
雷锋网按:本文为雷锋字幕组编译的技术博客,原标题 Step-by-step walkthrough of RNN Training - Part II,作者为 Eniola Alese。
翻译 | 陈涛 整理 | 凡江
RNN 的反向传达是为了计算出关于损失函数的梯度值
读者可以在这里看到本文的 Part I( https://www.leiphone.com/news/201805/ZMeniGUPBZ50lyvk.html )。
单个 RNN 单元的反向传达
RNN 中反向传达的目的是计算出最终的损失值 L 辨别对权值矩阵(W_xh,W_ah,W_ao)和偏置向量(b_h,b_o)的偏导数值。

推导出所需的导数值十分复杂,我们只需求应用 链式规律 就能计算出它们。
第一步: 为了计算代价,需求先定义损失函数。普通依据详细手中的义务来选择该损失函数。在这个例子里,关于多分类输入成绩,我们采用穿插熵损失函数 L⟨t⟩,其详细计算进程如下:

第二步: 接上去我们开端往后计算损失函数 L⟨t⟩ 对预测输入值的激活值 ŷ⟨t⟩ 的偏导数值。由于在前向传达进程中 softmax 函数以多分类的输入值作为输出,因而上面的偏导数值
的计算分为两种状况:分类 i 时和分类 k 时:

第三步: 接着应用分类 i 时和分类 k 时的偏导数值
,可以计算出损失函数 L⟨t⟩ 对预测输入值 o⟨t⟩ 的偏导数值:

第四步: 应用偏导数值
及链式规律,计算出损失函数 L⟨t⟩ 对输入进程中的偏置向量 b_o 的偏导数值:
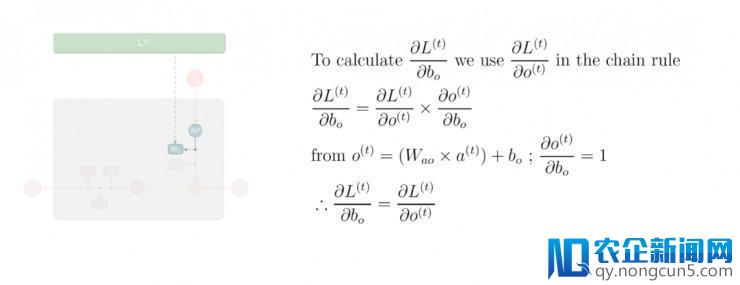
第五步: 应用偏导数值
及链式规律,计算出损失函数 L⟨t⟩ 对隐层至输入层中的权值矩阵 W_ao 的偏导数值:
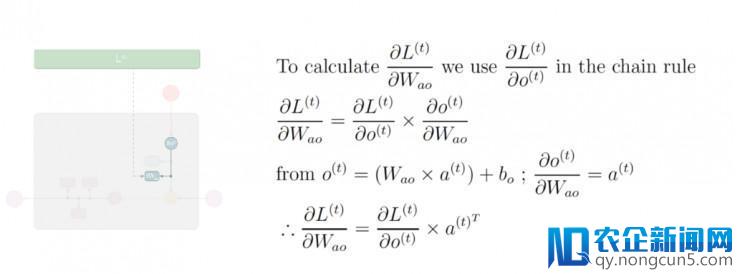
第六步: 应用偏导数值
、
及链式规律,计算出损失函数 L⟨t⟩ 对隐形态的激活值 a⟨t⟩ 的偏导数值:

