
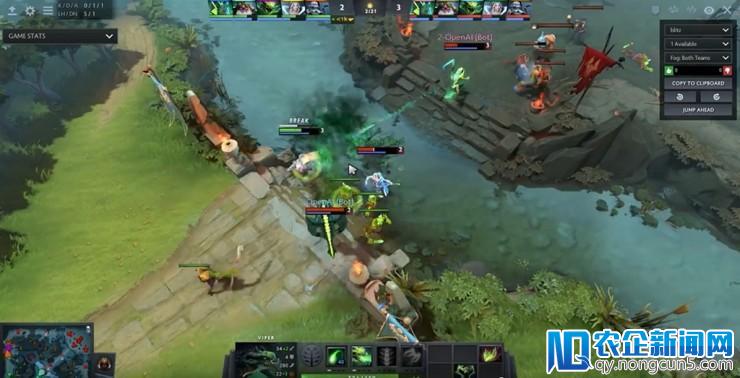
雷锋网 AI 科技评论按:各位读者想必明天一睁眼就被「OpenAI 的人工智能在 DOTA 5v5 竞赛中也打败了人类选手」的新闻刷屏了。 OpenAI 开发的 DOTA AI 去年在 1v1 solo 中打败顶级职业选手 Dendi 和 Sumail 之后,紧接着就放出豪言还要在 5v5 的 DOTA 竞赛中击败人类,这一天似乎这么快就到来了。
5v5 AI,一个新的台阶,不过这个 AI 其实还比拟初级
DOTA(以及 DOTA2)是目前最炽热的电子竞技游戏之一,也是当之无愧的职业竞赛规模最大、奖金最高的游戏。DOTA 游戏有很高的难度,对人类玩家来说都需求很长的学习工夫,由于 DOTA 中有上百种英雄、上百种物品、多种游戏战略、不同英雄有不同的玩法、不同的英雄组合之间也有共同的技艺和配备配合;除此之外玩家还需求审时度势,同一个英雄在不同场面中也有不同的玩法。DOTA 的职业竞赛也因而而变得冲动人心,选手的部分小操作和整个团队改动战局的战略执行都会被玩家们津津有味。
复杂的英雄、物品、配合、长短期战略结合等方面正是我们临时以为 DOTA 这样的游戏对现阶段的 AI 来说过于困难的缘由。而且除了这些人类眼中的认知难题之外,DOTA 游戏的举动空间还十分庞大。相比于围棋中每一步操作只需求在棋盘上剩余的空位中选一个落子,DOTA 中的举动是十分密集的(每分钟操作在 100 次数量级)、思索工夫长短的(比方继续施法技艺)、数值延续的(比方走位)、复杂多值化的(比方购置配备)、信息是局部可察看的(地图上有少量的无视野区域),反应也可以以为是稀疏的(胜负最为重要),所以主流观念一度以为相似 DeepMind 开发 AlphaGo 时那样的地道强化学习自我对弈是无法学会玩 DOTA (以及星际等即时战略游戏)的,过大的行为空间会让训练进程临时停留在没有无效反应的区域从而无法收敛。 层级强化学习 被以为是一种有希望协助训练进程疾速走出低效探究的办法,但开展仍不成熟。
OpenAI 关于 DOTA AI 的最终目的是开收回可以打败人类职业选手的 AI。显然这样的目的是无法一挥而就的,所以他们的指点思想是分步走,从英雄、物品、地图范围、战略都有高度限制的 1v1 竞赛开端,然后逐渐增加限制,同时逐渐改善模型,一步步接近最终目的;去年 TI(国际约请赛)中 1v1 打败 Dendi,以及在测试竞赛中打败 Sumail 的 DOTA AI 就是其中的第一步。关于这样的后果,初看有些不测,但细想之下还是比拟合理的。毕竟玩 Atari 游戏我们都曾经习以为常了。
