
选自tiriasresearch
机器之心编译
关于深度学习功能,还有很多不明之处。例如,你怎样停止测量?你应该测量什么?在不久之前的 GTC 2018,英伟达 CEO 黄仁勋引见了 PLASTER 框架,从可编程性到学习率 7 大应战来评测深度学习功能。昔日,英伟达博客对 PLASTER 框架停止了详细引见,机器之心编译了相关白皮书的次要内容。
白皮书链接:https://www.tiriasresearch.com/wp-content/uploads/2018/05/TIRIAS-Research-NVIDIA-PLASTER-Deep-Learning-framework.pdf
PLASTER 代表的含义:
- 可编程性(Programmability)
- 延迟(Latency)
- 精确率(Accuracy)
- 模型大小(Size of Model)
- 吞吐量(Throughput)
- 能效(Energy Efficiency)
- 学习率(Rate of Learning)
可编程性
机器学习不只在模型的规模和复杂性方面阅历了爆炸性的增长,而且在神经网络体系构造的多样性方面也阅历了相似的增长。即便是专家也很难了解模型的选择,然后选择适宜的模型来处理他们的人工智能成绩。
在对深度学习模型停止编码和训练之后,针对特定的运转时推断环境对其停止优化。英伟达运用两个关键工具处理训练和推理难题。在编码方面,基于人工智能的效劳开发人员运用 CUDA,这是一个并行计算平台和 GPU 通用计算的编程模型。在推断方面,基于人工智能的效劳开发人员运用了英伟达的可编程推断减速器 TensorRT。
CUDA 经过简化在英伟达平台上完成算法所需的步骤来协助数据迷信家。TensorRT 可编程推断减速器采用经过训练的神经网络,并对其停止优化以用于运转时部署。它测试浮点数和整数精度的不同级别,以便开发人员和运算进程可以均衡零碎所需的精确率和功能,从而提供优化的处理方案。
开发人员可以直接在 TensorFlow 框架中运用 TensorRT 来优化基于人工智能的效劳交付模型。TensorRT 可以从包括 Caffe2、MXNet 和 PyTorch 在内的各种框架中导入开放神经网络交流 ( onNX ) 模型。虽然深度学习依然是在技术层面编码,但这将协助数据迷信家更好天时用珍贵的工夫。
延迟
人和机器做决策或采取举动时都需求反响工夫。延迟就是恳求与做出回应之间所需求的工夫。大局部兽性化软件零碎(不只是 AI 零碎),延迟都是以毫秒来计量的。
由于 Siri、Alexa 等语音接口的呈现,语音辨认成为了很罕见的一种使用。在消费者与客服范畴,虚拟助手是很大的一种需求。但是,当人们接入虚拟助手时,即便数秒的延迟都会让人觉得不自然。
图像和视频管理是另一种需求低延迟、实时推理效劳的使用。谷歌曾表示,7 毫秒是图像和视频管理使用的最优化延迟。
另一个例子是自动翻译。晚期基于顺序、专家零碎的设计,不能了解高速言语的纤细差异,难以提供实时会话。如今,深度学习进一步改良了机器翻译。
精确率
虽然精确率对每个行业来说都不可或缺,但对医疗保健行业来说尤其重要。在过来的几十年中,医学成像技术有了很大提高,添加了其在医疗中的运用量,并且需求更多的图像剖析来确定医学成绩。医学成像的提高和运用还意味着必需把少量数据从医疗器械传给医学专家停止剖析。处理数据量成绩有两个选择:一是以较长延迟为代价传输完好信息,二是对数据停止采样并运用技术对其停止重建,但这些技术能够招致错误的重建和诊断。
深度学习的一个优点是可以以高精度停止训练,并且以较低精度完成。深度学习训练可以在更初级别的数学精度上十分准确地停止,通常选择 FP32。然后在运转时可以用较低精度的数学来完成,通常选择 FP16,从而取得改进的吞吐量、效率甚至延迟。坚持高精确率关于最佳用户体验至关重要。TensorRT 应用 Tesla V100 Tensor Core 的 FP16 处置以及 Tesla P4 的 INT8 特性来减速推断,与 FP32 相比,其推理速度进步了 2 – 3 倍,同时精确率损失接近零。
基于人工智能的效劳开发人员可以优化其深度学习模型以进步效率,然后在任务中以较低代价完成这些模型。
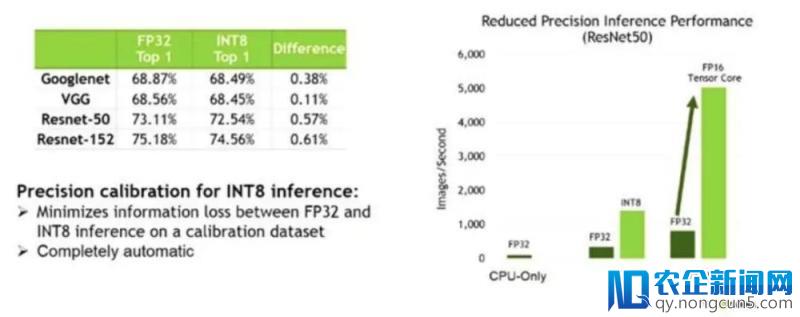
图 2:TensorRT 降低了精度的推断功能
模型大小
