
雷锋网按:本文为雷锋字幕组编译的技术博客 A Simple Guide to the Versions of the Inception Network,原标题,作者为 Bharath Raj。
翻译 | 胡瑛皓 乔月 整理 | 凡江
Inception 网络是卷积神经网络 (CNN) 分类器开展中的一个重要里程碑。在 inception 之前, 大少数盛行的 CNN 只是将卷积层堆叠得越来越深,以期取得更好的效果。

这就是 CNN 架构设计。风趣的是这个说法在第一篇 inception 网络的论文( https://arxiv.org/pdf/1409.4842v1.pdf )中被援用。
从另个方面来看 Inception network 是复杂的(少量工程优化)。运用很多的技巧以进步其功能 (同时从速度和精确率)。随着不时演进,也发生了几个不同版本的网络。以下是几个盛行的版本:
-
Inception v1(https://arxiv.org/pdf/1409.4842v1.pdf )
-
Inception v2 与 Inception v3(https://arxiv.org/pdf/1512.00567v3.pdf )
-
Inception v4 与 Inception-ResNet(https://arxiv.org/pdf/1602.07261.pdf )
下面每个版本均是对其前一个版本的迭代改良。了解版本晋级的细节可以协助我们构建自定义分类器,同时进步速度和精确率。另外,依赖于你的数据,低版本能够实践上效果更好。
本文旨在说明 inception network 的演进。
Inception v1
这个版本是一切开端的中央。让我们剖析一下,最后的版本计划处理什么成绩,以及它是如何处理成绩的。( https://arxiv.org/pdf/1409.4842v1.pdf )
前提:
-
图像中的特征局部尺寸变化很大。比方包括狗的图像可以是以下任一种方式,如下所示。狗在每幅图像中所占面积不同。

从右边到右:狗占据了图片的大局部,狗占据了图片的一局部,狗仅占据了图片的很小一局部(图片来自 Unsplash)。
-
正是由于在信息所在地位的宏大差别,为卷积操作选择适当的核尺寸变得困难。当信息散布更全局时,倾向选择一个较大的核;当信息散布的更部分时,倾向选择一个较小的核。
-
深度网络容易过拟合,同时也很难将梯度更新传递至整个网络。
-
单纯堆砌少量卷积操作计算昂贵。
处理方案:
