
6月21日,一则刑事判决书呈现在群众眼里,其中几位原告人用爬虫抓取效劳器内容,一审讯决以为他们冒犯了《刑法》第 285 条”合法获取计算机信息零碎数据罪”,判处有期徒刑和罚金XXX。( 点这里 )
底下的围观群众炸了:
网友甲:刚学爬虫没多久,是不是要弃坑了?
网友乙:怎样办,跑吗?
网友丙:做爬虫的我瑟瑟发抖.jpg
网友丁:爬虫工程师这个岗位是不是要凉?
不过也有比拟明智的群众,比方说:离任员工应用对零碎的熟习,或许也许是本人留的后门,伪造特定 UA 抓取内容被老东家告了。
还比方:大家不要恐慌,有看到v2有知情人说其实不是爬虫,是在外部效劳器偷数据。
总之爬虫技术这个明星词汇又进入了群众眼中,有缘高端智能装备、新一代信息技术、新能源、新材料、新制造、新零售、新技术、生物制药等新的产业集群正在迸发活力;创新驱动、科技支撑、知识产权转化、技术转移等新的动能正在超越旧的动力,新经济成为支撑经济发展的重要力量。的是,就在不久前由阿里云主办的先知大会上,雷锋网宅客频道也听到一个有关爬虫的议题。
演讲者是阿里云初级平安专家猪猪侠,临时从事自动化平安测试任务,熟习多种开发技术,擅长浸透测试与数据发掘。
猪猪侠引见了如何基于历史经历和已知场景,结构并完成一个静态爬虫。经过阅读器提供的Headless调试形式,来遍历一个网页的一切静态对象,自动填充输出表单的参数值,并触发对象上的绑定的事情,无效处理平安测试进程中的攻击面发掘。
以下为猪猪侠演讲内容,雷锋网 (大众号:雷锋网) 整理。
在讲爬虫技术之前,先考虑一个成绩:我们为什么需求一个扫描器爬虫?
据少量调查剖析显示,国际少数企业做平安测试时还停留在人肉进程中。自动化测试水平绝对较低,且企业在日常平安测试进程中,投入了少量人力本钱在反复性任务上。
人毕竟是血肉之躯,有时分会累,也有时分心情冲动。能够某公司测试人员在心境不好时分做测试,最初的平安测试后果就是看心境,只要攻击面和测试预备充沛的时分才干够失掉保证。同时Web2.0框架很活泼,招致十分多的是生效的,他们的爬虫无法辨认出整个网页的链接构造。
这个时分我们需求一个爬虫协助我们提升整个平安测试的效率。
首先,业界同行和平安工程师是怎样完成爬虫的?先举一个例子,之前微信群有个冤家说,他运用下图这串代码爬取seebug没有爬到后果。这是由于seebug网站应用了代码混杂的技术,并不断频繁更新,最终招致以前纯静态性的爬虫完全生效。
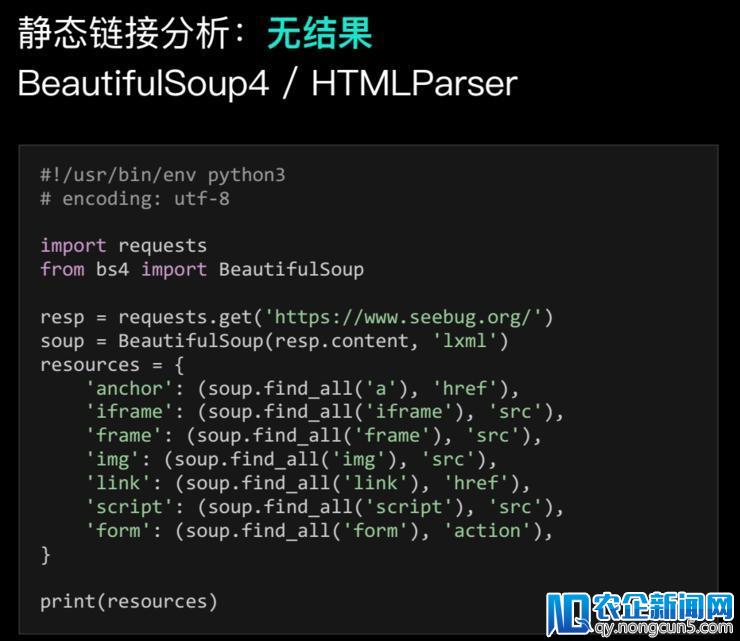
怎样处理静态爬虫的缺陷?
