
雷锋网 AI 科技评论按:本文由 Ben Packer, Yoni Halpern, Mario Guajardo-Céspedes & Margaret Mitchell (Google AI)于 2018 年 4 月 13 日发布。这篇文章讨论并尝试实践测量了不同文本嵌入模型中的性别偏向。雷锋网 (大众号:雷锋网) AI 科技评论全文编译如下。
当面对义务时,我们机器学习从业者通常基于该义务上的表现好坏来选择或训练模型。例如,假定我们正在树立一个零碎来分类电影评论是正面还是负面,我们会选取 5 种不同的模型,看看每个模型关于这项义务的表现如何。
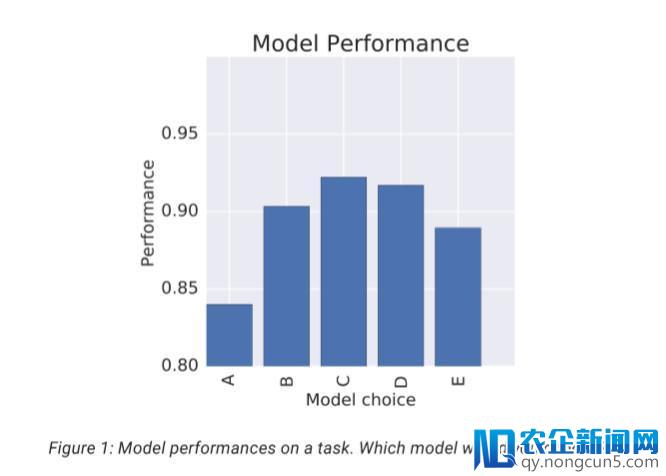
通常状况下,我们会选择模型 C。虽然较之其他模型,模型 C 的效果最好,但是我们发现,模型 C 也最有 能够将更积极的情感赋予「配角是男人」这句话,而不是「配角是女人」这句话 。 我们应该重新考虑这个成绩吗?
机器学习模型中的偏向
神经网络模型可以十分无力、无效地用于形式辨认并提醒从言语翻译,病理学到玩游戏等各种不同义务的构造。同时,神经网络(以及其他类型的机器学习模型)也包括许多方式的存疑的偏向。例如,被训练用于检测粗鲁,凌辱或不恰当评论的分类器在面对「我是异性恋」和「我是直的」这两句话时,能够更容易命中前一句;人脸辨认模型关于着妆的女性而言能够效果不佳;语音转录对美国黑人的错误率能够高于美国白人。
许多事后训练好的机器学习模型已普遍供开发人员运用。例如,TensorFlow Hub 最近地下发布了平台。当开发人员在使用顺序中运用这些模型时,他们认识到模型存在偏向以及偏向在这些使用中会如何展示。
人为的数据默许编码了人为的偏向 。认识到这件事是一个好的开端,关于如何处置它的研讨正在停止中。在 Google,我们正在积极研讨不测偏向剖析和减小偏向的战略,由于我们努力于制造合适每团体的产品。在这篇文章中,我们将研讨一些文本嵌入模型,提出一些用于评价特定方式偏向的工具,并讨论构建使用顺序时这些成绩的重要性。
WEAT分数,一种通用的测量工具
文本嵌入模型将任何输出文本转换为数值化的输入向量,并且在进程中将语义类似的词语映射到相邻的向量空间中:

给定一个训练好的文本嵌入模型,我们可以直接测量模型中的单词或短语之间的关联。这些关联许多都是契合预期的,并有助于自然言语义务。但是,也有些关联能够会有成绩。例如,Bolukbasi 等人的打破性 NIPS 论文《Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings》( https://arxiv.org/abs/1607.06520 )中发现,基于 Google 新闻文本用盛行的开源工具 word2vec 训练的词向量模型中,「男人」和「女人」之间的向量关系相似于「医生」和「注册护士」或「掌柜」和「家庭主妇」之间的关系。
最近,由 Caliskan 等人提出的词向量关联测试(WEAT)(Semantics derived automatically from language corpora contain human-like biases, Science, https://arxiv.org/abs/1608.07187 )是一种反省词向量概念之间关系的办法,这些概念可以从内隐联想检验(IAT)中捕捉。本文我们将 WEAT 用作探究某些存疑关联的一种方式。
