
当 手机 取代了钱包,领取宝甚至比现金更常用,与蚂蚁金服的产品端一同繁忙起来的还有公司的效劳端。95188 效劳热线就是其中之一。
但是当我们谈起客服电话,想到的依然是传统的按键菜单(「普通话效劳请按 1,for English service please press 2」)和在机械而漫长的语音播报里等候的烦躁。「在过来的统计里,只需用户没转接人工,就算作『成绩被自助处理了』,其真实我们看来那不叫『处理』,叫『损耗』。」 蚂蚁金服的产品运营专家弈客说。秉承着这样的理念,团队开发了 MISA(Machine Intelligence Service Assistant),一个可以经过辨认用户的语音中包括的业务需求来直接停止回应的客服零碎,他们称之为「37摄氏度的自助语音交互」。
在 金融 业务范畴,客户效劳触及许多环节,经过人工智能的技术处理客服成绩,为广阔用户提供高效、特性化的普惠金融效劳,成为金融 科技 范畴十分根底、十分具有应战性的课题。
最近,在蚂蚁金服发起的「ATEC蚂蚁开发者大赛——人工智能大赛」上,这支团队在初赛就拿出了来自实践使用场景的 10 万对标注成绩集,并开放相关资源与专家指点,约请人工智能开发者来应战「成绩类似度计算」这一客服范畴最根底也最中心的义务。
如今,赛事曾经集结了来自全球超越两千支队伍报名,并开启了剧烈的精确率打榜竞赛。近日机器之心也有幸看望蚂蚁金服,采访了 MISA 团队中的三位中心成员:人工智能部资深算法专家深空(张家兴 )、客户效劳及权益保证事业部产品运营专家弈客 (于浩淼 ) 以及人工智能部算法专家千瞳(崔恒斌 ),聊了聊如何应用深度学习算法构建可以「料事如神」的客服零碎。以下内容依据采访实录整理,机器之心对内容作了不改动原意的调整。
MISA 的「生长故事」与「近照」
机器之心:开发 MISA 零碎的初衷是什么?
弈客:95188 领取宝效劳热线是一个典型的 IVR 场景(Interactive Voice Response,互动式语音应对),作为一个语音渠道,它的业务目的很复杂,就是「定位用户的成绩,婚配相应解答方案」。一开端,它就是一个传统的按键菜单,后来随着蚂蚁金服业务线的日益增长,按键菜单无法满足业务需求,同时语音辨认技术也进入了一个根本可以投入使用的阶段,所以从 16 年终开端,我们和算法工程师一同,尝试找新的处理办法。
最后的想法是让用户描绘本人的成绩与场景,然后将描绘与我们的业务与知识停止一次婚配。后来,我们发现单次婚配也很难做到特别精准,由于用户很难在单次描绘里给出全部所需求素,所以就尝试以多轮交互的方式,用一个对话零碎来协助用户补全其描绘中缺失的局部。
再后来,我们发现与其让用户完全清楚地描绘本人的成绩,不如我们率先提问。我们做了少量的市场调研,发现如今市面上的客服零碎也根本上以「描绘与婚配」形式为主,触及多轮交互的自身就很少,在多轮根底上开展方向也没有那么明白。因而我们就回到了蚂蚁本身。我们就想,能不能基于用户在发问时所积聚的行为特征,以「猜成绩」的方式让零碎率先发起对话,降低用户的运用难度。相比于「你有什么成绩?」,「你是不是想问 XXX 成绩?」就要容易答复得多,即便用户答复「不是」,我们的成绩也会为他接上去的描绘提供一个示例。
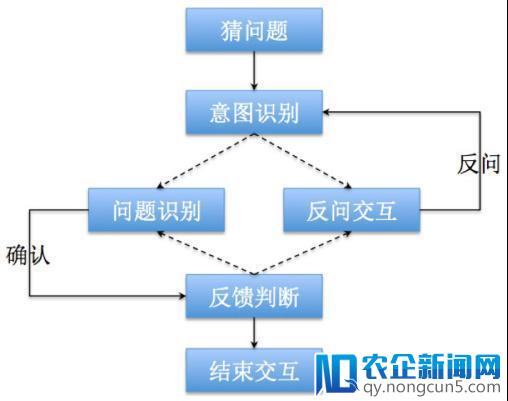
图:如今的 95188 语音效劳流程
机器之心:如今 MISA 的零碎由哪些局部组成?辨别完成什么义务?
深空:MISA 的次要模块有猜成绩、成绩辨认、反问交互三个。「猜成绩」是蚂蚁金服在客服范畴的首创,是一个应用用户能够与本次致电相关的信息,基于深度学习算法框架构建的成绩辨认模型。「成绩辨认」是依据用户的描绘定位他能够遇到的成绩。「反问交互」是在用户给出的信息不全时,应用「要素拆解和补全」的方式协助成绩辨认模块圈定范围,降低成绩辨认的难度,以反问的方式与用户停止交互。
机器之心: 除了用户转为文本的语音输出外,MISA 的零碎还会接纳哪些输出?如何分类?
