
最近,有几则音讯吸引了老孙的留意力,一则音讯是在海内,亚马逊AWS最近上线了一款名为DDESE的FPGA语音辨认减速方案,听说这个语音辨认减速处理方案是首个在AWS上发布的,由中国人工智能 创业 公司提供的方案。另一则音讯是,国际的华为云也将DDESE处理方案移植到了华为云平台之上。此外,听说阿里云也正在将DDESE迁移至其上。那么,这个DDESE究竟是何方神圣,居然可以让诸多云厂商“竞折腰”?
DDESE,语音辨认的“减速器”
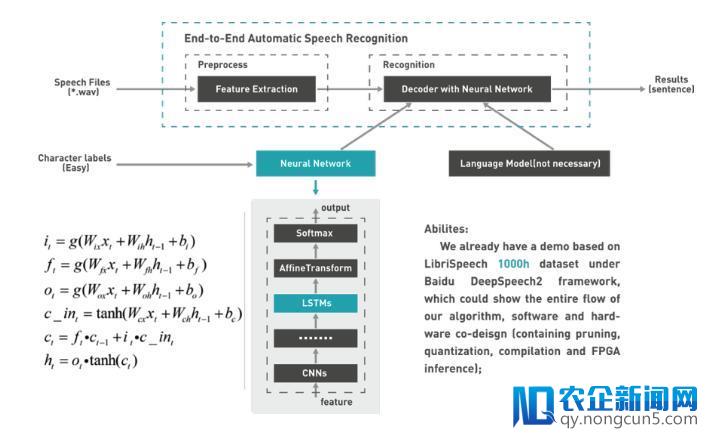
DDESE是深鉴 科技 笛卡尔高效语音辨认引擎(DeePhi Descartes Efficient Speech Recognition Engine)的简称,它是深鉴科技基于Xilinx FPGA自主研发的高效的端到端自动语音辨认引擎,它针对深度神经网络(次要是LSTM),为用户提供软硬件协同设计的疾速、灵敏、高效的推理计算减速处理方案(包括剪枝、定点、编译和FPGA执行推理)。它借助了DeepSpeech2框架和LibriSpeech 1000小时数据集来做模型训练和紧缩,支持用户测试比照CPU/FPGA的功能以及体验单句语音辨认效果。
DDESE的中心技术——ESE语音辨认引擎——基于2017年取得FPGA芯片范畴顶级会议 FPGA 2017最佳论文的研讨效果,与FPGA 2017的ESE一脉相承,是深鉴科技以端到端语音辨认为载体,在产品化路途上迈出的第一步。
DDESE具有以下特点:
·针对模型推理支持对单向、双向LSTM运用FPGA做减速
·支持卷积层、全衔接层、BN层和多种激活函数(例如Sigmoid、Tanh和HardTanh)
·支持测试比照CPU/FPGA的功能以及体验单句语音辨认效果