WEAT 测试得出了模型将目的词组(例如,非洲裔美国人名字,欧洲美国人名字,花或昆虫)与属性词组(例如「波动」,「愉快」或「不愉快」)联络起来的水平。两个给定词之间的关联被定义为词向量之间的余弦类似度。
例如,第一次 WEAT 测试的目的列表是花和昆虫的类型,属性列表是表愉快的词(例如「爱」,「战争」)和不愉快的词(例如「仇恨」,「漂亮的」)。总体测试分数上,绝对于昆虫,花与表示愉快的词语之间的相关水平更大。值为正的高分(分数可以介于 2.0 和-2.0 之间)意味着花与愉快的单词更相关,而值为负的高分意味着昆虫与愉快的单词更相关。
而在 Caliskan 等人提出的第一个 WEAT 测试中,测量的关系并不是社会所关注的(除了对昆虫学家而言),其他的测试可以测量出更多存疑的偏向。
我们运用 WEAT 分数来反省几个词向量模型:word2vec 和 GloVe(以前在 Caliskan 等人文章中提到过),以及 TensorFlow Hub 平台上开源的三个新发布的模型——nnlm-en-dim50,nnlm-en-dim128 和 universal-sentence-encoder。得分报告在表 1 中。
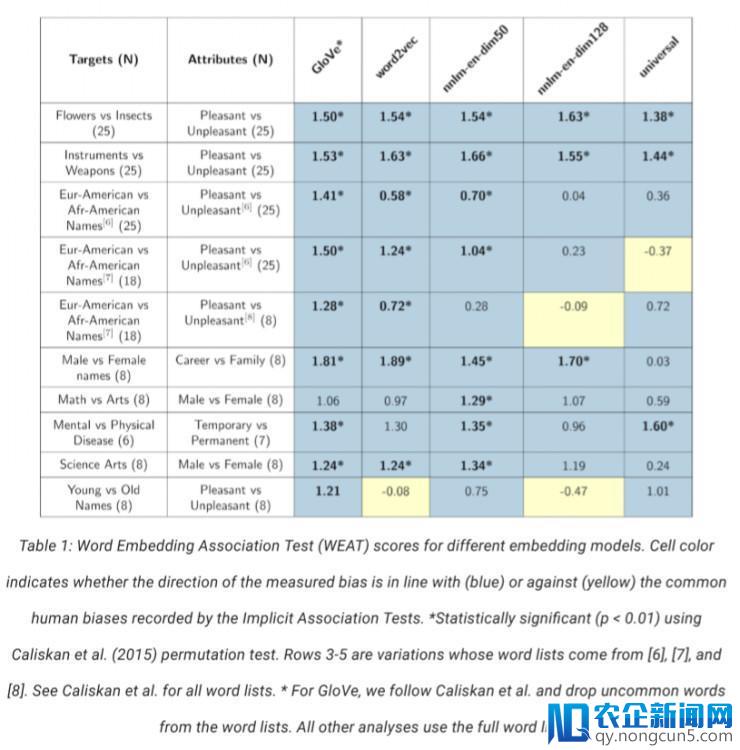
这些关联是从用于训练这些模型的数据中学习失掉的。一切模型都曾经学会了我们能够希冀的花、昆虫、乐器和武器的联络,这能够对文本了解有用。从其他目的类别学习失掉的关联关系中,包括一些(但不是全部)由模型加强了的罕见人为偏向。
关于运用这些模型的开发人员来说,理解这些关联存在很重要,并且这些测试仅评价一小局部能够存在成绩的偏向。增加不用要偏向的战略是一个新的活泼的研讨范畴,但是目前并没有某一个办法可以适用于一切使用。
在关注文本嵌入模型中的关联时,要确定它们对下游使用顺序影响的最明白办法是直接反省这些使用顺序。我们如今来看看对两个示例使用顺序的扼要剖析:一个情感剖析器(Sentiment Analyzer)和一个音讯使用顺序(Messaging App)。
案例研讨1 : Tia 的电影情感剖析器
WEAT 分数测量词向量的属性,但是他们没有通知我们这些向量如何影响下游义务。在这里,我们演示将姓名映射到几个罕见向量后关于影评情感剖析的义务的影响。
Tia 正在训练一个电影评论情感分类器。她没有太多的影评样本,所以她应用预训练文本嵌入模型,将文本映射到可以使分类义务更容易辨认的表示中。
让我们运用 IMDB 电影评论数据集来模仿 Tia 的场景,对 1000 个正面评论和 1000 个负面评论停止二次抽样。我们将运用事后训练的词向量来将 IMDB 评论的文本映射到低维矢量空间,并将这些矢量用作线性分类器中的特征。我们将思索一些不同的词向量模型,并辨别训练一个线性格感分类器。
我们将运用 ROC 曲线下的面积(AUC)度量来评价情感分类器的质量。
这里是运用每个向量模型提取特征的电影情感分类的AUC分数:
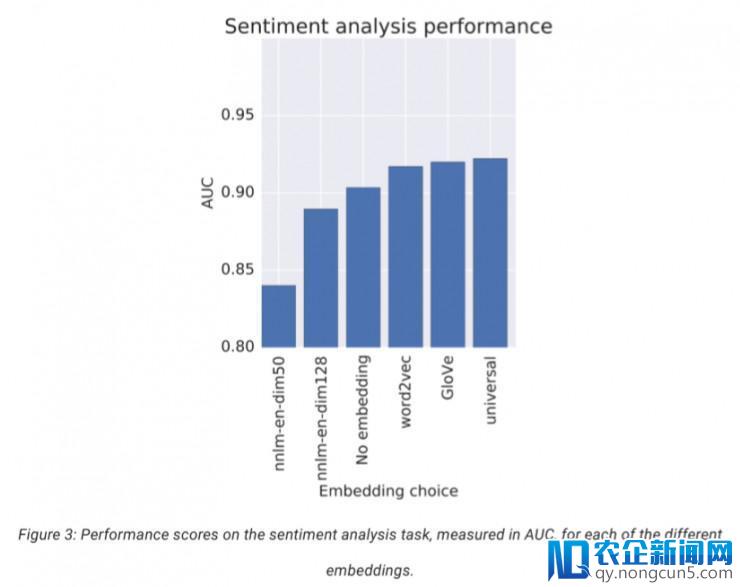