只需求引入一点新的技术,比方说带GS引擎的爬虫就可以处理这个成绩,你用PIP装置一个装置包,运用右边的代码就可以完好的爬到seebug的链接信息了。
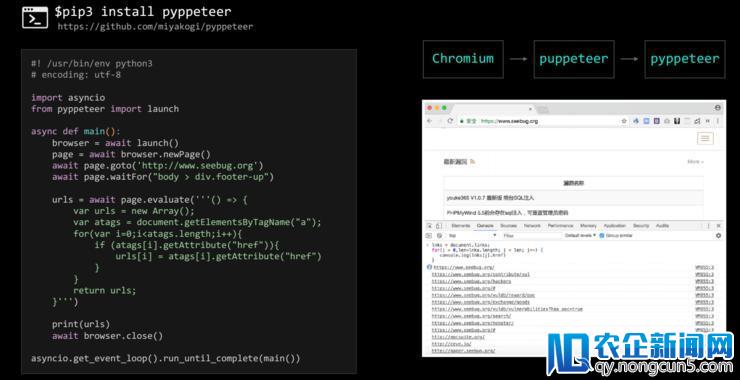
这个项目是承继谷歌的无界面阅读器开发的。无界面建成为healless阅读器,如今有四种,它们缺陷是运用诸多第三方库十分不波动。后来phantomjs呈现,但phantomjs有很多无法修复的成绩,作者之后宣布不再对其停止维护,只能选择谷歌的无界面阅读器。
为什么运用谷歌的phantomjs停止爬虫,次要有三点。第一有谷歌大厂支持,谷歌阅读器世界占有率第一,波动率高,几小时一个版本更新。另外谷歌对W3C规范组织的支持度在全球一切阅读器中是最高的,兼容性也较好。
回到明天的主题,什么是启示式爬虫?
简而言之启示式爬虫是基于一切历史经历及已经看到过的已知场景,经过剖析这些场景和应用已知的经历构建并完成规则的爬虫
。
接上去我们来看看全体的启示式爬虫最佳理论流程。首先可以把爬虫看作一个工厂流水线零碎,流水线零碎一定会有一个总队长担任各条消费线义务调度,在这里ROP就是总队长。流程明白后,每个步骤都各司其职完成各自的功用。
爬虫总队长这个管理器的功用担任义务调度和事情管理。在做扫描器爬虫的第一步先将URL传给义务调度器总队长,总队长把这个义务传给上面,之后翻开页面进入到加载形态。页面加载后需求判别以后页面能否完全,比方有时分某些网页效劳器网络性差,或是遇到GS报错、网站超时某些资源显示不全,这时分可以经过下图标注的三个形态来确定整个网页的构造能否加载完成,整个页面能否翻开完成。

完成后把整个阅读器page页面锁定不做任何举措,让它翻开另外一个新网页,或许跳转其他网页上去。
当整个网页加载好之后,把整个网页跳转锁定后就可以进入到函数劫持阶段。随后开端注入一个监听器,监听一切事情的变化和事情触发的信息。当文件加载、函数劫持、监听都完成之后,可以编译出任何输出框绑定的事情,对某个输出参数值停止惯例判别的一些信息。
当我们发现页面存在表单的时分,可以经过剖析表单的输出类型以及表单称号,停止一些参数填充。下面一切流程完毕后,会失掉以后页面一切信息的后果题。此时可以经过去虫过滤之后,前往给事情管理器,反复执行整个流程。
确定总体流程之后回到方才的第一步,页面加载,录入完成。
当一个页面加载完成之后,应该在什么时分注入我们的劫持代码,这里边有形态可以选择。第一个在page load之后;第二个是等候页面加载完成之后,也就是以后网络形态全部闲暇的时分,整个爬虫执行流再持续执行;或许判别整个网页的DOM树能否被加载并解析完成。
再看恳求衔接局部,下图三个成绩是Web2.0爬虫界和Web1.0都遭到关注的成绩。当你爬取一个网页之后,某些代码就把你的页面跳走了,甚至能够规则还没有加载完成页面就被人转走了。