第七步: 应用偏导数值
及链式规律,计算出损失函数 L⟨t⟩ 对隐形态 h⟨t⟩ 的偏导数值:
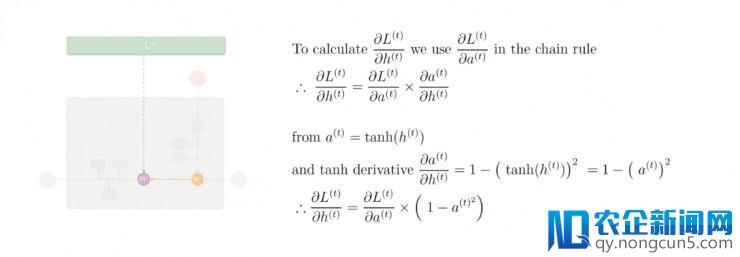
第八步: 应用偏导数值
及链式规律,计算出损失函数 L⟨t⟩ 对隐形态的偏置向量 b_h 的偏导数值:
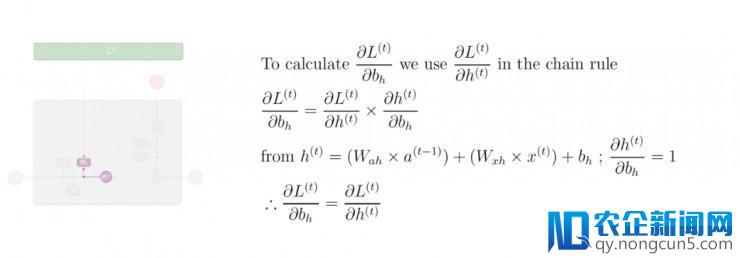
第九步: 应用偏导数值
及链式规律,计算出损失函数 L⟨t⟩ 对输出层至隐层中的偏置矩阵 W_xh 的偏导数值:
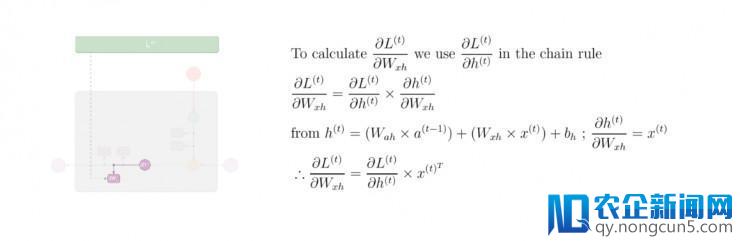
第十步: 应用偏导数值
及链式规律,计算出损失函数 L⟨t⟩ 对输出层至隐层中的偏置矩阵 W_ah 的偏导数值:
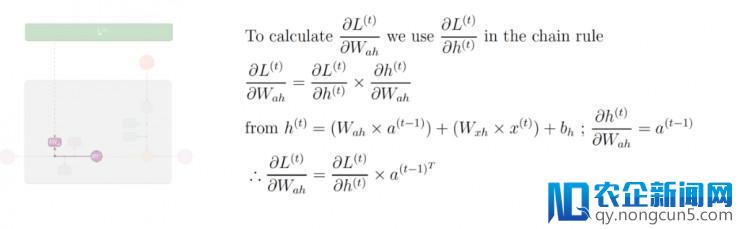
随工夫反向传达(BPTT)
就像前文中提到的前向传达进程一样,将循环网络展开,BPTT 将沿此不断运转着上述步骤。
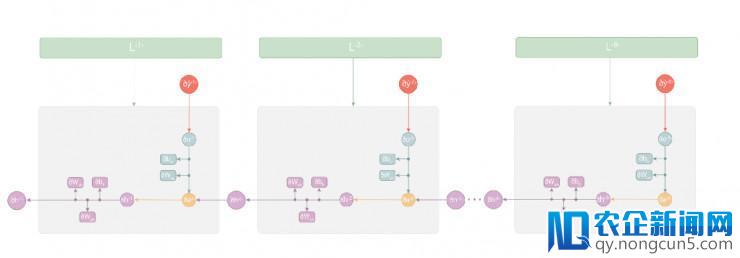
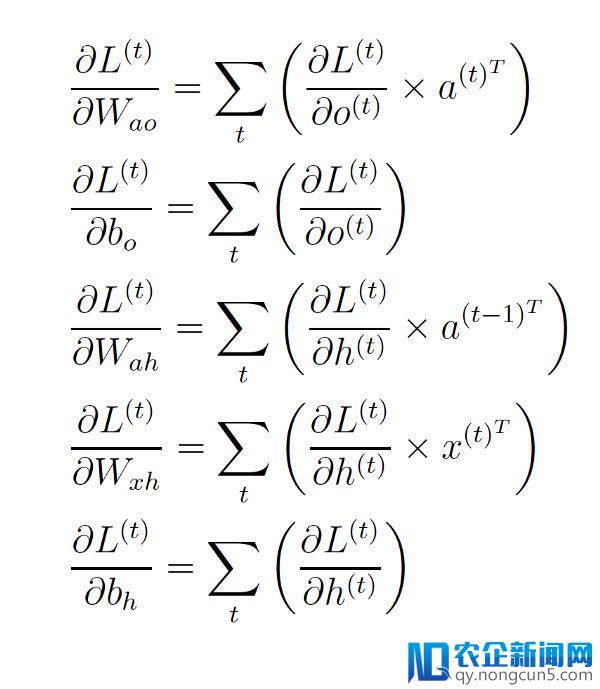
次要的区别在于我们必需将每个工夫步 t 的偏导数值
累加起来,从而更新权值和偏置,这是由于这些参数在前向传达的进程中是被各个工夫步所共享的。
总结
在本文的第一局部和第二局部中,我们理解了循环神经网络训练进程中所触及到的前向传达和反向传达。接上去,我们将着眼于 RNN 中所存在的梯度消逝成绩,并讨论 LSTM 和 GRU 网络的停顿。
博客旧址: https://medium.com/learn-love-ai/step-by-step-walkthrough-of-rnn-training-part-ii-7141084d274b

雷锋网 (大众号:雷锋网) 雷锋网
。