深度学习模型的大小和处置器间的物理网络容量都对功能有所影响,特别是在延迟和吞吐量方面。深度学习网络模型数量激增,模型大小和复杂性随之添加,也因而可以做更复杂的剖析,满足了更弱小零碎的训练需求。在深度学习模型中,计算力和物理网络扩展的缘由是:
- 网络层数量
- 每层节点(神经元)数量;
- 每层计算复杂度
- 一个网络层节点间衔接的数量以及相邻层间节点的数量
深度学习市场还处于晚期阶段。在比照模型大小时,以后的思绪都归结于物理关联:深度学习模型大小与计算和推理所需的物理网络资源成反比。例如,当开发者优化一个已训练深度学习模型来保证推断精确率和延迟时,能够会降低计算精度、简化每个模型网络层或许简化模型网络层间的衔接。但是,运用更大的已训练模型往往会带来更大的优化模型来做推断。
图 3:深度学习模型大小
吞吐量
吞吐量用来表述:在给定创立或部署的深度学习网络规模的状况下,可以传递多少推断后果。开发人员越来越多地在指定的延迟阈值内优化推断。虽然延迟限制可确保良好的客户体验,但在此限制内最大化吞吐量关于最大限制地添加数据中心效率和收益至关重要。
人们倾向于把吞吐量作为独一的功能目标,由于每秒计算的次数越多,其他范畴的功能就越好。但是,假如零碎无法在指定的延迟要求、电源预算或效劳器节点数内提供足够的吞吐量,那它最终将无法很好地满足使用顺序的推断需求。假如吞吐量和延迟之间缺乏适当的均衡,后果会是较差的客户体验、效劳等级协议(SLAs)缺失,以及效劳能够呈现毛病。
文娱业临时以来不断把吞吐量作为关键功能目标,尤其是在静态广告投放中。例如,品牌资助商将广告静态地置于诸如电视节目或体育赛事的视频流中。广告商想晓得其广告呈现的频率,以及它们能否传达给了预期受众。理解这些投放的精确性和焦点关于广告商来说至关重要。

图 4:直播时的图像辨认
能效
随着深度学习减速器功能的进步,深度学习减速器的能耗也飞速添加。为深度学习处理方案提供 ROI 触及了更多的层面,而不能仅仅看到零碎的推断功能。能耗增长会疾速添加提供效劳的本钱,这推进了在设备和零碎中对进步能效的需求。
例如,语音处置中通常需求海量处置来提供自然语音的智能应对。提供实时语音处置的数据中心推断通常触及少量计算机资源的支撑,并给企业总本钱带来很大的影响。因而,行业中运用每瓦特推断数(inferences-per-watt)来度量运营情况。超大规模数据中心追求能效的最大化,以在固定电源预算的状况下提供尽能够多的推断。
处理方案不是仅仅看哪些独自的处置器拥有更低的能耗。例如,假如某个处置器的功率是 200W,另一个处置器的功率是 130W,这并不表示 130W 的处置器零碎更好。假如 200W 的零碎能以 20 倍的速度更快地完成义务,那么它的能效更大。
每瓦特推断数还取决于训练进程和推断进程中的延迟要素。能效不只取决于进程中的纯能耗,还取决于吞吐量。能效是另一个展现 PLASTER 元素互相关联的例子,并且必需在完好的推断功能图景中被思索到。
学习率
近年来,企业开端施行开发运营,运用更弱小的零碎和更初级的编程工具,让开发和业务变得愈加严密。虽然深度学习仍处于起步阶段,但很多等候应用深度学习的学术、政府和商业机构却并非如此。他们想要的不是应用空泛而静态的数据训练出来的推断引擎。「AI」中包括了智能(intelligence)一词,用户希望神经网络能在合理的期限内停止学习和顺应。为了让复杂的深度学习零碎推进商业开展,软件工具开发者必需支持开发运营。
随着组织机构持续对深度学习和神经网络停止实验研讨,他们将学习如何更无效地构建和完成深度学习零碎。由于推断效劳继续接纳新数据并且效劳自身也在增长和变化,深度学习模型必需周期性地重新训练。为此,当新数据抵达时,IT 机构和软件开发者必需更快地重新训练模型。多 GPU 效劳器配置曾经使深度学习训练工夫从数周、数天降低到了数小时、数分钟。更快的训练工夫意味着开发者可以更频繁地重新训练他们的模型以进步精确率或坚持高精确率。目前一些深度学习完成曾经可以每天重新训练屡次。
可编程性也是学习率的一个影响要素。为了增加开发者任务流,谷歌和英伟达近日发布了 TensorFlow 和 TensorRT 的集成。开发者可以在 TensorFlow 框架内调用 TensorRT 来优化已训练的网络,从而在英伟达的 GPU 上高效运转。深度学习可以更好地整合训练进程和推断进程,因此更易成为开发运营的处理方案,协助机构在迭代他们的深度学习模型时疾速地完成变化。
参考链接:https://blogs.nvidia.com/blog/2018/05/12/how-do-i-understand-deep-learning-performance/