关于接上去的 5v5 AI(名为 OpenAI Five),自然也保存了诸多限制,游戏环境和各位玩家熟习的样子有诸多不同。OpenAI Five 在这个环境里做了屡次迭代更新,4 月 23 日版本初次打败了 OpenAI 本人编写的基于脚本的基准模型,5 月 15 日的版本与 OpenAI 员工队伍(天梯分段 2500,高于 46% 的玩家)打了一胜一负;而 6 月 6 日的版本则在与专业战队(天梯分段 4200,高于 93% 的玩家)和半职业战队(天梯分段 5500,高于 99% 的玩家)的竞赛中都博得了三局中的前两局。
OpenAI Five 目前设定的游戏中的限制有以下这些方面:
-
竞赛单方都运用固定的瘟疫法师、冥界亚龙、矮人火枪手、水晶室女、巫妖 5 个英雄,而不是在超越 110 个英雄中恣意选择(显然我们也可以揣测出 OpenAI 就是以这组固定的英雄停止训练的)
-
制止运用守卫,制止运用隐身物品(耗费品及配备)
-
制止运用幻象和分身
-
制止打肉山
-
制止购置圣剑、魔瓶、压制之刃、远行鞋、知识之书、眼泪
-
制止运用扫描
-
OpenAI Five 方有五个无敌的信使,不过也制止运用这些信使看视野以及接受损伤
显然各位 DOTA 玩家一看就晓得,仅英雄选择的限制这一项就极大降低了游戏的复杂度;隐身、肉山之类的禁用也减少了战略战术的选择空间;至于 5 个无敌的信使就更像是对 5 个 AI 之间(也许并不理想的)协作才能的妥协了。
不过,能打败专业和半职业战队的表现毕竟还是有一些特征的,能在三局中博得前两局也阐明了 AI 的战略选择与执行的效果。在几场竞赛中 OpenAI Five 的玩法表现出了这些特点:
-
采取的战略总是放空本人的优势路,攻击对方的优势路(以及到中路的这小半场),以求形成压力、构成优势。(所以人类职业选手到了第三局也就可以反制这样的固定战略了)
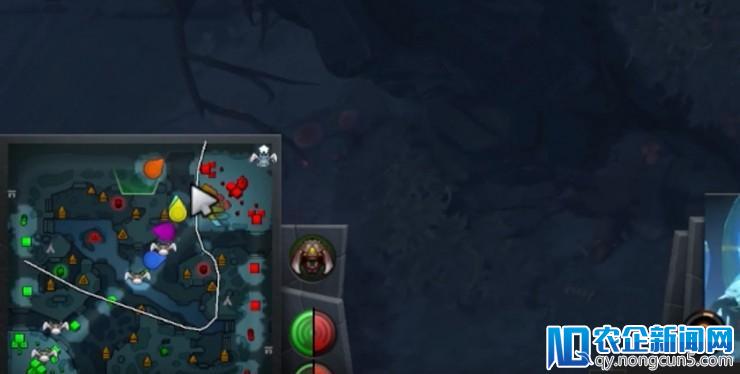
OpenAI Five 五个英雄都集结在对方优势路到中塔之间的区域
-
疾速自动地组织 gank 并推搭
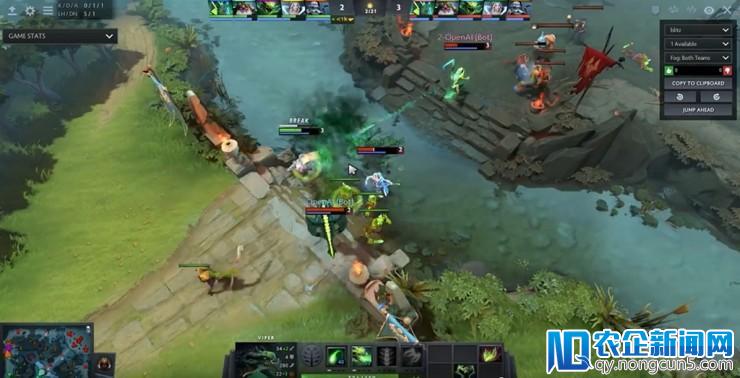
竞赛开端 2 分钟,AI 的 2 级冰女和 2 级毒龙 gank 中路
-
竞赛后期给辅佐英雄让钱让经历,这让辅佐英雄更快地到达最高输入,同时也更快地完毕竞赛

人类方防御洼地,AI 冰女 BKB 跳大,配合队友击杀对方四人
复杂的强化学习义务比料想的要复杂?