那为什么不能在同一层上采用多个尺寸的过滤器呢?网络实质上会变得更宽一些,而不是更深。作者设计 inception 模块就是用了这个想法。
下图就是「最后的」inception 模块。在输出图像上用 3 个不同尺寸的过滤器(1x1, 3x3, 5x5)施行卷积操作。然后,执行了最大池化操作 (max pooling)。输入被衔接(concatenated)后,送往下一层 inception 模块。
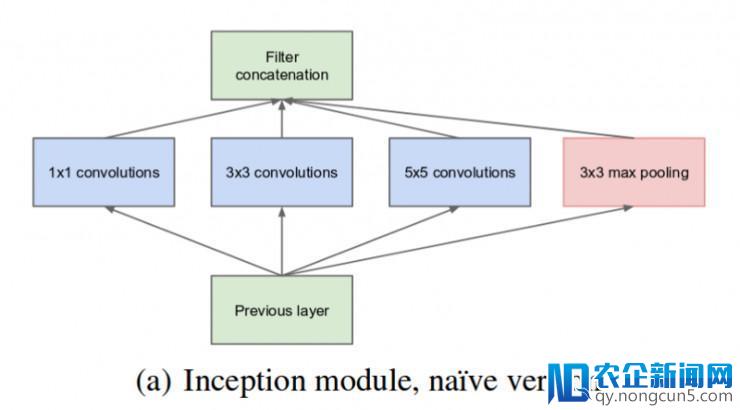
最后的 inception 模块(原文:Inception v1: https://arxiv.org/pdf/1409.4842v1.pdf )。
如前所述,深度神经网络计算十分昂贵。为了使计算更快,作者经过在 3x3 和 5x5 卷积操作前添加一个额定的 1x1 卷积,限制输出通道数量。虽然添加一个额定的操作看起来与直觉相反,1x1 卷积比 5x5 卷积操作快很多,增加输出通道数量也有协助。值得留意的是,1x1 卷积是在最大池化后执行,而不是之前。
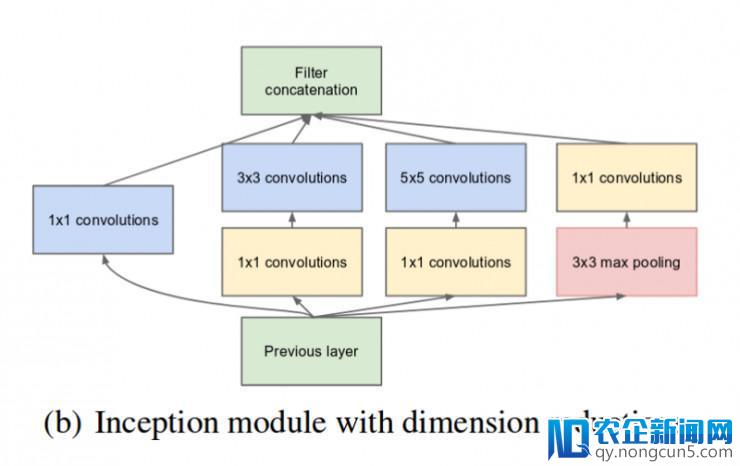
降维的 inception 模块(原文:Inception v1: https://arxiv.org/pdf/1409.4842v1.pdf )
采用降维的 inception 模块构建神经网络,这就是我们晓得的 GoogLeNet(Inception v1)。网络架构如下:
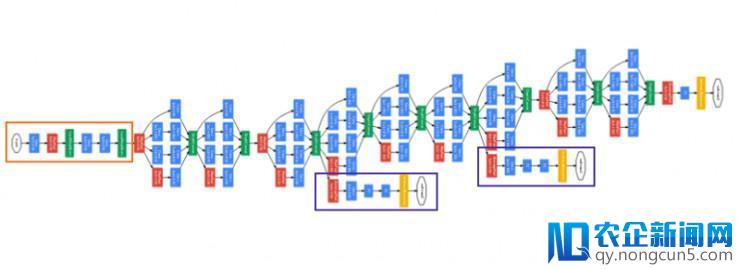
GoogLeNet. 橙色框是 stem,包括一些根底的卷积操作。紫色框是辅佐分类器。网络中开阔局部是 inception 模块(原文:Inception v1: https://arxiv.org/pdf/1409.4842v1.pdf )
GoogLeNet 由 9 组 inception 模块线性堆叠组成。深 22 层(如算上池化层共 27 层)。在最初一个 inception 模块,采用了全局均匀池化操作。
它的确是一个很深的深度分类器。关于恣意深度神经网络都会发作梯度消逝成绩。
为避免网络两头局部不会「梯度消逝」,作者引入了 2 个辅佐分类器(图中紫色框)。它们实质上对 2 个 inception 模块的输入执行 softmax,并计算对同一个标签的 1 个辅佐损失值。总损失函数是对辅佐损失值和真实损失值的加权和。论文中辅佐损失值的权值取 0.3。
无须置疑,辅佐损失值地道是为训练构建,分类推断时将被疏忽。
