
间隔Arm发布代号Bifrost的次世代GPU架构并推出Mali G71中心曾经两年了, 但是作为先锋的Mali G71在麒麟960和Exynos 8895中的表现都不尽人意,其功耗之拙劣显超出了预期。之后的Mali G72是一款更为合理的产品,它更接近Bifrost架构所承诺的能效目的,在麒麟970和Exynos 9810上完成了100%的能效提升。
明天,Arm发布了Mali G72的后续产品,也是Bifrost系列的最新产品:Mali G76,目的十分明白:进步单位功耗功能和单位面积面积,并尽能够地赶超竞争对手。Arm承诺,在台积电7nm工艺的支撑下,运用Mali G76的下一代SoC功能可进步50%。

横向来看,Mali G76重点改善了三个关键目标,首先是功能密度进步了30%,这意味着GPU面积不变,功能可进步30%;或许在功能相反时,可减少约24%的GPU面积。其次,Mali G76的微架构效率提升了30%,这要归功于架构内功用块的整合。最初,Arm为Mali G76添加了新的公用8位点积指令,使其机器学习推感性能进步了2.7倍。
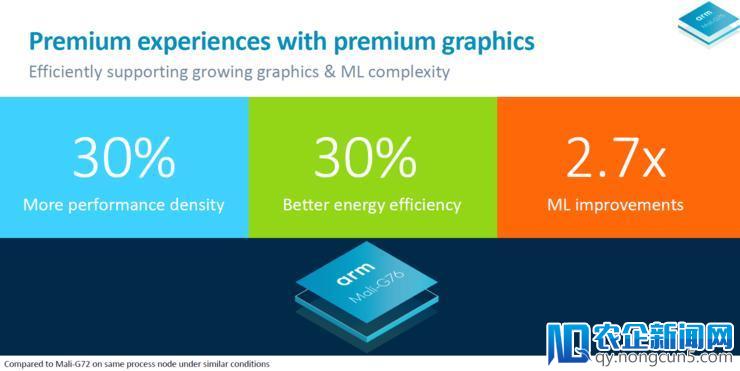
扩大架构规模
关于Arm的GPU设计来说,Bifrost曾经是一个古代的图形架构,3D图形技术在过来的两年中也没有发作严重革新。Mali G76在图形特性方面和Mali G72完全一样,变化集中在图形计算进程中。
与Mali G72相比,Mali G76在架构上的优化幅度更大。虽然它仍是Bifrost架构,但GPU的任务方式发作了很大变化。无论在挪动GPU还是桌面GPU范畴,Mali G76都是单个图形体系版本迭代中变化最大的之一。
前代Mali G71/G72的每个EU模块中包括4组FMA和ADD/SF流水线并组成一个线程粒度,Arm将这种模块构造称为“Quad”。随着技术和使用的开展以及挪动GPU在VR和高画质游戏范畴的压力不时添加,Quad构造的运算效率已逐步无法满足需求。

依据Arm的数据,Mali G76为了进一步进步架构的功能和面积效率,将GPU内的根底计算模块的规模添加了一倍,单个EU内拥有8组FMA和ADD/SF流水线。全新EU构造的面积并没有大幅添加,相比前代只提升了22%,但功能却失掉了明显提升。
这是一个十分风趣的变化,通常来说线程粒度的尺寸通常代表着硬件架构的典型特性。PC GPU的线程粒度曾经有许多年没有变化过了,NVIDIA自2006年至今不断坚持着32宽度,AMD则从2011年至今不断运用64宽度。