即使游戏中有一些限制,但还是有足够的复杂度,而且我们也看到了 AI 在游戏中的精彩表现。从技术角度来说,这也给了我们新的启示。
正如前文提到的,DOTA 中复杂的举动空间以及对长短期战略结合的需求的让范畴内的研讨者,甚至包括 OpenAI 的人本人都以为 DOTA 需求层次化强化学习这样的全新的深度学习技术,但其实只经过雷锋网 (大众号:雷锋网) AI 科技评论也曾引见过的 近端战略优化 PPO 就曾经到达如此的程度 —— 至多是在用足够大的规模做训练,以及选用了适宜的超参数均衡了探究行为的水平的时分。
OpenAI 运用了256 个 V100 GPU 和 128000 个 CPU 训练模型,不运用人类数据,80% 的工夫自我对弈,20% 的工夫和过来的版本对弈。训练中每天停止的游戏数量时长相当于大约 180 年。依据 DOTA 讲解 Blitz 评价,OpenAI Five 的补刀只是普通玩家程度,但整场游戏的临时战略执行曾经有了职业选手水准。用现有的办法就能到达短期战略和临时战略之间的平衡,算是一项惊喜的发现。
另一方面,OpenAI Five 中运用的模型架构也出其不意地复杂。每一个英雄由一个独自的 LSTM 模型控制,而它只是一个单层的、含有 1024 个单元的 LSTM 网络。网络从 Value (DOTA2 制造公司)提供的 BOT API 获取数据,然后经过多个不同的举措输入接口停止控制。
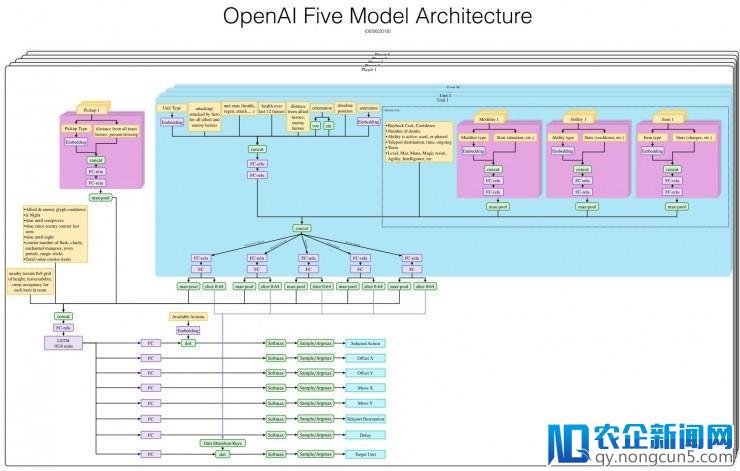
OpenAI Five 的网络架构图
OpenAI 关于反应的设计也心怀叵测。除了胜负之外也选用了人类选手常用的目标:总财富、击杀数、死亡数、助攻数、补刀数等等。但是为了防止 AI 过于关注这些倾向于短期战略的数据,他们的反应设计只鼓舞 AI 在这些方面做到人类玩家的均匀程度。
还有一个项目是 AI 之间的协作。OpenAI 并没无为 AI 之间设计显式的沟通频道,目前他们设计了一个名为「团队肉体」的超参数,这个 0 到 1 之间的值会反响每个英雄关注本人独自的反应和整个团队的反应之间的比例。在训练中 OpenAI 经过退火来优化这个值的详细大小。
总结
虽然我们说到目前的 5v5 OpenAI Five 的实践表现不过如此,但以现有的资源和办法就到达了超出预期的效果,这也值得我们反思以往的强化学习研讨中,办法与完成能否有诸多做的不完善的中央才招致容易遇到训练困难、表现瓶颈、表现不波动性等成绩;另一方面,在现无方法的威力完全失掉发扬的中央,我们也更容易明晰地看到持续提升表现还需求哪些创新。
OpenAI 还会在 7 月 28 日组织顶尖人类职业玩家再与 OpenAI Five 停止竞赛,这之前零碎还会停止调试更新。我们等待 OpenAI Five 近期能有更新、更强的表现,也等待它早日在有限制的完全展示了 DOTA 复杂水平回到当下汹涌澎湃的AI浪潮,正如所有的企业都被互联网化一样,所有的互联网企业都将 AI 化。而这些互联网企业中,也包含CSDN。同时,作为全球最大的中文IT社区,CSDN还有一个历史使命——为广大的互联网公司进行AI赋能。的环境中再展风姿,更与 OpenAI 全体一同等待这些用于 DOTA AI 的技术能为更多真实世界成绩带来协助。
雷锋网 AI 科技评论报道。
。新生的改变世界的企业将会诞生,从而更好的服务整个人类世界,走向更高科技的智能化生活。
