
雷锋网 AI 研习社按,本文为 IJCAI-18 阿里妈妈搜索广告算法大赛亚军处理方案。本文由作者发在其 GitHub 主页,雷锋网 (大众号:雷锋网) AI 研习社获其受权转载。
一、 队员引见
队长:BRYAN
数据发掘从业者,国际数据发掘竞赛名将,天池数据迷信家,IJCAI-17 冠军取得者。曾屡次在国际外著名赛事中获得名次。
队员:桑楡
数据发掘从业者,国际数据发掘竞赛名将,天池数据巨匠,IJCAI-17 冠军取得者。曾屡次在国际外著名赛事中获得名次。
队员:李困困
数据发掘从业者,国际数据发掘竞赛名将。曾获得 CCF-蚂蚁金服-商场定位赛冠军等多项国际外著名赛事的名次。
二、 赛题背景剖析及了解
本赛题为搜索广告转化预估成绩,一条样本包括广告点击相关的用户(user)、广告商品(ad)、检索词(query)、上下文内容(context)、商店(shop)等信息的条件下预测广告发生购置行为的概率(pCVR),方式化定义为:pCVR=P(conversion=1 | query, user, ad, context, shop)。可以将成绩笼统为二分类成绩,重点对用户,商品,检索词,上下文,商店停止特征描写,来训练模型。
三、 中心思绪
(1) 数据剖析
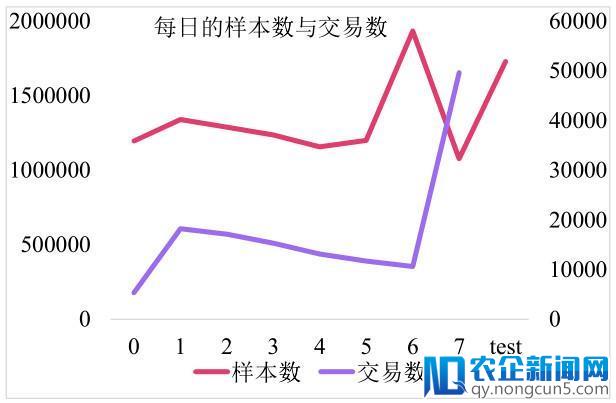
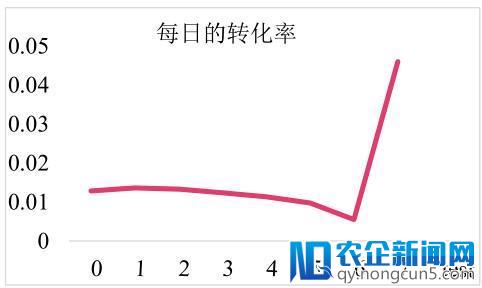
经过数据剖析我们发现,训练数据的前 7 天转化率维持在 1% 左右,但是在 6 号转化率偏低,在预测当天 7 号的上午转化率超越 4%,所以这是一个对特定促销日停止预测的成绩。重点需求描写用户,商品,店铺,检索词等关键信息在预测日后面 7 天的行为,预测日前一天的行为,预测日当天的行为。
另外 7 号的样本量远远超越后面每天的样本量均值,是我们重点需求关注的工夫区间。主模型是基于 7 号上午的样本停止训练,后面 7 天的数据辅佐训练。由于预估工夫为 7 号下午,工夫相关的特征没法在上午训练,为了补偿 7 号上午训练带来是数据和信息损失,我们队伍采用了两种方式:,一种采用后面 7 天训练模型预估 7 号失掉概率作为新的特征,一种是训练 7 号之前以及 7 号上午训练全量模型停止加权。