·支持用户本人上传测试语句停止辨认(要求16000Hz采样率,时长不超越3秒的英文)
DDESE处理方案是算法、软件和硬件协同设计(包括剪枝、定点、编译和FPGA执行推理)。经过剪枝,可以在精度损失很小的状况下失掉一个稀疏模型(稀疏度为15%~20%),然后将模型的权重和激活值定点到16bit,这样一来整个模型可以被紧缩超越10倍,可以借助稀疏存储格式编译并部署在笛卡尔平台上,采用FPGA执行高效的推理。
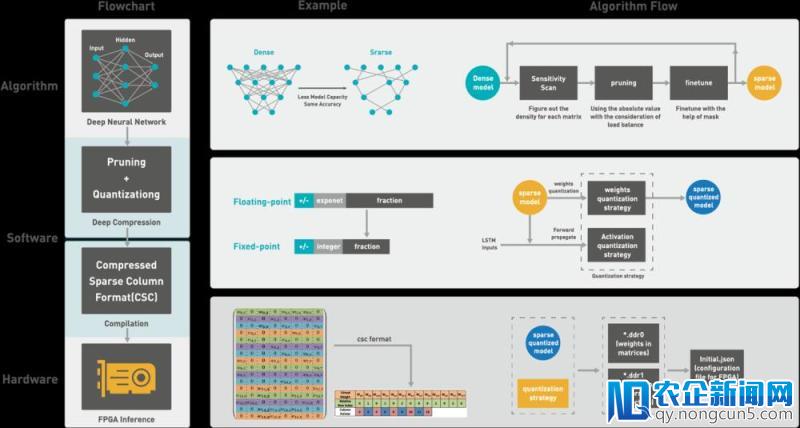
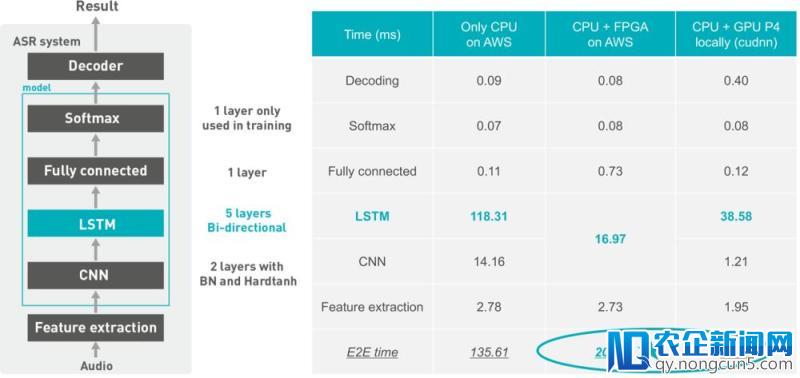
DDESE的自动语音辨认零碎和模型的构造如下:
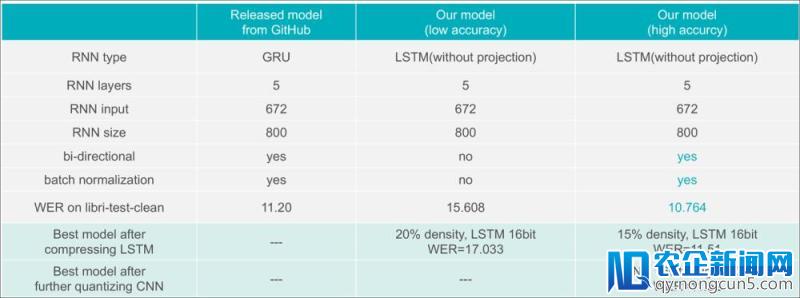
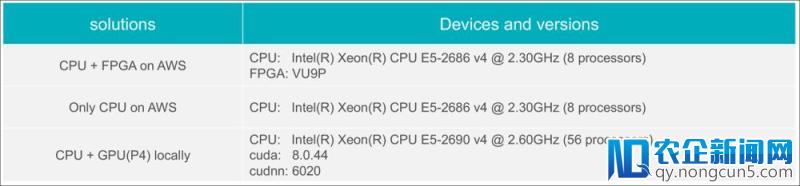
假如只减速模型的LSTM层,关于单向、双向LSTM模型相比于GPU(Tesla P4 + cudnn)辨别可以获得2.87倍和2.56倍的减速;
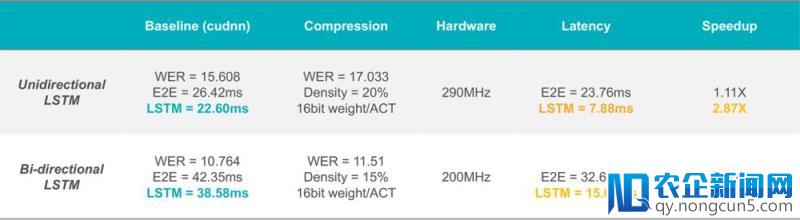
假如同时减速模型的CNN层和双向LSTM层以期更低的延迟,关于整个端到端的语音辨认进程相比于GPU(Tesla P4 + cudnn)可以获得2.06倍的减速。

备注:E2E是端到端的简称,ACT是激活值的简称,WER是词错误率的简称,输出语音为1秒。
关于CNN+双向LSTM模型,详细的功能比照如下:
DDESE,功能弱小的端到端处理方案
经过下面的引见,可以看到,DDESE的确具有极端强悍的功能,尤其关于LTSM神经网络减速效果奇佳。那么,DDESE为什么会这么强呢?