此前Bifrost架构所用的Quad构造,相比竞争对手架构的线程粒度(16~32宽度)要小很多。通常来讲,线程粒度反映了架构在资源/面积密度和功能之间的均衡点,较大的线程粒度可节省控制逻辑单元数量(单个32宽度线程粒度只需1个控制逻辑单元,而8个4宽度线程粒度需求8个控制逻辑单元)。

但线程粒度越大,控制单元填充它就越困难。Arm的GPU哲学总体上注重的是尽量防止执行停滞,经过运用更小的线程粒度降低线程发散的能够性。联系线程虽然并不难,但也会形成功能损失。
Arm在推出Bifrost架构时表示,他们采用了4宽度线程粒度,以增加因线程发散所形成的ALU(算术逻辑单元)闲置。这从实际上看是一种很好的战略,假如运算中有少量分支代码,那么因线程发散而闲置的ALU就没有了任何价值。
但是关于一个很小的线程粒度来说,控制逻辑单元与ALU的比率太高了,糜费了少量硬件规模。Mali G76换用8宽度线程粒度后,降低了控制逻辑单元与ALU的比率,在ALU吞吐量翻倍的状况下,EU模块的规模只比之前4宽度线程粒度时添加了28%。
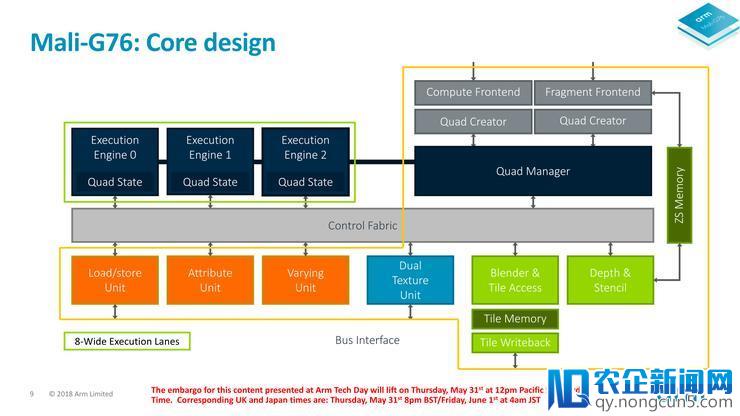
虽然Arm并没有做出更明白的解释,但雷锋网以为此次改动其实反映出Arm此前4宽度线程粒度的设计有些一厢情愿了,实践游戏中简直用不到这么小的尺寸。更致密的Quad构造也有助于扩大架构规模,Arm可以在单位面积上塞入更多ALU以提升功能。
与此同时,为了婚配翻倍的Quad尺寸,Arm将相应的缓存和通道也添加了一倍。虽然Arm没有正式披露Quad的存放器堆栈大小,但他们曾经证明Mali G76的存放器堆栈与Mali G72一样,每通道有64个存放器,因此存放器堆栈的压力并没有变化。
在像素和纹理方面,Mali G76也运用了双单元方案,每周期可以处置两个像素或两个纹理,ALU与像素和纹理单元的比例与之前坚持分歧。
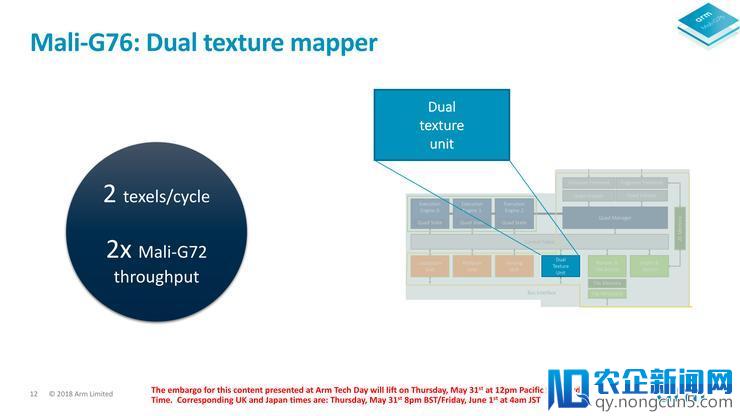
在相反的时钟速度下,Mali G76的浮点运算、纹理和像素吞吐量都添加了一倍,实践功能的提升幅度也应根本相仿。在某种意义上,Arm是将两个Mali G72中心交融成了一个Mali G76中心,但Mali G76到达Mali G72翻倍的功能只需132%的芯片面积,实际上单位面积功能提升了50%。
强化机器学习
虽然Arm大幅强化了Bifrost架构的图形渲染功能,但这不是Mali G76中心的独一改动,机器学习功能的提升也是此次的重头戏。
Arm为Mali G76的ALU强化了int8格式的支持,这一数据格式是处置神经网络的关键操作,在机器学习推理十分重要,虽然8位整数的精度无限,但在很多状况下依然足以停止根本推理。