(2) 用户剖析
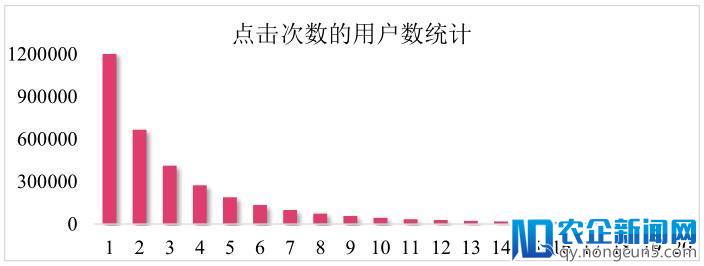
从下图可以看到大局部用户的点击次数集中在 5 次以下,8 天的工夫内点击 5 次,阐明这是一个低频诉求的场景。
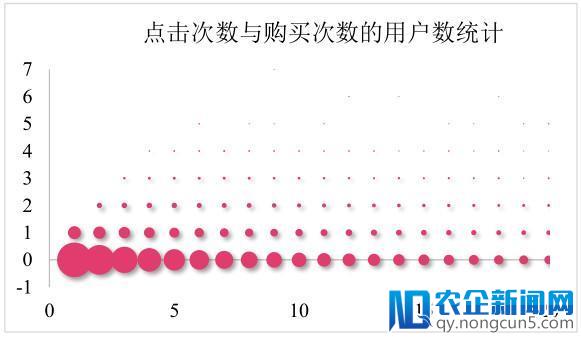
在下图中可以看到,大局部用户都没有购置行为,大批用户购置了一次,本次竞赛的目的预测用户能否购置,大批的购置行为构成了数据的长尾散布情势。

下图是用户点击次数和购置次数的关系,横轴点击数,纵轴购置数。可以看到数据是呈左下角散布的趋向,也就是说购置行为发作在大批点击次数的状况下,阐明这是一个即时兴味,目的明白的场景。我们需求重点描写用户以后形态。
从用户剖析中,我们发现,点击一次的用户占据较大的比例,这局部无法经过历史行为的特征描写表征,因而提供的 query 信息是表征这局部用户的关键;同时,绝大局部用户没有发作购置行为,因而,负样本中包括了少量的信息,另外评价目标是 logloss,需求准确预测购置概率,所以并未对负样本停止采样,防止毁坏正负样本散布。
(3) 预处置
缺失值填充:id 类特征运用众值填充,数值特征均值填充
发掘隐藏信息:针对 item_property_list 列,统计 property 呈现次数,保存呈现次数的 top1~top10 作为新的 id 特征;针对predict_category_property 列,直接按顺序保存 top1~top10 的类别作为新的 id 特征。针对 item_category_list 列,由于第一个大类都相反,取第二个类别作为新的 id 类特征。
(4) 线下划分

由于线上提交的次数无限,因而,树立波动的线下是取胜的关键。为提升我们优化算法的效率,增加线上成果的运气性成分,同时防止我们的算法过度依赖于线上数据集,我们仔细地停止了线下测试,辨别采取 7 日上午最初两个小时,7 日上午随机 15%的数据停止验证,只要两者在线下均有提升,我们才停止线上提交。因而,我们一直确保我们在线上验证的优化在线下均有明显的提升。
(5) 模型设计