大家针对这个成绩给出的解法不同,有的人建议本人把原码重新编译。其实除此之外还有一个解法,就是插件机制,可以完成在另外一层对阅读器的控制。如下图,为每个阅读器插件提供一个对象,当整个阅读器发起恳求之前,可以在事情触发一霎时,网页开启前在这里添加一个函数出来。
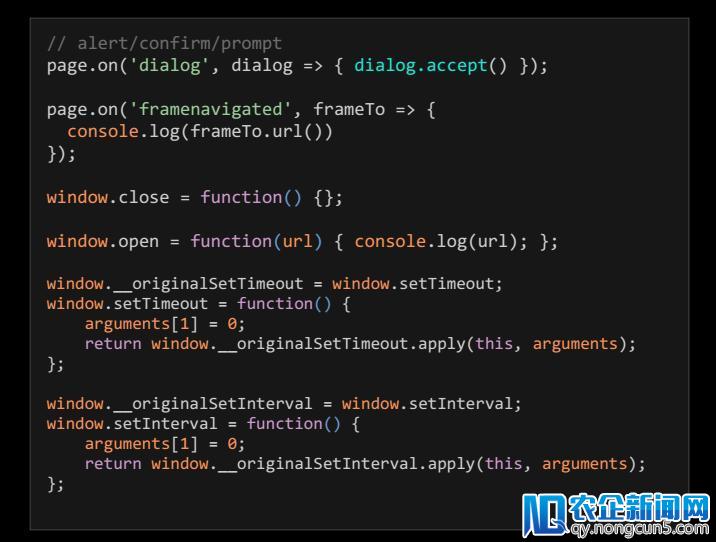
比方当下面的123要发作时,可以经过添加一个监听事情,把以后一切页面Web恳求从逆向到链接上完成网页锁定,当爬取一个页面的时分就再也没有任何函数把页面跳转走,这样可以确定整个页面的完好性。我猜想那些屏蔽视频广告的插件,也是应用了这个函数完成的这一功用。
另一个困扰我们的成绩是各种不时弹出的弹窗,甚至会遇到一些极端的开发,在网页中加一些参数和地址刷新的函数。假如要确保我们发明的爬虫可以流利的爬取整个页面不被阅读器奇奇异怪坑住,需求直接将已知的可以制造网页阻塞的函数停止劫持。
页面加载的时分,可以监听一切弹窗的事情,只需弹出一个窗,之后完毕把这些都改掉。关于超时函数,我们制定一个原生函数,在调用这一函数时分把工夫永世设置成是0,前面执行也是经过此办法,调用对工夫控制的任何函数,都把生命周期设成0,这样就不会由于开发的一些代码招致整个网页被框住。
还有一个爬虫界十分关怀的是如何获取AJAX恳求信息。
有两种办法,一个运用阻拦的功用,相似于主动扫描器的代理,阅读器提供这个API一切的资源,只需网络恳求信息都可以经过这一办法阻拦记载上去。
第二种复杂粗犷的办法是直接可以用本人的函数把原生函数劫持起来,把恳求信息记载上去,这里只需求劫持这些办法可以扫描器爬虫所需求的一切功用。
当函数劫持进程完成后,开端剖析整个网页上面一切节点信息以及表单信息,详细的理论方式有两种。比方可以经过运用循环DOM一切节点信息。另外我们可以运用DOM提供的弱小工具,经过自定义规则过滤文档中节点,来生成新的节点信息。我们可以提早定义好想要捕捉节点信息的相关规则,比方说我们把SRC只需是DOM恣意节点上,跟一切相关的信息监听起来,只需网页上任何一个衔接信息,或许一个图片的我国这片创新热土正在发生一场全面而深刻的产业结构变革。地址发作改动,都可以经过这个办法来捕获到。
当经过DOM获取一切信息之后,并不是一切事情信息都需求触发一遍,我们往往建议针对特定的场景,去婚配执行。比方在阅读一些新闻网站时分,需求经过滚动屏幕刷新刷出更多的新闻,面前用到的技术就是监听翻页的办法完成。比方运用一些模态框的时分,需求在一个网页中点一个按纽,这是已绑定好的事情,点一下会弹出模态框输出信息。比方像社区型知乎和雪球网站,他们为了完成音讯的实时配送,面前有历史义务在运转。