虽然此前Mali G71/G72也可经过打包4个int8数据的办法停止计算,但Mali G76是第一个原生支持单周期处置int8的Mali中心。依据任务负载和机器学习蓬勃发展的行业不仅给从业者提供了巨大的发展机遇,也带来了全新的挑战。框架的不同,Mali G76的机器学习功能相比Mali G71/G72提升了约2.7倍。

同时Arm研讨发现,影响GPU功能的另一个潜在瓶颈是回写机制。假如GPU在一个多边形回写进程中停滞,则很能够会阻塞GPU的其他局部。Arm将Mali G76从有序回写机制转变为无序回写机制,允许经过绕过那些回写延迟来更灵敏地回写多边形。
此外Arm还优化了Mali G76块缓冲,在某些状况下颜色缓冲被耗尽时,可暂时溢出到深度缓冲中。这样可以增加对主内存停止拜访的次数,以尽能够坚持GPU中心的本地流量。Mali G76的线程本地存储机制也相应的针对存放器溢出处置停止了优化,GPU会将溢出的数据块分组在一同以利于未来获取。
功能和功耗预测
Arm的GPU中心设计一向都是组团群P的思绪,经过堆砌中心数量来抗衡高通Adreno的大中心无敌战略。
此前Mali G71/G72最多可支持堆砌32中心,但实践上没有任何一家SoC厂商选择过MP32的最大配置选项,最高也不过是三星Exynos 8895的Mali G71 MP20,其次是Exynos 9810的Mali G72 MP18,而华为的麒麟970运用了Mali G72 MP12,麒麟960则只要Mali G71 MP8。
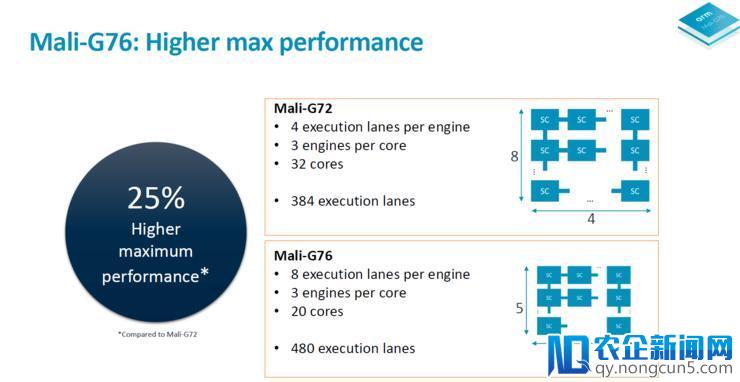
呈现这种景象的缘由恰恰是Mali G71/G72的单位面积功能太差了。以Exynos 9810的18核Mali G72为例,其GPU总面积为24.53 mm²,是高通Adreno 630(10.69 mm²)的2.3倍、苹果A11 GPU(15.28 mm²)的1.6倍,而功能却还不如Adreno 630和苹果A11 GPU。更遑论Exynos 8895下面积更大(32 mm²)功能更低的Mali G71 MP20。

三星Exynos 9810中心透视图
与三星的狂堆中心数相比,麒麟970和960则只运用了中等数量的中心,然后经过拉高中心频率来榨取功能。但是雷锋网 (大众号:雷锋网) 在上篇 剖析Cortex A76的文章 中提到过,每种中心架构在某一工艺下,都有一个能耗比最佳的频率区间,越过这个区间后,持续拉高频需求付出极大的功耗代价。