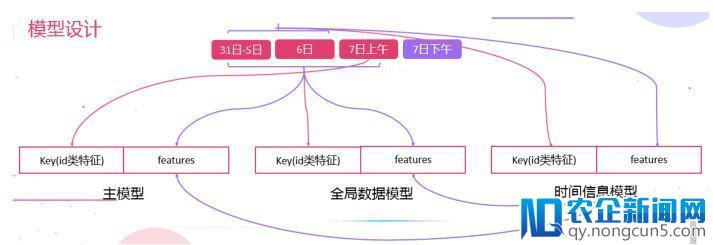
我们采用了 3 种数据划分方式训练模型,主模型运用 7 号上午的数据作为训练样本,对 31-5 号,6 号,7 号的数据提取特征。全局数据模型运用全部带标签的样本作为训练样本,运用全部数据提取特征。工夫信息模型运用 31-6 号的数据作为训练样本,对 31-6 数据提取特征。训练的工夫信息模型对 7 号全天的样本停止预测,将预测后果(携带了工夫信息)作为新的特征添加到后面的模型中,来补偿后面模型对工夫描写的缺失。
(6) 特征工程
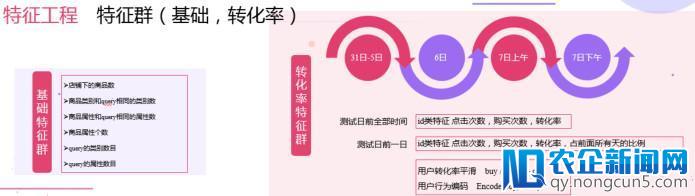
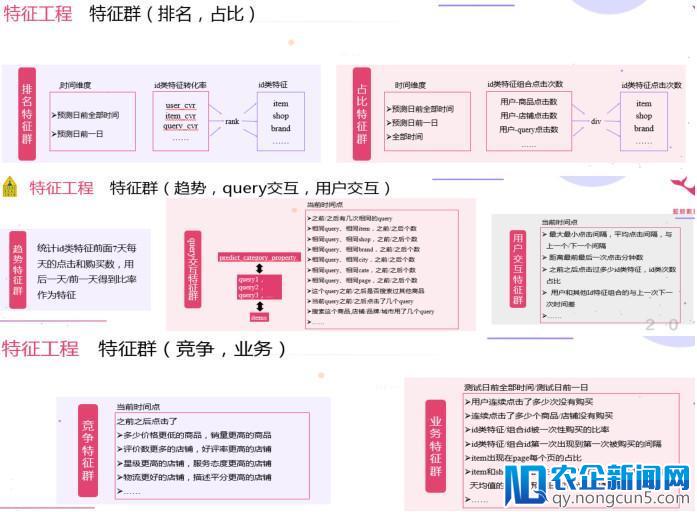
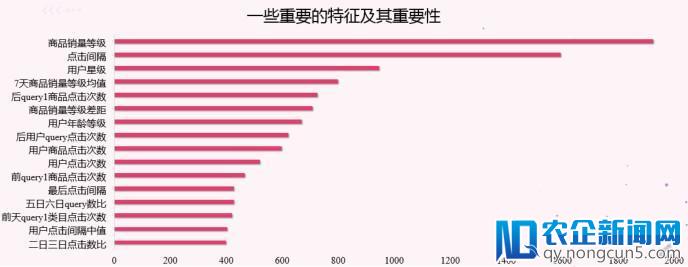
特征工程是模型提分的关键,我们从复杂到复杂树立了根底特征群,转化率特征群,排名特征群,比例特征群,类特征群,竞争特征群,业务特征群等多种特征群,对用户及行为停止了细致的描写。

在原始特征的根底上的一些复杂扩大与统计,由于用户的行为过于稀疏,提取用户转化率的时分做了平滑,另外对用户购置点击行为做编码。在 query 交互,用户交互,竞争特征群中,计算量较大,采用并行的方式提取,提升效率。
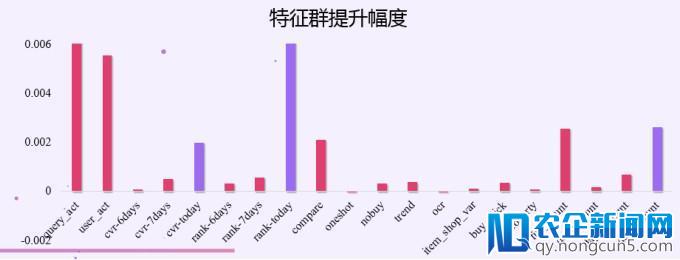
为了进步效率,我们采用分批测试特征群的方式停止线下验证。其中紫色特征群是过拟合的特征群,线下表现突出,在线上表现平平。究其缘由是由于,这些特征都是对当天上午的数据停止统计,即便我们运用穿插的方式提取,尽量防止数据穿越,由于上午下午数据散布有差别,所以仍然没能很好的克制过拟合。
(7) 模型交融
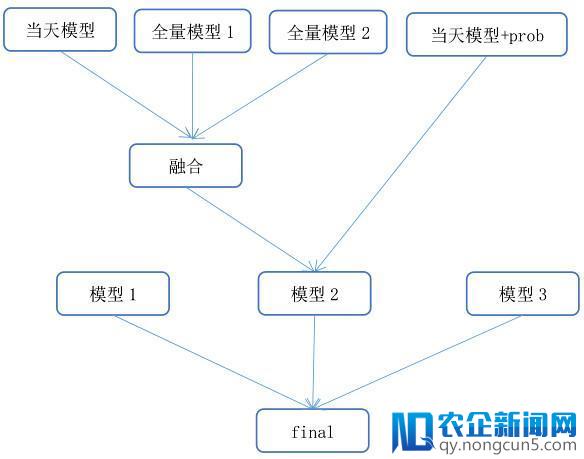
不同模型好而不同是交融提升的关键,我们队伍队员辨别做了三个高分模型,每个模型在样本与特征上均有差别,因而,经过交融进一步提升了成果。最好的单模型仍然能坚持 top2 的成果。
四、 工程优化
为了使模型更具业务虚用性,我们对代码停止了优化,次要包括上面四个方面:
1)id 类特征重编码,直接当作特征,树模型深度设置-1,防止了onehot 少量占用内存空间,实践效果和 onehot 相当。
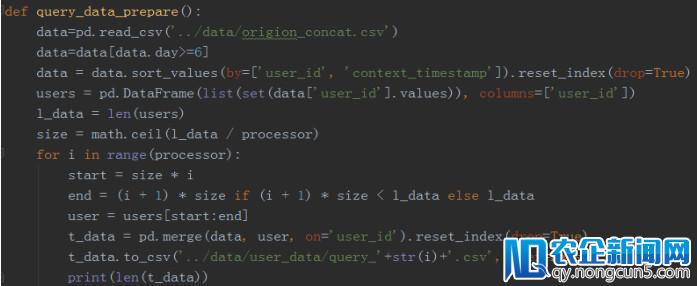
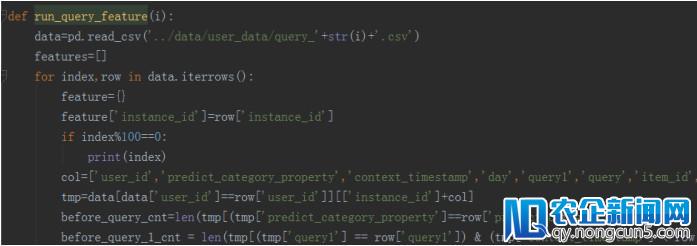
2)数据并行,主模型 2 小时提取完全部特征。由于 python 的多进程中,子进程会拷贝父进程形态,假如直接把数据分块然后运用多进程会招致内存暴跌,所以我们的处理方案是先将数据分块存为磁盘文件,然后在多进程义务中辨别读取各自数据提取特征,最初兼并特征,无效的增加了内存占用。
3)数据兼并,训练预测数据一同提取特征。直接运用 day,hour 等字段在提取特征终了之后划分训练,验证,测试集。进步了特征提取,线下测试,线上预测的流程效率。
4)特征分批测试,进步效率。由于复赛数据量比拟大,假如运用warper类的特征选择办法会糜费少量工夫,所以我们直接按特征群分批测试,运用原始特征+测试特征群的方式停止线下验证,大批的特征得以疾速迭代验证。
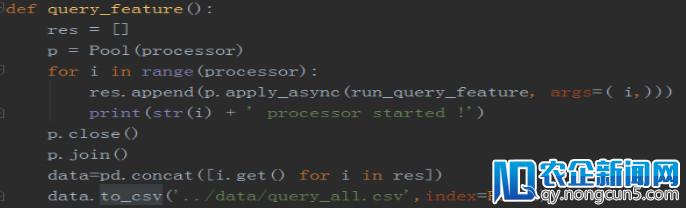
5)并行特征提取的关键代码
数据分块存储
特征提取
特征兼并
五、 竞赛经历总结
(1)深入的赛题了解
对赛题停止仔细而感性的剖析和片面而深化的考虑,对不理解之处做相应的调研。
(2)细致的数据剖析
从各个维度对数据停止细致的察看和剖析,从中发掘出重要的规律。
(3)海量的特征
多角度地提取无效特征,结构宽广而高质量的特征陆地,确保没有脱漏有用的信息。
(4)强力的模型
训练多组不同采样方式、不同特征的强力模型,并将它们交融成威力宏大的终极模型。
(5)未完成的考虑
赛题背景是搜索转化预估,可以直接运用的数据是用户曾经点击过的数据,实践上我们还可以拿到用户看到过,但是没点击的数据来辅佐训练。一个 query 会出多个商品,用户能够只点击了其中一个,如何获取用户看到的其他商品呢?关键还是在 query 上,假如有其他用户用异样的 query 停止了搜索并且点击了不同的商品,那么这个商品能够就是被其他没有点击的用户看到过的。
(6)竞赛与实践业务的差距