后来,Tia 似乎很容易做出决议。她应该运用得分最高的向量模型用在分类器中,对吧?
但是,让我们思索一些能够影响这一决议的其他要素。这些词向量模型是在 Tia 能够无法获取的大型数据集上训练失掉的。她想评价这些数据集中固有的偏向能否会影响她的分类行为。
经过检查各种向量模型的 WEAT 分数,Tia 留意到一些词向量模型以为某些称号比其他称号更具有「愉快」的含义。这听起来并不像电影情感剖析器的一个很好的属性。Tia 以为称号不应该影响电影评论的预测情感,这似乎是不对的。她决议反省这种「愉悦偏向」能否影响她的分类义务。
她首先经过构建一些测试样例来确定能否可以检测到分明的偏向。
在这种状况下,她从她的测试集中获得 100 条最短的评论,并附上「评论来自 _______」这几个字,其中空白处填入一些人的姓名。运用 Caliskan 等人提出的「非裔美国人」和「欧洲美国人」名单,以及来自美国社会保证局的普通男性和女性的名字,她研讨了均匀情感分数的差别。

下面的小提琴图显示了 Tia 能够看到的均匀情感分数的差别散布,经过从原始 IMDB 训练集中抽取 1000 个正面和 1000 个负面评论的子样本停止模仿。我们展现了 5 种词向量模型的后果以及没有运用词向量的模型的后果。
反省没有词向量的情感差别很方便,它可以确认与称号相关的情感不是来自小型IMDB监视数据集,而是由预训练词向量模型引入的。我们还可以看到,不同的词向量会招致不同的零碎输入,这标明词向量的选择是 Tia 情感分类器将会发生的关联的关键要素。 可以看到,只是在最初附加了不异性别的名字,都招致某些模型的情感分类的后果呈现了变化。
Tia 接上去就需求十分细心地思索如何运用这个分类器。也许她的目的只是选择一些好的电影供本人观看。在这种状况下,这能够不是什么大成绩。呈现在列表顶部的电影能够是十分喜欢的电影。但是,假如她用她的模型来评价演员的均匀影评等级,以此为根据雇佣演员并领取演员薪酬呢?这听起来就有大成绩了。
Tia 能够不限于此处所提供的选择。她能够会思索其他办法,如将一切称号映射到单个词中;运用旨在加重数据集中称号敏感度的数据重新训练词向量;或运用多个向量模型并处置模型不分歧的状况。
这里没有一个「正确」的答案。这些决策中的很多都是高度依赖于上下文的,并取决于 Tia 的预期用处。关于 Tia 来说,在选择训练文本分类模型的特征提取办法时需求思索的目标远不止分类精确率一项。
案例研讨2:Tamera 的音讯使用顺序
Tamera 正在构建一个音讯使用顺序,并且她希望运用文本嵌入模型在用户收到音讯时给予他们建议的回复。她曾经树立了一个零碎来为给定的音讯生成一组候选回复,并且她希望运用文本嵌入模型对这些候选人停止评分。详细而言,她将经过模型运转输出音讯以获取音讯的文本嵌入向量,对每个候选呼应停止相反的处置,然后运用嵌入向量和音讯嵌入向量之间的余弦类似度对每个候选者停止评分。
虽然模型的偏向在许多方面能够对这些建议回答起作用,但她决议专注于一个狭隘的方面:职业与二元性别之间的关联。在这种状况下,举一个关于偏向的例子,假如传入的音讯是「工程师能否完成了项目?」模型给答复「是的,他做了」的评分高于「是的,她做了」,就表现出了模型的偏向。这些关联是从用于训练词向量的数据中学习的,虽然它们关于性别的反响水平很能够就是训练数据中的实践反响(以及在理想世界中这些职业中存在性别不均衡的水平),但当零碎复杂地假定工程师是男性时,对用户来说能够是一种负面的体验。