三星Exynos 9810和8895虽然GPU面积很大,但由于频率只要560MHz左右,因而功耗表现尚可。而麒麟970的Mali G72 MP12为746MHz,功耗上升十分分明,能耗比仅略高于运用Mali G71的Exynos 8895。麒麟960的Mali G71 MP8频率甚至高达1037MHz,暴增的功耗使其能耗比还不如老旧Exynos 7420上的Mali T760 MP8。
思索到实践运用中的状况,以及Mali G76中心规模的扩大,Arm决议将Mali G76的最大中心数量下调至20中心。经过将功用模块和执行引擎整合到更少的“内核”中来进步内核的功能密度,可显着改善GPU的单位面积功能。据估量,Mali G76在曼哈顿3.1测试中,每mm²功能提升了39%,
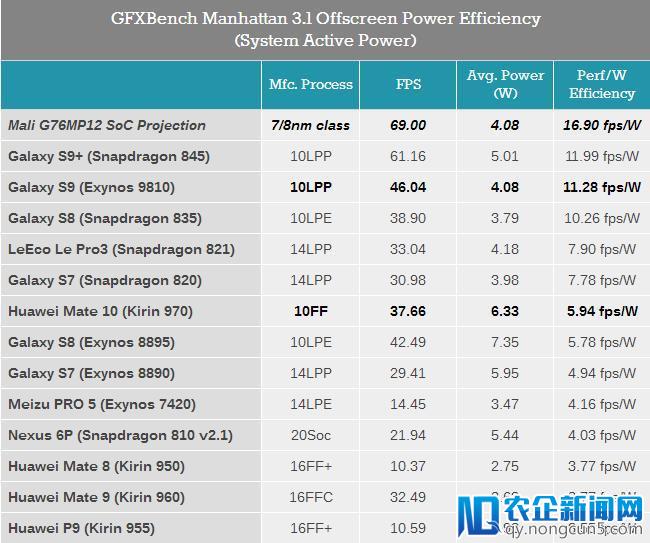
Arm表示,Mali G76 MP12在7nm工艺下,相比Mali G72 MP18将会有50%的功能提升,功耗则坚持分歧。而相比骁龙845的Adreno 630,Mali G76 MP12在拥有12.8%功能优势的同时,功耗下降了22.8%。(注:Mali G76 MP12频率不明)
结论与考虑
总的来说,Mali G76的提高十分分明——单位面积功能进步了30%,且功耗表现也有很大改善。但是雷锋网以为,虽然Mali G76将大大进步Arm公版GPU的竞争力,但仍然缺乏以借此一役赶超竞争对手。
在微架构优化方面,Arm确实在整合中心和增强中心方面做出了正确的选择。Arm公版GPU的多中心战略是一把双刃剑,它虽然允许厂商依据本身需求配置中心数量,但多中心也会招致不可防止的功能和面积损耗。Arm虽然预测了Mali G76 MP12的表现,但与高在互联网思维的影响下,传统服务业不再局限于规模效益,加强对市场的反应速度成为传统服务业发展的首要选择。在互联网思维下,通过对传统服务业的改革,为传统服务业发展创造了全新的天地。通Adreno 630和苹果A11的GPU相比,12核仍然太多了。
想想Mali G72 MP18与Adreno 630的比照,即使Mali G76的每平方毫米功能提升了39%,仍然无法抵消高达2.3:1的面积比。用7nm的Mali G76 MP12打赢10nm的Adreno 630并不能阐明什么,假如二者同为7nm工艺,不出不测Mali G76的能耗和面积仍然会有分明优势。
目前,雷锋网十分关注Mali G76在实践芯片中能有怎样的表现,同时希望Arm在将来能将每个EU的计算资源再添加一倍,这很能够将再次带来宏大的改良,进一步减少与竞争对手的差距。
via: Anandtech
相关文章:
浅析ARM全新Cortex A76架构:2.4GHz便可干掉骁龙845
。