在本次竞赛中,我们运用了少量的特征以及模型交融,其中存在两个需求讨论的成绩。首先是特征,我们运用了局部用户以后形态的特征,比方间隔上一次点击工夫距离,间隔下一次点击工夫距离。第一个特征在实践业务中,需求实时提取,如何设计实时特征的计算框架,功能能否跟上都是需求思索的成绩。第二个特征间隔下一次点击工夫距离,这个特征甚至在实践业务中基本提取不到,属于将来的信息,但是在竞赛中却可以应用到。假如把预测工夫段的用户数据调整为一个用户只呈现一次,那么这个成绩就可以失掉很好的处理。
随之而来的另一个成绩是,用户只呈现一次,就无法统计到用户以后形态的其他未应用到将来信息的特征,像商品店铺的统计信息也不完全,会惹起一个信息缺失的成绩。所以如何在竞赛与实践业务中均衡数据的应用水平是一个需求思索到的成绩。另外一个是模型设计的成绩,实践业务中简直不太能够会用到 stack 之类的模型交融方案,模型复杂度带来的计算代价和线上预估工夫的代价能够会超越模型交融功能提升带来的收益,实践业务复杂加权交融能够会成为少数时分的选择。
本次竞赛我们选择了 LightGBM 模型,由于数据量少,训练快,可以在线下疾速迭代。在实践业务中,运用的更多的模型能够是 LR,FFM,DNN 之类的模型,实践业务的数据是海量的,这些模型更能学习到波动鲁棒的参数,并且预估速度更快。由于正负样本比例悬殊,假如思索训练效率的话,其实也可以对负样本停止采样后训练,比方 LR 模型训练之后经过对截距项的修正,仍然可以坚持预估的数据契合实践散布。
六、 团队亮点
(1)弱小的阵容
聚集三位优秀的数据发掘竞赛选手。
(2)分歧的目的
队员们对本次竞赛的目的分歧而明白(虽然最终并未达成)。
(3)良好的沟通
队员们频繁地对赛题停止讨论,及时地同步各自的停顿。
(4)完满的配合
队员们辨别训练不同的模型,彼此的模型差别极大,特别合适停止
交融。
(完)
GitHub 地址: https://github.com/YouChouNoBB/ijcai-18-top2-single-呼吁行业者在政府部门出台相关政策标准的之前,从业者一定要规范自己的行为准则健康有序的快速发展。mole-solution
雷锋网版权文章,未经受权制止转载。概况见。