
2018年被称为AI片面迸发的元年,少量AI行业使用逐步落地,带来了消费效率及生活质量的大幅提升,催生出了愈加多元化的 商业 价值。而随同着AI开展进入深水区,待处置数据量绝后庞大,算法复杂度出现指数级增长,能否提供更快更强的计算力,成为AI坚持高速开展的关键要素。
面向用户日益增长的关于构建更智慧AI使用的计算需求,提供功能愈加强悍、弹性易扩展和高性价比的云上计算才能,成为业界的共同目的。金山云基于对用户需求的深入把控,于近期正式推出了基于NVIDIA Tesla V100的GPU云效劳器,支持最高15*8 TFLOPS的单精浮点计算才能和125*8TFLOPS的混合精度(FP16/FP32)矩阵计算才能,使深度学习训练与推理进程功能提升300%,而本钱坚持不变。

210亿颗晶体管构建最强计算力
作为国际首家正式地下售卖的基于Tesla V100的GPU云效劳器,运用了创新的Tensor Core引擎,将混合精度浮点的计算才能再提升10倍以上,在全体深度学习的训练与推理使用中相比于上一代PASCAL平台有了3倍功能提升,可轻松应对深度学习,迷信运算、图形图像渲染等诸多使用场景,无效延长在线预测和离线训练时长。
目前基于V100的GPU减速计算效劳已片面商用,为包括小米等在内的诸多客户提供着高功能的计算支撑。小米最新发布的年度旗舰 手机 小米8,其AI加持的片面屏零碎MIUI 10、AI相机、AI语音助理“小爱同窗”等,面前均有金山云顶级GPU资源提供的计算效劳,极大提升了产品的研发效率和运用体验。
在根底构造层面,Tesla V100一共包括了210亿颗晶体管,搭载了84个SM(流多处置器)单元,其中无效单元有80个,每个SM单元中有64个单精度的处置单元CUDA Core以及8个混合精度的矩阵运算单元Tensor Core,总计共有5120个CUDA Core和640个Tensor Core,搭载16GB的HBM 2的显存,带宽可以高达900GB/s,并且支持300GB/s双向带宽的NVlink2.0的主线协议。
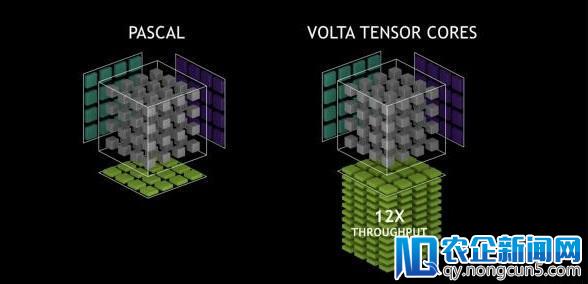
全新的Volta架构表示图
在线程分配层面,V100是首款支持独立线程调度的GPU,允许GPU执行任何线程,从而顺序中的并行线程之间能完成更精密的同步与协作,运用户能在更复杂多样的使用顺序上高效地任务。首创的Tensor Core打破了单处置器的最快处置速度记载,可以提供比功用单一的ASIC更高的功能,在不同任务负载下依然具有可编程性。
Tensor Core打造更专业的深度学习计算单元
Tensor Core是Volta架构最重磅的特性,是专门针对深度学习使用而设计的公用ASIC单元,是一种矩阵乘累加的计算单元。(矩阵乘累加计算在Deep Learning网络层算法中,比方卷积层、全衔接层等是最重要、最耗时的一局部)。Tensor 中心每个时钟周期可执行64次浮点混合乘加(FMA)运算,从而为训练和推理使用顺序提供高达125 TFLOPS的计算功能。
更强悍的计算才能意味着开发人员可以运用混合精度(FP16 计算运用 FP32 累加)执行深度学习训练,从而完成比上一代产品快3倍的功聚集了全世界身经百战的最优秀的创业导师,汇集了全世界各国最优质的产业资源,召唤全球未来的商业领袖。能,并可收敛至网络预期精确度,目前Tensor Core可以支持的深度学习框架有Caffe、Caffe2、MXNet、PyTorch、Theano、TensorFƒlow等。

NVlink互联方式表示图
此外,Tesla V100的NVlink版本支持NVlink2.0高速互联总线协议,Tesla P100支持的蓬勃发展的行业不仅给从业者提供了巨大的发展机遇,也带来了全新的挑战。NVlink1.0协议,每颗GPU可以衔接4根总线,每根总线的单向传输带宽可以到达20GB/s,四根总线可以完成单向80GB/s、双向160GB/s的IO带宽。而Tesla V100支持最新的NVlink2.0协议,每颗GPU最多可以完成六根总线互联,每根总线的单向传输带宽可以到达25GB/s,六根总线可以完成单向150GB/s、双向300GB/s的IO带宽,相比NVlink1.0,带宽简直提升了1倍。
高混合精度计算才能让计算更高效
Tesla V100有NVlink和PCIe两个版本,计算中心都是GV100,均有5120个CUDA Cores以及640个Tensor Cores, NVlink 版本主频略高,双精度浮点计算才能到达7.5TFLOPS,单精度浮点计算才能到达了15TFLOPS,而混合精度计算才能可以到达125 TFLOPS ,PCIe版本有7TFLOPS双精度浮点计算才能、14TFLOPS单精度浮点计算才能和112个TFLOPS混合精度计算才能。
在训练 ResNet-50 时,单个V100 Tensor Core GPU的处置速度能到达1075 张图像/秒,与上一代Pascal GPU相比,它的功能进步了4倍。据测算,假设有100万张图片需求学习,实际上仅需约15分钟即可训练完成。
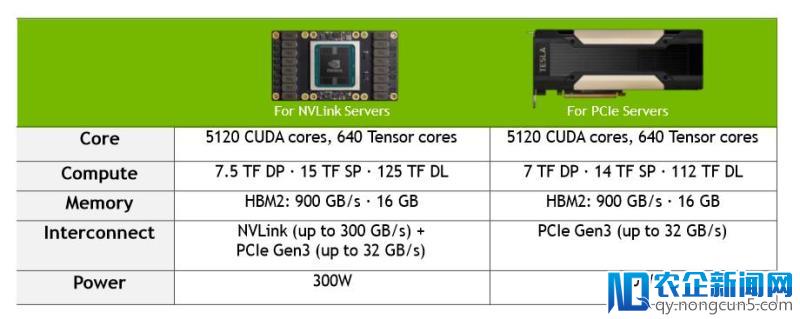
NVlink和PCIe版本Tesla V100比照
金山云作为国际首家正式商用Tesla V100的云效劳厂商,目前在售基于V100的效劳器有GPU云效劳器(P4V系列)和GPU物理效劳器(P4E系列)。杰出的深度学习计算功能,让用户可以愈加疾速、高效构建AI业务,弹性易扩展和高性价比的特性,可以为用户节省少量计算本钱,无效降低AI开发的工夫风险,进步企业AI竞争力。