当拿到整个节点信息和绑定信息之后,可以选择触发这些事情信息。触发事情信息有两种,如下图代码,下面有一个事情,事情的称号是click,可以直接经过代码声明一个事情直接触发,这两行代码执行时阅读器会弹出一个click的弹窗。另外一种复杂粗犷的办法是找到事情面前的值,事情绑定面前的值就是一个代码,可以调用eval直接执行。
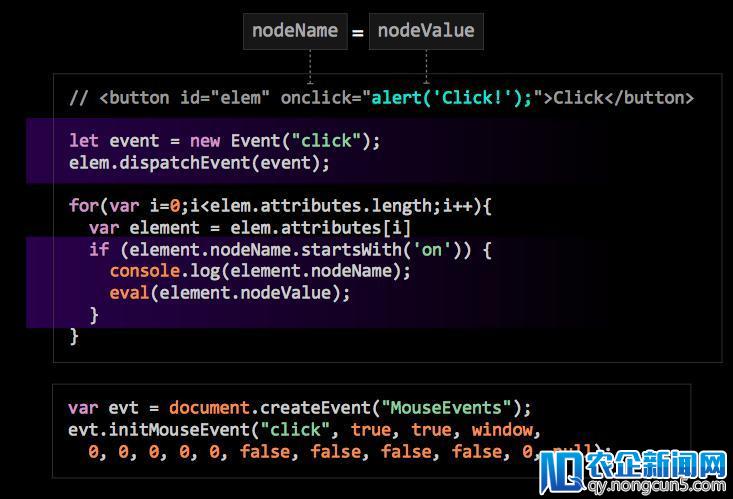
当然我们可以模仿任何事情,我们设计爬虫的目的是为了做平安测试,在平安测试进程中,发现攻击面的多少决议整个平安测试效果。在Web场景中表单非常重要。比方我登录页面,搜索页面在整个开发进程中,触及数据库的添加修正查询都和表单有关。遍历表单的方式也有十分多,但这里还有另一个愈加方便的办法,直接运用原生的对象,经过循环把整个以后表单登录框里边有哪些内容停止查找。
树立完表单之后,参数类型自动获取到表单里边输出框的字符长度,为每个参数生成适宜的值,同时可以调用节点的办法,给表单设计一个值,或许可以经过这个办法协助按纽点上选项。当我们有表单的时分,就可以完成自动填充。比方爬虫发现一个页面是一个登录接口可以经过判别它的输出框的称号,是不是包括这些内容,假如是的话就经过上面定义好的规则,直接从这里边挑一个名,填充过来。当我们发现一个表单里边是跟它相关的,我们就可以经过同我们规则里边拿到英文的名,然后在再等等一个@,然后再把上去DOM的列表随机挑一下失掉一个邮箱就自动填充。

整个流程引见完后来看一个爬虫DEMO,次要爬取一个网页,把网页中一切的信息图片、静态摄入和元素都爬出来。
demo下载地址:https://github.com/ring04h/papers/blob/master/xianzhi_crawler_demo.mov
最初是总结的四个观念。

当我们发现URL中孤立呈现的数字,90%的状况是静态参数。
在爬取到一个页面后果时,发现十分多链接在pass,里边存在长度类似的分歧性,且生成方式是经过其他方式生成的。我们可以判别一下存在多少长度分歧的链接,假如这个数大于5或许10,应该小心这里边是一个静态的参数。
我们处理伪静态成绩上,伪静态百分之七八十状况下经过横杠和反横杠剖析这个。比方第一个衔接就是反斜杠伪静态,上面就是横杠的伪静态。我们将整个局部停止联系,联系出来的值是什么类型,假如是整形就命中了第一个只需孤立数字呈现在某个途径下都能够是静态参数。
另外我们经过HASH化去做去虫,比方有异样的链接他们在123456789,我们只需求把这个衔接每个参数切割成括号停止切割,最初看他们的呈现的频次,假如呈现的次数十分多,代表着这个参数是一个常量,它是固定挟持的。假如面前的参数呈现的次数十分散漫,只要1和2,那个途径前面的参数有能够是静态的参数。
以上内容来自阿里先知大会,雷锋网编辑整理。
。
