据学习到泛化的知识表示,对篇章和成绩从语义层面上停止高度的笼统),因而,人们自但是然地想到了用深度学习来替代问答零碎中的少量组件,例如:IBM 的研讨人员经过人工搭配迁移学习抽取一系列的特征,再将特征输出一个回归模型中,完成了用于 Watson 问答机器人的 DeepQa 算法。(概况见雷锋网文章: https://www.leiphone.com/news/201607/FOeUS5Wo5gIFMvwJ.html)
进而,为了降低模型运用门槛,同时也为了使模型外部担任各种功用的组件可以更好地协分配合,从而提升模型全体功能,越来越多的研讨者将一切的问答零碎功用封装在一个端到端的自动化问答零碎中。当然,我们并不是说传统的问答零碎研讨就得到了其研讨价值,现实上,传统的可解释性更强的问答零碎的研讨可以反哺端到端的深度学习问答零碎,从而为设计深度学习零碎提供更多启示和实际根据。
如火如荼的问答零碎竞赛:且从 SQuAD 说开去
其实,一部问答零碎开展史就是一部人工智能史。随同着人工智能的兴衰,问答零碎也阅历了半个多世纪的浮沉。此外,随着符号主义(代表算法为:关联规则、决策树等)、贝叶斯主义(代表算法为:概率图模型)、退化主义(代表算法为:遗传算法)、Analogizer(代表算法为:支持向量机)、联合主义(代表算法为:深度神经网络)轮番登上历史舞台的最顶峰,用于支撑问答零碎的中心算法也阅历了数次更迭,从而使得人们构建问答零碎的思绪不一。为了构建一个良好的问答零碎产学研生态圈,业界和学术界不断努力于提出质量更好的数据集、举行更有影响力的竞赛来促进该范畴的蓬勃开展。其中,斯坦福大学在 2016 年推出的数据集 SQuAD 成为了往年来最遭到学术界和工业界注目的分量级阅读了解数据集,可以说 SQuAD 之于问答零碎就好比 ImageNet 之于计算机视觉的意义。这个阅读了解数据集会给研讨者提供一篇篇文章,预备相应的成绩,而研讨者需求本人设计问答零碎模型用于给出成绩的答案。SQuAD 之所以备受推崇,得益于其宏大的规模,它包括 536 篇文章以及相关的 107,785 个成绩。(概况请见雷锋网 (大众号:雷锋网) 文章: 随着中国经济向消费型模式的转型, 电子商务和移动电子商务的快速发展带来了支付行业强劲的增长。 https://www.leiphone.com/news/201608/ftBdq445PzC1kxbF.html )此外,数据集采用 F1 值和 EM(exact match,完全婚配)两种分类规范来评价模型功能,保证了模型评价的绝对客观。

图 2: SQuAD排行榜
如上图所示,SQuAD 赛事吸引了微软、谷歌、阿里巴巴、科大讯飞等业界巨头和 CMU,哈工大等高校参与其中,排行榜上的名次常常处于变化之中。尤记得去年 7 月科大讯飞初次登顶该榜榜首,获得了 77.845 的 EM 以及 85.297 的 F1 值,一工夫风头无两,但是不久后这个成果就被其他机构逾越。往年年终,微软的 r-net 在 EM 目标上取得了 82.625 的高分,宣称初次在该目标上逾越了人类(依据斯坦福搜集的数据,人类的 EM 值为 82.304)。
直到最近,谷歌大脑团队和 CMU 结合推出的 QANet 再一次拔得头筹, 大幅度地将 EM 值进步至 83.877(第二名为科大讯飞和哈工大的 AOA reader 模型取得的 82.482), F1 值也取得了有史以来的最高分——89.737。另一方面,相比别的团队提交的模型在 DAWNBench 中动辄 7 到 10 个小时的训练工夫,QANet 只需求短短 45 分钟。
那么接上去我们一同来看看 QANet 终究是一个什么样的模型?作者们是如何同时大幅提升了精度和训练工夫的?