深空:我们将输出分为因子、轨迹、文本三类。因子是由业务方定义的、具有明白含义的特征,例如:过来24小时能否有还款行为、过来24小时能否发作过转账行为等。因子大约无数百个。轨迹是用户最近的 120 个「行为」组成的工夫序列,其中一个行为指对近程效劳器发作一次恳求。行为的品种超越一万种。文本是用户的描绘以文本方式表达;在「猜成绩」环节,文本指用户的历史描绘,在正常的「成绩辨认」环节,文本即把本次电话里用户对成绩的语音描绘互联网思维,就是在(移动)互联网+、大数据、云计算等科技不断发展的背景下,对市场、用户、产品、企业价值链乃至对整个商业生态进行重新审视的思考方式。转换成文本。文本是一个长度各不相反,甚至能够空缺的输出。
机器之心:作为一个以辨认为次要目的的零碎,MISA 会将用户的成绩婚配到多少品种型里?如何给出应对?
弈客:需求婚配的成绩类型的详细数字随着业务上线与下线会有浮动,规模大约在「数千」这个量级。
大框架上,应对可以分为三类。第一类,假如用户的成绩很复杂,能用一两句话说清楚,我们就以播报的方式输入。比方之前余额宝一个业务的产品方案停止了调整,从不限转入金额到每天最多只能转入两万。这时分当用户转入出错前来征询,我们就会以播报方式把业务调整告诉给用户。第二类,假如方案需求用户在某一个产品页面停止操作与交互,我们就会把相应页面在用户的 app 里拉起来。用户挂掉电话翻开 app,就能看到处理方案页面的推送,点开就可以完成操作了。最初一类,我们判别绝对复杂的成绩,就转接人工小二处置。
机器之心:一位用户均匀需求与零碎停止多少轮对话可以定位到本人的成绩呢?
弈客:一开端零碎才能还没有那么强的时分,我们把最多对话轮数设置为 4 轮,假如 4 轮对话之后用户的成绩依然没有失掉处理,就转交人工客服。经过不时的优化,如今用户的均匀对话轮数不超越两轮,大约在 1.8-1.9 左右。
客服零碎是怎样炼成的:模型选择、评价与优化
机器之心:在处置自然言语文本时,用到了哪些深度学习模型?
千瞳:我们首先用本人预训练的词向量对文本停止表示,然后辨别用到了卷积神经网络(CNN)和以 LSTM 为根本单位的循环神经网络(RNN)对文本停止处置。
卷积神经网络中,模型对由词向量组成的文本做一维单层卷积与池化,构成一个向量,RNN 则把文本视为一个序列,处置后也失掉一个向量,最初,将两个向量相加,失掉一个代表本段文本的新向量,然后与代表因子和轨迹的向量加在一同,停止分类。
机器之心:为什么同时采用 CNN 和 RNN?
千瞳:两种模型提取特征的才能不同。CNN 的才能在于提取关键词。RNN更擅长捕获序列关系。
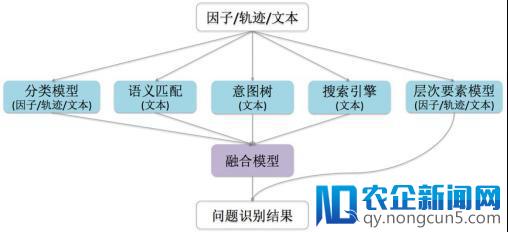
机器之心:分类模型与成绩辨认模块的关系是?
千瞳:成绩辨认模型是由多个子模型+交融模型的方式组织的。分类模型只是其中一种子模型,除此之外,还有搜索、意图树等多个构造化子模型。不同模型的输入格式也各不相反,分类模型前往不同类别的能够性打分,而意图树能够只前往某一个最能够的类别。在子模型各自停止成绩辨认后,我们会经过一个GBDT的模型,对前四个模型的后果停止交融。在交融模型阶段,我们取每一个模型的 top1 输入,依据标注数据来选择输入能够性最高的那个模型的后果。
机器之心:反问交互是如何完成的?