Inception v2
Inception v2 、Inception v3 呈现在同一篇论文( https://arxiv.org/pdf/1512.00567v3.pdf )。作者提出了少量的改良以提升精确度同时降低计算复杂度。Inception v2 探究了以下内容:
前提:
-
降低 representational bottleneck。其思绪是,当卷积不会大幅改动输出尺寸,神经网络的功能会更好。增加维度会形成信息少量损失,也就是所说的 representational bottleneck;
-
采用智能分解办法,卷积操作在计算上更高效。
处理方案:
-
将 1 个 5x5 卷积分解为 2 个 3x3 卷积操作以提升速度。虽然这能够看起来与直觉相反,5x5 卷积比 3x3 卷积操作在计算上要昂贵 2.78 倍。因而,现实上 2 个 3x3 卷积的堆叠进步了功能。见下图:
最右边 inception v1 模块中的 5x5 卷积如今表示为 2 个 3x3 卷积(原文: Inception v2: https://arxiv.org/pdf/1512.00567v3.pdf )
-
此外,他们将 nxn 的卷积过滤器分解为一个 1xn 和 nx1 卷积的组合。比方一个 3x3 的卷积等价于执行一个 1x3 的卷积后执行一个 3x1 的卷积。他们发现,这个办法较之前的 3x3 卷积在算力上廉价 33%。如下图所示:
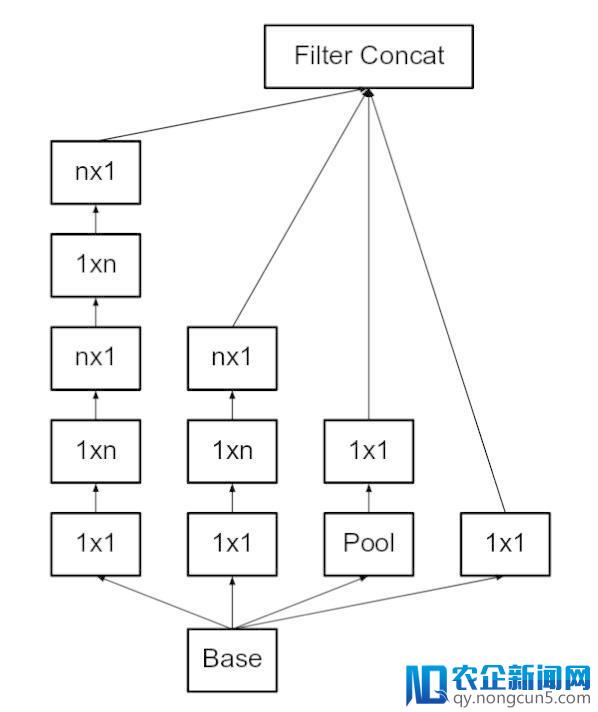
这里,假定 n=3 取得与之前等价的图像。最右边 5x5 的卷积可以表示为 2 个 3x3 卷积,然后进一步表示为 1x3、3x1 卷积组合(原文:Inception v2: https://arxiv.org/pdf/1512.00567v3.pdf )
-
模块中的滤波器组(filter banks)被扩展(使得更宽而不是更深)以消弭 representational bottleneck。假如模块变得更深,尺度将会过度减少,从而招致信息的丧失。如下图所示:
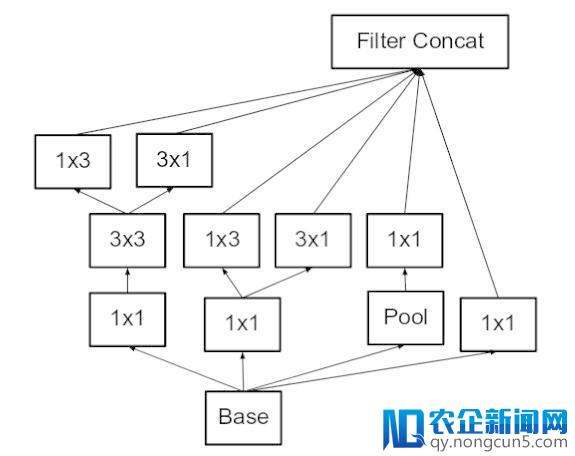
使 inception 模块更宽。这品种型同等于下面显示的模块。(原文: Incpetion v2: https://arxiv.org/pdf/1512.00567v3.pdf )
-
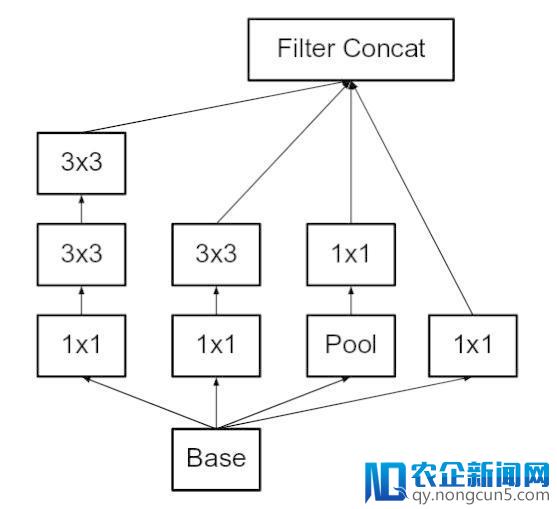