QANet 模型
(1)方式化定义
给定一个包括 n 个单词的上下文片段 C={c 1 ,c 2 ,...,c n },我们思索包括 m 个单词的查询语句 Q={q 1 ,q 2 ,...,q m },模型输入为一个包括 j 个单词的片段 C 中的答案区间 S={c i ,c i+1 ,...,c i+j }。
(2)模型概览
大体下去说,和现有的阅读了解模型相相似,QANet 包括五个次要的组成局部:嵌入层 (embedding layer),嵌入编码层(embedding encoder layer),语境-查询留意力层(context-query attention layer),模型编码层(model encoder)以及输入层(output layer)。
区别于目前大少数包括留意力机制(attention model)和循环神经网络(RNN)的阅读了解模型,QANet 的嵌入编码器和模型编码器摒弃了 RNN 的复杂递归构造, 仅仅运用卷积(convolution)和自留意力机制(self-attention)构建了一个神经网络 ,使得模型的训练速率和推断速率大大放慢,并且可以并行处置输出的单词。
卷积操作可以对部分互相作用建模(捕捉文本的部分构造),而运用自留意力机制则可以对全局交互停止建模(学习每对单词之间的互相作用)。据作者们引见,这也是范畴内初次将卷积和自留意力机制相结合。由于卷积层和自留意力机制都没有耗费工夫的递归操作,所以作者们不只大胆地把模型深度添加到了问答义务中史无前例的超越 130 层,同时还在训练、推理中都无数倍的速度提升。(相较于基于 RNN 的模型,训练速度提升了3-13倍,推理速度提升了 4-9 倍)
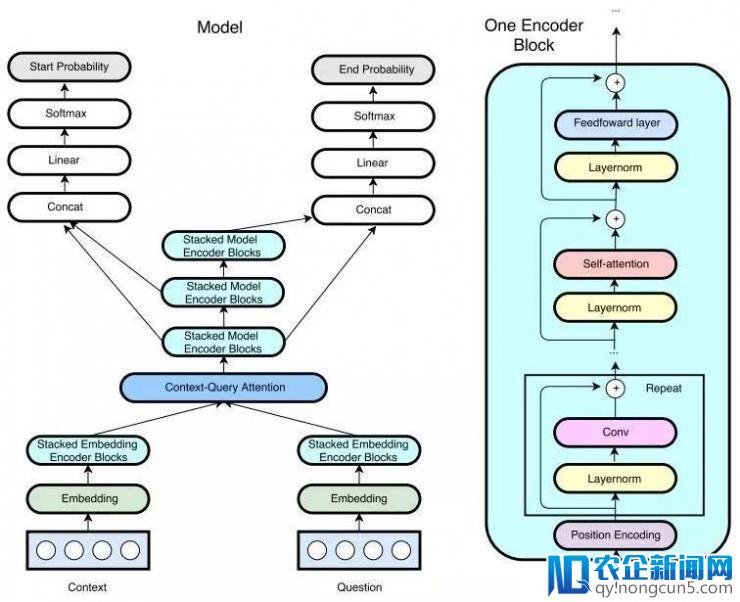
图 3: 左图为包括多个编码器模块的 QANet 全体架构。右图为根本编码器模块单元,QANet 所运用的一切编码器都是依照这个形式构建的,仅仅修正模块中卷积层的数量。QANet 在每一层之间会运用层正则化和残差衔接技术,并且将编码器构造内地位编码(卷积、自留意力、前馈网络等)之后的每个子层封装在残差模块内。QANet 还共享了语境、成绩、输入编码器之间的局部权重,以到达知识共享。
以往基于 RNN 的模型受制于训练速度,研讨员们其实很少思索图像辨认义务中相似的「用更大的数据集带来更好表现」的思绪。那么关于这次的 QANet,由于模型有令人称心的训练速度,作者们得以手脚,运用数据加强技术对原始数据集停止了扩大,大小气方用更少数据训练了模型。
详细来说,他们把英文原文用现有的神经机器翻译器翻译成另一种言语(QANet 运用的是法语)之后再翻译回英语。这个进程相当于对样本停止了改写,这样使得训练样本的数量大大添加,句式愈加丰厚。
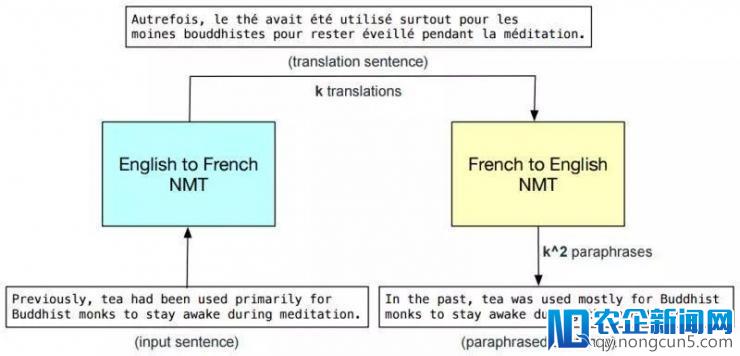
图 4: 数据加强示例。k 为 beam width,即 NMT 零碎发生的译文规模。
详细引见 self-attention
读罢上文,你能够惊叹于「卷积+自留意力机制」的神奇效果,即使思索到更多训练数据的协助,也依然可以直接应战运用已久的 RNN 模型。「卷积」是大少数深度学习的研讨者非常熟习的概念,它用于提取部分的特征。那么,自留意力(self-atteition)机制又是何方神圣呢?它在 QANet 中起到了什么关键性的作用?