为了权衡这种方式的偏向,她创立了提示和回复的模板列表。这些模板包括诸如「是你的表弟吗?」和「明天是在这里吗?」等成绩,答案模板是「是,他/她是的」。关于一个给定的职业和成绩(例如,「水管工明天会在场吗?」),模型的偏向分数是模型对女性性别反响(「是,她会」)的分数与男性(「是的,他会的」)的分数的差别:

关于整个给定的职业,模型的偏向分数是该职业一切成绩/答案模板的偏向分数的总和。
经过运用 Universal Sentence Encoder 嵌入模型剖析,Tamera 可以运转 200 个职业。表 2 显示了最高女性偏向分数(左)和最高男性偏向分数(右)的职业:
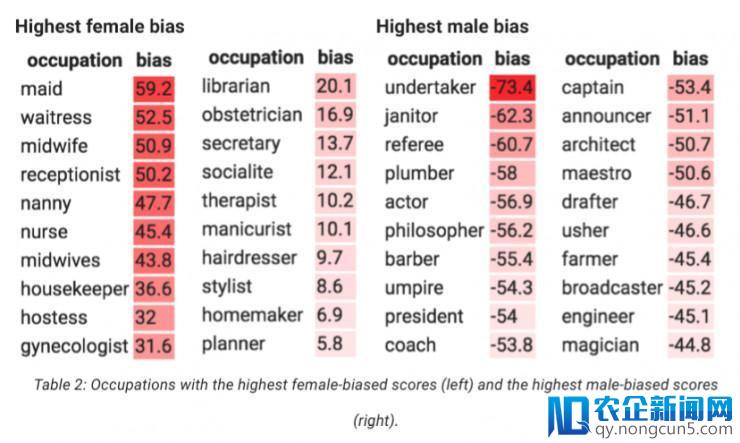
「女效劳员」成绩更有能够发生包括「她」的回应,但 Tamera 并没无为此感到困扰,但许多其他回应的偏向阻拦了她。和 Tia 一样,Tamera 可以做几个选择。她可以复杂地承受这些偏向,不做任何事情,但最少,假如用户埋怨,她不会措手不及。她可以在用户界面上停止更改,例如经过提供两特性别的呼应而不是一个,当输出音讯中需求含有性别代名词的时分(例如,「她明天会在那里吗?」)。
但她也能够不想这样做。她可以尝试运用偏向加重技术重新训练词嵌入模型,并反省这会如何影响下游义务的表现,或许她能够会在训练她的分类器时直接加重分类器中的偏向(例如, http://research.google.com/pubs/pub46743.html , https://arxiv.org/abs/1707.00075 ,或许 https://arxiv.org/abs/1801.07593 )。无论她决议做什么,重要的是 Tamera 都会停止这品种型的剖析,以便晓得她的产品的功用,并且可以做出明智的决议。
结论
为了更好天文解 ML 模型能够发生的潜在成绩,模型创立者和运用这些模型的从业者应该反省模型能够包括的不良偏向。我们曾经展现了一些工具来提醒这些模型中特定方式的刻板印象偏向,但这当然不构成一切方式的偏向。即便是这里讨论的 WEAT 剖析的范围也很窄,所以不应该被解释为在嵌入模型中抓取隐式关联的完好故事。例如,针关于消弭 WEAT 类别中的 50 个称号的负相关而明白训练的模型能够不会加重其他称号或类别的负相关,并且由此发生的低 WEAT 得分能够给出错觉,即全体上的负关联成绩曾经失掉了很好的处理。这些评价更好地通知我们现有模型的行为方式,并作为一个终点让我们理解不需求的偏向是如何影响我们发明和运用的技术的。我们正在持续处理这个成绩,由于我们置信这很重要,同时也约请您参加这个话题。
致谢:我们要感激 Lucy Vasserman,Eric Breck,Erica Greene 以及 TensorFlow Hub 和 Semantic Experiences 团队在这项任务上的协作。
via developers.googleblog.com ,雷锋网 AI 科技评论编译
雷锋网版权文章,未经受权制止转载。概况见。