上述三个准绳被用来构建三种不同类型的 inception 模块(我们将它们依照引入的顺序称为模块 A,B, 和 C,这些称号是为了清楚而引入的,并不是官方的名字)体系构造如下:
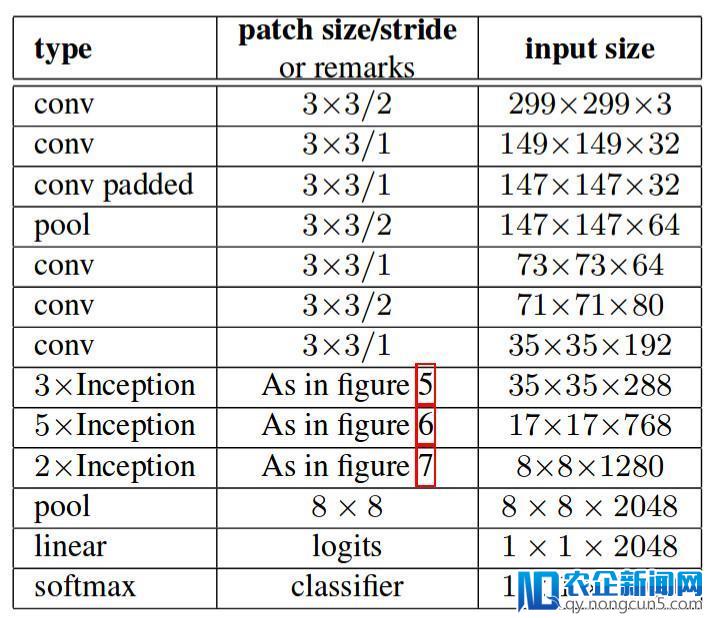
这里,图 5是模块 A,图 6是模块 B,图 7是模块 C。(原文: Incpetion v2: https://arxiv.org/pdf/1512.00567v3.pdf )
Inception v3
前提:
-
作者指出,辅佐分类器(auxiliary classifiers)直到训练进程完毕,精确性接近饱和时,没有太多的奉献。他们以为,他们的功用是正轨化(regularizes),特别是假如他们有 BatchNorm 或 Dropout 操作。
-
研讨不在大幅度改动模块的状况下,改良 Inception v2 的能够性。
处理方案:
-
Inception Net v3 包括了针对 Inception v2 所述的一切晋级,并且添加运用了以下内容:
-
RMSProp 优化器。
-
分解为 7x7 卷积。
-
辅佐分类 BatchNorm。
-
标签平滑(添加到损失公式中的正则化组件类型,避免网络过于精确,避免过度拟合。)
Inception v4
Inception v4 和 Inception-ResNet 被引见在同一篇论文。为了明晰起见,让我们辨别讨论他们。
前提:
为了使模块愈加一致,作者还留意到一些模块比必要的还要复杂。这可以使我们经过添加更多的一致模块进步其功能。
处理方案:
-
Inception v4 中 stem 被修正了。这里的 stem,指的是在引见 Inception 块之前执行的最后一组操作。
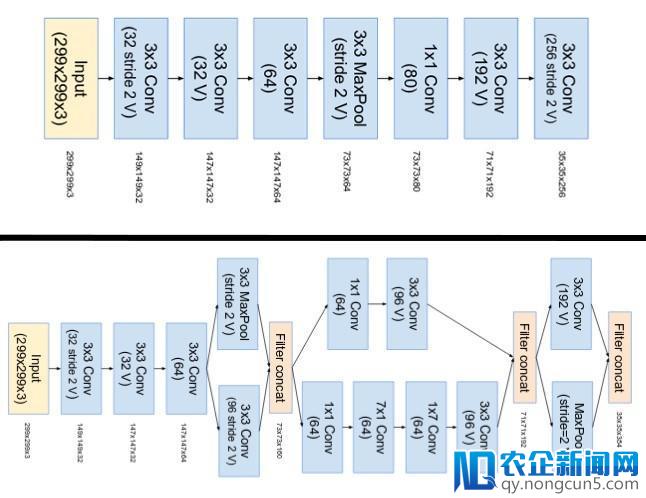
上图是 Inception-ResNet v1 的 stem,底部图像是 Inception v4 和 Inception-ResNet v2 的 stem (原文: Inception v4: https://arxiv.org/pdf/1602.07261.pdf )
-
他们有三个次要的 inception 模块。辨别为 A,B 和 C (与 Inception v2 不同 这些模块的实践名字为 A,B 和 C). 它们看起来十分相似与 Inception v2 (or v3) 正本。
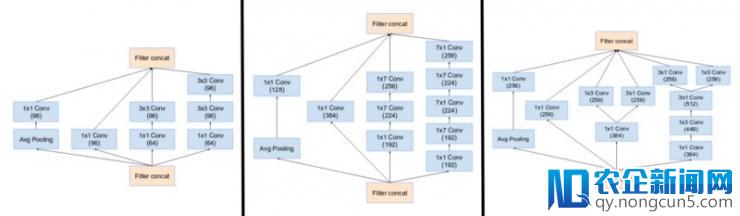