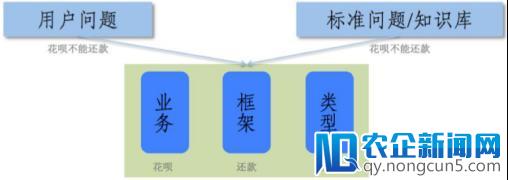
弈客:如今一百通电话里,有三十通会率先经过猜成绩的方式对用户停止提问。假如没有猜中,就要考虑如何在较短的轮数内摸清用户的需求。用户的大少数成绩都可以以「业务、框架、类型」三要素方式停止拆分。例如「花呗不能还款」,「花呗」就是触及的业务,成绩的中心动词「还款」就是框架,「失败」是招致用户发问的诉求类型。有超越一千个用户成绩都可以被拆解成三要素的方式,其中包括一百多类业务、不到一百类框架和不超越十种成绩类型。
三要素拆分方式的方式可以协助疾速减少辨认范围。用户在描绘中,能够不能一次把三要素都描绘清楚,但是假如给出了某局部要素,比方用户说移动互联网在带来全新社交体验的同时,也或多或少使人们产生了依赖。移动互联网使网络、智能终端、数字技术等新技术得到整合,建立了新的产业生态链,催生全新文化产业形态。「我要还款」,就给出了框架「还款」和类型「如何」,这时我们就可以就缺失的「业务」要素停止反问,比方,「您是要停止花呗还款、借呗还款还是信誉卡还款?」
千瞳:从技术的角度下去讲,我们在构建了语义要素库之后,是可以完成 zero-shot 的成绩辨认的。即,不需求见到特定的要素组合的训练样本,只需在其他训练样本中见过独自的要素在其他场景下呈现,一样可以辨认这个要素组合,对应到相应成绩。
另外,我们也构建了多义务学习的框架。三要素辨认义务的目的是十分相似的,都可以看做是多分类成绩。多义务学习让不同义务间的数据可以共享。虽然每一个独自的义务都有足够的数据,但是不同义务间目的会让特征提取各有侧重,进步模型效果。相比单模型,辨认精确率可以提升7个百分点。
机器之心:如何评价婚配的准确水平?这些评价能否会反过去影响模型的优化?
千瞳:婚配的评价目标有多个层级,第一个是CTR(Click Through Rate),比方在「猜成绩」阶段,用户会确认零碎猜的是不是他的成绩。第二个是分流的精确率,假如分配到人工还有小二派单精确率,最初是成绩处理率。
至于用户的评价如何影响模型优化,一言以蔽之,用户的反应就是模型的训练数据,零碎本人能构成一个闭环迭代体系。 MISA 的大局部模型一周迭代两次。
关于竞赛:客服范畴里的类似度计算
机器之心:竞赛中的「判别两句话能否为同义句」义务和应用分类法停止成绩辨认义务之间的关系是什么?
深空:当我们拿到一个用户的自然言语问句,想判别它是知识库里的哪一类成绩时,通常有两种做法:一是做分类,也就是下面讲到的成绩辨认;还有一种做法就是判别同义句,给出每一类成绩的几条例句后,当一个新的问句呈现,就计算新问句与每一条例句之间的类似度。
相比于辨认,同义句是一类绝对昂贵但具有严重意义的做法。关于许多拿不到丰厚数据的场景来说,训练分类器变得不能够,而搜集例句、计算类似度相较之下更为可行和适宜。
基于类似度计算的分类算法关于数据的需求要灵敏得多,可以依据数据的状况分层次布置:有的办法可以不需求训练数据,基于规则来做;有的办法可以基于范畴有关的、有地下语料的通用数据停止训练;当然,假如提供范畴相关的数据,可以让类似度计算得更好,就像我们这次提供的数据这样。
从工程的角度来讲,这种一开端对训练数据依赖较小的方法,有利于工程师墨守成规把一个成绩处理掉。
机器之心:选择判别同义句作为本次大赛赛题的缘由都有哪些?
深空:第一,在将用户的问句分类的场景下,类似度计算是一种根底而适用的做法。在客服范畴里,大少数使用场景依然是短少数据的。第二,成绩的类似度计算在其他场景下也有普遍的使用,例如,在「发掘用户罕见成绩」义务里,就要对用户问句停止聚类,将每一类罕见成绩归为一类。聚类的根底就是计算每两个问句之间的类似度。还有许多其他相似的使用。总而言之,类似度计算是客服大范畴中十分根底、十分中心的一个成绩。
这次竞赛的重点就是鼓舞选手找到好的类似度计算办法。本次我们在初赛就提供了 10 万条数据。作为比照,如今的类似度计算竞赛中最大的地下数据集大约在 1 万条左右。但是我们不强迫选手运用提供的数据,完全不基于数据或许引入内部数据的做法都是被允许的,希望选手们形形色色,找到最好的类似度计算办法。
机器之心:能否会思索将竞赛中呈现的做法投入到实践消费中?
千瞳:这是一定的。蚂蚁的业务开展十分快,因而在设计算法的进程中会遇到很多理想的成绩:比方用户描绘口语化、描绘多样性、纠错以长句成绩等等,都需求类似度计算办法去处理,我们本人也在停止少量类似度计算方面的探究,希望可以和选手们一同,找到最适宜的办法。
如今起,即刻登录大赛官网报名参赛,百万奖金等你来战。
【参加大赛群,参与赛题讨论与观看发布会】
添加机器之心小助手3,备注:蚂蚁,由小助手约请进群,第一工夫获取大赛相关信息,一同讨论赛题,以及与其他小同伴互动交流。