

本文来自钛媒体专栏「800字,读懂一家 AI 公司」
[每篇 3 分钟,钛媒体带你读懂人工智能]
在 AI 范畴,“机器学习”是较难了解的概念之一。
在议论机器学习之前,我们有必要以具象的方式解释下算法,为了方便了解,北京邮电大学信息学博士、前百度技术管理部首席专家李敏就以数学公式的形状给钛媒体举例:
当我们为机器学习设定一个目的:比方让互联网广告被点击的频率添加,算法迷信家就会基于经历与理论构成一个初步的算法模型,假定为:
F(x)=a+bx+cx²+dx³+……
这个公式就可以被视作极简的一种算法。其中,F(x) 就是互联网广告被点击的概率,x 是我们常说的用户画像和搜索关键词,诸如年龄、性别、爱好等维度都会以数值的方式被代入公式,而 a、b、c、d……就是所谓的参数。迷信家们整日实验操作的,就是想方设法经过参数的调整,让F(x)的数值到达理想化的形态。
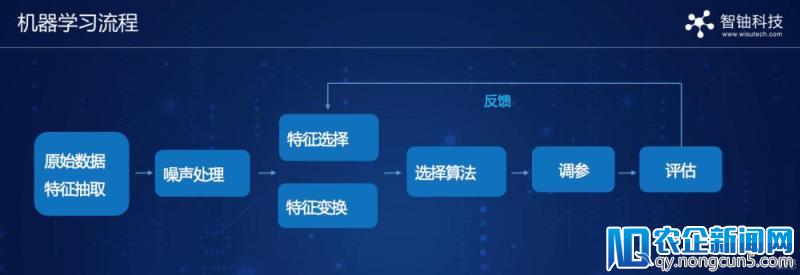
当然,在真实的机器学习场景中,算法的形状要比上述“公式”复杂数倍,调参的规范也需基于不同业务的特性。而在算法的功能失掉提升并趋于波动后,机器就能应用这套打磨好的算法,完成自动化的评价和判别,这就构成一个“全自动机器学习平台”。
这也是李敏正在做的事情。
2017年6月,李敏与前百度资深迷信家夏粉等人成立“智铀科技”。夏粉是百度大规模机器学习平台 Pulsar 创建者,在百度的各业务线中,Pulsar 被普遍使用,举个例子:百度的搜索后果不计其数,而机器学习就能对用户画像、广告标签停止算法处置,让搜索后果既满足用户需求,也能具有潜在的营销时机。
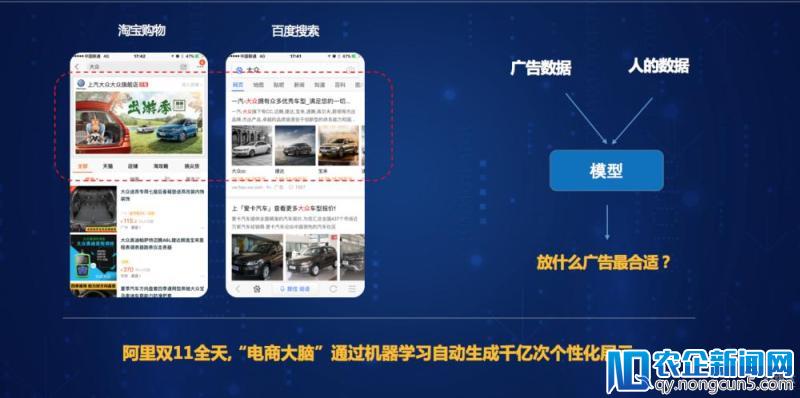
机器学习在互联网广告场景下的使用
为了将 Pulsar 这样的机器学习平台扩展至更多范畴,“智铀科技”推出了更为通用的 “Ebrain”平台,用机器来取代人工的模型调参,完成自动建模,而在产品商用落地的进程中,降低 Ebrain 的运用门槛是智铀开发产品的首要目的。
凭着此前在百度的积聚,智铀在算法调参、建模等方面较为擅长,包括怎样梳理客户的数据特征;怎样提炼用户画像和业务维度;如何调整参数让 F(x) 的效果更好,智铀可以将这些需求算法迷信家完成的任务打包成一个 PC 端的产品,工程师只需将已有的数据导入“Ebrain”零碎,就可完成机器的自主学习与判别。
“比方信誉卡盗刷事情的呼应与预防。信誉卡公司将之前呈现盗刷案例的工夫、频次、盗刷 pos 机类别等规律性特征给我,就能经过 Ebrain 停止学习后对之后的盗刷状况停止辨认和预警。”李敏用金融行业的产品落地为钛媒体举例。
目前,智铀科技已与局部基因、金融行业客户停止协作试点,并方案在6 月上旬正式推出商用产品,2018年终智铀曾获由洪泰基金领投的 Pre-A轮融资,投后估值达4亿元。(本文首发钛媒体,作者/苏建勋)
更多精彩内容,关注钛媒体微信号(ID:taimeiti),或许下载钛媒体App