(左图)Inception 模块 A,B,C 运用 Inception v4。留意它们与 Inception v2(或 v3)模块类似。(原文: Inception v4: https://arxiv.org/pdf/1602.07261.pdf )
-
Inception v4 采用专门的「Reduction Blocks」用于更改网格的宽度和高度。晚期的版本没有明白的增加块(reduction blocks)但是功用曾经完成。
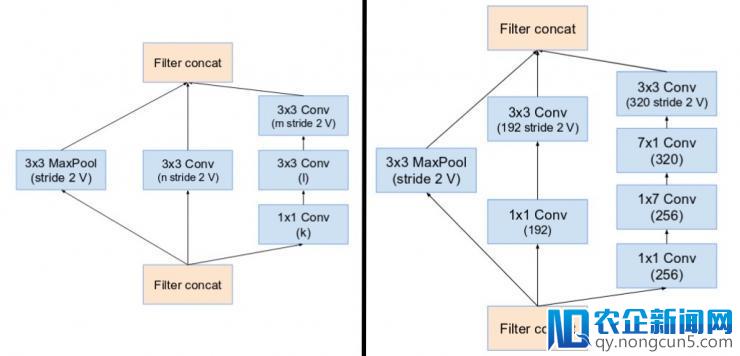
(左图) Reduction Block A (将 35x35 尺寸减少至 17x17 ) Reduction Block B (将 17x17 尺寸减少至 8x8)。请参阅本文以获取确切的超参数设置 (V,l,k). (原文: Inception v4: https://arxiv.org/pdf/1602.07261.pdf )
Inception-ResNet v1 and v2
遭到 ResNet 功能的启示,提出一种混合 inception 模块。Inception ResNet 有两个子版本散布为 v1 和 v2。在我们反省明显特征之前,让我们看看这两个版本之间的纤细差异。
-
Inception-ResNet v1 有相似于 Inception v3 的计算本钱。
-
本次涌现的 AI、区块链和物联网热潮不同于以往,将对产业、社会和生活产生真正堪称“颠覆性”的变革。IT 技术人员需要全方位地“换脑”:对原有的知识结构进行全面刷新,全面升级。 Inception-ResNet v2 有相似于 Inception v4 的计算本钱。
-
它们有不同的 stems 如插图 Inception v4 局部所示。
-
两个子版本关于模块 A,B,C 和 reduction blocks 具有相反的构造。只要超参数 设置不同。本节中,我们只关注构造。请参阅本文中确实切超参数设置 (图像是 Inception-Resnet v1)。
前提:
-
在 inception 模块输出中引入残差衔接(residual connections),它添加了卷积运算的输入。
处理方案:
-
关于剩余任务的补充,卷积后的输出和输入必需具有相反的尺寸。因而,我们在原始卷积之后运用 1x1 卷积来婚配浩大尺寸(深度在卷积之后添加)。
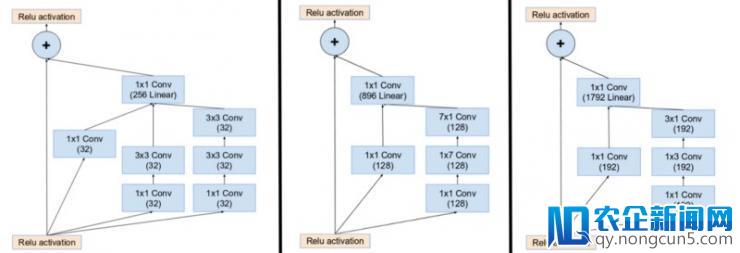