要想弄清 self-attetion 机制,就不得不从 attention 机制的原理谈起,由于 self-attention 望文生义,可以看作attention 机制的一种外部方式的特例。
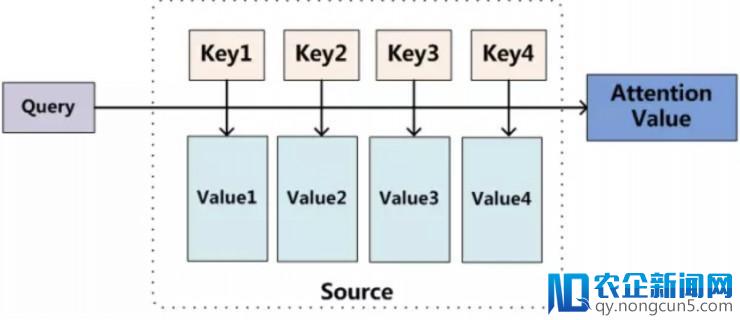
图 5: attention 机制原理表示图
我们可以将原句中的每一个单词看作一个 <Key,Value> 数据对,即原句可表示为一系列 <Key,Value> 数据对的组合。这时我们要经过计算 Query 和 每一个 Key 的类似性,失掉每个 Key 对应的 Value 的权重,再对 Value 停止加权求和,失掉 Attention 值。这个进程在于模仿人在看图片或许阅读文章时,由于先验信息和义务目的不同,我们关于文本的不同局部关注水平存在差别。例如:在语句「Father hits me!」中,假如我们关怀的是「谁打了我?」那么,Father 的权重应该就要较高。这种机制有利于我们从少量的信息中挑选出有用的局部,而过滤掉对我们的义务不重要的局部,从而进步了模型的效率和精确率。
而区别于普通的编码器-解码器构造中运用的 Attention model(输出和输入的内容不同),self attention 机制并不是输出和输入之间的 attention 机制,而是输出外部的单词或许输入外部单词之间的 attention 机制。Self-attention即K=V=Q,在 QANet 中,作者使得原文中每一对单词的互相作用都可以被描写出来,捕捉整篇文章的外部构造。
运用 self-attention 有以下益处:
(1)在并行方面,self-attention 和 CNN一样不依赖于前一时辰的计算,可以很好的并行,优于RNN。
(2)在长间隔依赖上,由于 self-attention 是每个词和一切词都要计算 attention,所以不论他们两头有多长间隔,最大的途径长度也都只是 1。可以高效捕捉长间隔依赖关系。
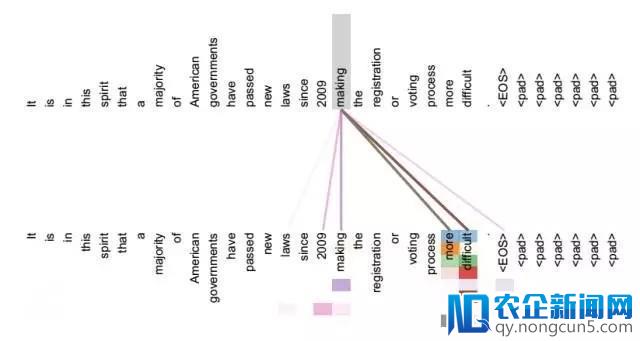
图6: self-attention 机制表示图
因而,在运用了 self-attention 机制之后,模型可以对单词停止并行化处置,大大进步了运转效率;使得模型可以运用更少数据停止训练,可以捕捉长间隔的依赖关系,也从另一个方面提升了模型的精确率。
结语
问答零碎开展的浪潮蒸蒸日上,当您阅读到本文时,不知 SQuAD 榜单上的名次能否又发作了变化。笔者在本文中和大家一同复习了问答零碎的概念,回忆了其开展历史,阐明了 SQuAD 数据集关于问答零碎学科开展的严重意义,并且向大家引见了目前得分最高的 QANet 零碎的设计框架,剖析了其运用 self-attention 机制的重要作用。现实上,能在 SQuAD 榜单上占有一席之地的模型都有其值得我们大家学习自创的中央,笔者这里之所以着重剖析 QANet,是由于它是第一个应用「卷积+self-attention」机制替代其他模型普遍运用的 RNN 网络的问答零碎模型。它并不依赖于 RNN 的递归训练来提升模型功能,反而另辟蹊径,经过较为复杂的网络组建节省了计算开支,使得我们运用更多的数据停止训练成为了能够,从而使模型的功能失掉了质的飞跃。此外,他们设计的数据加强办法也非常巧妙,并获得了很好的效果。可见,人工智能研讨之路本是「八仙过海,各显神通」,广阔研讨者们还需开阔思绪,不囿于后人的思想定式,方可曲线包围!
论文地址: https://openreview.net/forum?id=B14TlG-RW
雷锋网 AI 科技评论报道
。