大家都晓得,目前,简直一切语音辨认技术都依赖于机器学习,从而到达更好的语音辨认效果,而任何机器学习减速处理方案功能的提升无外乎三个方面:算法、软件、硬件。
而在后面的局部老孙曾经提到DDESE在算法和软件方面的优势,但是,仅仅只具有高效的算法和优质的软件,还并缺乏以保证DDESE在功能上的超群实力,必需同时有弱小的硬件架构与之相反相成,才干起到洗心革面的效果。
这个弱小的硬件架构就是——FPGA
FPGA想必大家都不生疏,即现场可编程门阵列。但FPGA的声名鹊起其实就是源于它在机器学习方面的杰出功能。FPGA之所以可以在机器学习,特别是深度学习中表现出较高的功能实践上是和它的特性严密相关的。
深鉴科技RNN/LSTM减速技术团队担任人李鑫引见说,FPGA不同于CPU、GPU采用的指令译码执行、共享内存的冯·诺依曼构造。它实质上是无指令、无需共享内存的体系构造。FPGA同时拥有流水线并行和数据并行,而GPU简直只要数据并行(流水线深度受限)。例如处置一个数据包有10个步骤,FPGA可以搭建一个 10级流水线,流水线的不同级在处置不同的数据包,每个数据包流经10级之后处置完成。每处置完成一个数据包,就能马上输入。而GPU的数据并行办法是做10个计算单元,每个计算单元也在处置不同的数据包,但是一切的计算单元必需依照一致的步伐,做相反的事情(SIMD,Single Instruction Multiple Data)。这就要求10个数据包必需一同输出、一同输入,输出输入的延迟添加了。当义务是逐一而非成批抵达的时分,流水线并行比数据并行可完成更低的延迟。因而对流式计算的义务,FPGA比GPU天生有延迟方面的优势。因而,FPGA更合适做需求低延迟的流式处置,GPU更合适做大批量同构数据的处置。
而从深度学习来看,实践上分为训练和推断两个局部。其中,训练市场占整个深度学习市场的5%,其他95%都是推断市场。关于很多推断场景(例如语音辨认)来说,它实践上是一种流式计算密集型义务,特别合适FPGA,再加上FPGA在能耗方面的宏大优势以及可编程的灵敏性,FPGA成为深度学习首选的硬件架构平台,也就不难了解了。
而深鉴科技从树立之初,就瞄准了FPGA市场。在FPGA范畴具有抢先的技术实力,这种实力表现在DDESE上,就是卓然超群了。
DDESE上云的理由
其实,自2015年英特尔有史以来最大一笔收买案——167亿美元收买FPGA第二大企业Altera以来,FPGA就遭到了众多云计算巨头的关注,随同着人工智能技术的疾速开展,人工智能市场的火速升温,FPGA在深度学习范畴展示的弱小潜力恰恰顺应了人工智能市场的开展潮流,因而,推出FPGA云效劳曾经成为众多云计算厂商在人工智能市场占据先机的关键,于是,众多云计算巨头纷繁推出本人的FPGA云,国外云计算巨头AWS在去年推出了FPGA云效劳,而另一个云计算巨头微软在Azure中曾经少量运用FPGA。国际云计算厂商阿里云、腾讯云、百度云也曾经相继推出了FPGA云效劳。
李鑫以为,各大云计算厂商纷繁推出FPGA云,从云计算厂商方面来讲,各大云计算厂商拥有云端的优势,任何一项技术经过云,将会更好的发扬它的优势,云的便捷性、可扩展性,开发本钱低、弹性灵敏的特点是很多其他平台所无法提供的,对FPGA也异样如此,FPGA云更能充沛发扬FPAG的优势,减小FPGA的优势,从而为云计算厂商博得更多的用户。而从用户角度来说,用户不需求关怀云面前的详细硬件,只需求依据本人的实践需求——例如究竟是想要低功耗,还是地道 经济 ,是需求大规模数据非流式处置的才能,还是需求通讯密集型的流式处置才能——在云市场中找到对应的处理方案,直接拿来运用就好了,尤其关于FPGA来说,假如用户独自置办FPGA,本钱昂贵不说,部署和维护对用户来说都是一项繁重的担负,而经过FPGA云,一切成绩将迎刃而解。
因而,FPGA云关于云计算厂商和用户来讲都是一个双赢的场面,各大云计算厂商喜爱FPGA云也就不难了解了。而构建于FPGA之上的DDESE,聚焦于人工智能最炽热的语音辨认减速范畴,集算法、软件、硬件零碎设计于一身,使用了深鉴科技诸如深度紧缩等多项自主创新技术,并采用了著名的DeepSpeech2框架以及LibriSpeech数据集,同时,它也是一个完好的端到端的语音辨认减速处理方案,并且简直是世界上独一可以达成RNN/LSTM稀疏化硬件完成的语音辨认减速处理方案,这样的方案遭到各云计算厂商的欢送自然是瓜熟蒂落,而单方的协作也自然是一拍即合。
为用户提供低门槛FPGA处理方案
李鑫最初表示,实践上,DDESE只是一个窗口,它向大家展现了深鉴科技所具有的弱小的集算法软件、硬件协同设计为一体的处理方案设计才能,同时经过和各大云计算厂商的协作,也为用户在语音辨认、深度学习范畴停止研讨、学习和创新提供了一个复杂、廉价、方便的平台,让大家可以更便捷、高效、疾速地享用到FPGA硬件处理方案给他们带来的减速才能,促进相关技术的疾速开展和迭代。深鉴科技也希望可以经过相似的处理方案,进一步降低用户运用FPGA的门槛,深鉴科技也会应用本身的软件研发才能,为用户提供愈加优不知道从何时开始,个人信用渗透到生活的方方面面。图书、数码产品免押金借用,办理签证无需银行流水证明,甚至租车住酒店都不需要交付押金……秀的软件工具链,协助用户充沛发扬FPGA平台的优势,为用户提供愈加多样化的选择。