(左图) 在 Inception ResNet 中初始化 Inception 模块 A,B,C。留意如何用残差衔接(residual connection)替代池化层(pooling layer),另内在添加前,留意附加 1x1 卷积。(原文: Inception v4: https://arxiv.org/pdf/1602.07261.pdf )
-
在主 inception 模块中,池化操作被替代,有利于残差衔接(residual connections)。但是,你依然在 reduction blocks 中找到这些操作。reduction blocks A 与 Inception v4 相反。
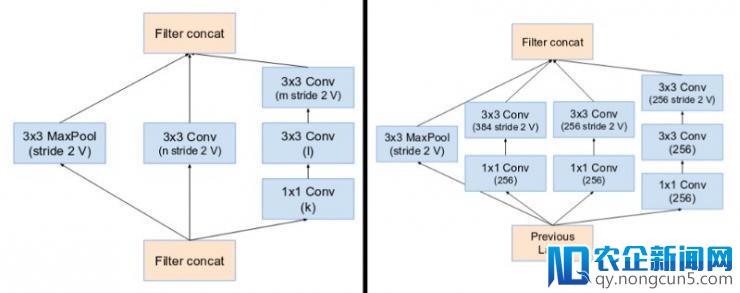
(左图) Reduction Block A (35x35 尺寸减少至 17x17 ) Reduction Block B (17x17 尺寸减少至 8x8 )。请参阅本文中的准确超参数设置 (V,l,k). (原文: Inception v4: https://arxiv.org/pdf/1602.07261.pdf )
-
假如滤波器(filters)数目超越 1000,那么网络中的残差单元(residual units) 更深的网络会招致网络「死亡」。为了进步波动性,作者将残差(residual) 激活的比例调整为 0.1 至 0.3 左右。
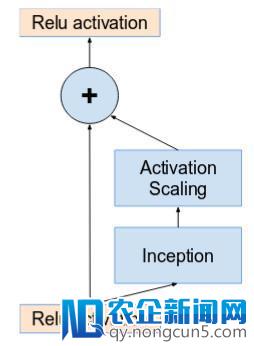
激活按常数缩放,以避免网络解体。(原文:Inception v4 https://arxiv.org/pdf/1602.07261.pdf )
-
原始论文在求和之后没有运用 BatchNorm 在单个 GPU 上训练模型(为了将整个模型装置在单个 GPU 上)。
-
发现 Inception-ResNet 模型可以在更低的 epoch 取得更高的精度。
-
Inception v4 和 Inception-ResNet 最终的网络规划如下:
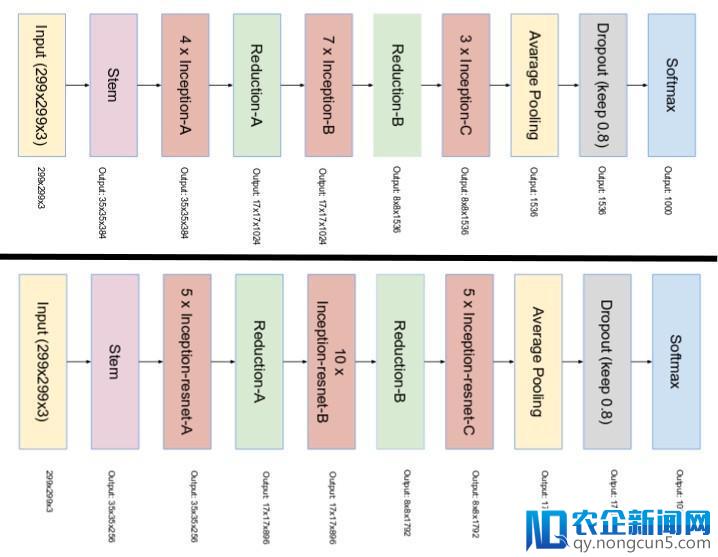
顶部图像是 Inception v4 的规划,底部图像是 Inception-ResNet 的规划。(Source: Inception v4: https://arxiv.org/pdf/1602.07261.pdf )
原文链接: https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202
雷锋网雷锋网
(大众号:雷锋网)
。
