
大众号/将门创投
编译:T.R

出处:http://bair.berkeley.edu/blog/2018/06/28/daml/
模拟才能 是智能重要的组成局部,人和植物经常经过察看其他集体来学习新的技艺。那么我们能不能将这种才能赋予机器人呢?能否可以像下图一样,让机器人经过察看人类的操作来学会操作新的物体呢?

机器人在察看人类行为后学会了将桃子放到了白色的碗里
假如拥有这样的才能,将极大地简化部署机器人完成新义务的进程。我们只需求展现给机器人需求停止的义务,而无须停止遥操作或设计复杂的奖励函数。很多任务探究了机器人可以从自身的专业经历中很好的学习,这样的学习方式称为模拟学习。
但是基于视觉技艺的模拟学习需求少量专业的示范数据。例如应用原始像素输出来接近单一固定物体的义务就需求200次表现良好的示范才干到达。假如只提供一个示范样本,要完成这样的模拟关于机器人来说非常困难。
除此之外,假如机器人需求模拟人类的示范的特定操作技艺还需求面临额定的应战。除了机械臂与人类手臂的结构差别外,在人类示范和机器人示范之间树立起正确的对应关系是一件非常困难的事情。这并不只仅是对运动复杂的跟踪和重映射,其中最次要的局部在于运动对环境中物体的影响,并且我们需求树立一个以这种互相作用为中心的对应关系。
为了使得机器人可以模拟视频中人类的技艺,可以结合一系列先验经历而不是从零开端学习。经过结合先前的经历,机器人可以迅速学会关于新物体的操作而在域的挪动中坚持不变性,就像在察看了人类的示范后机器人可以在不同背景和视角下学会操纵物体。研讨人员的目的是经过从示范数据中学会学习,来完成少样本的模拟和域不变性。这种被称为元学习的技术是赋予机器人经过察看模拟人类的关键。
One-Shot模拟学习
那么如何应用元学习来协助机器人疾速的顺应不同的物体呢?研讨人员们采用结合元学习和模拟学习的方式来完成一次模拟学习。关键的想法在于给机器人提供某一特定义务的当个示范,机器人就能迅速的辨认义务,并在不同的情形下成功处理。新近的一个任务经过从不计其数个示范中学会学习来完成一次学习,并给出了优秀的后果。假如我们希望一个实践的机器人可以模拟人类并操纵各种各样的新物体,就需求开发一个能从视频数据集的示范中学会学习的零碎,而这些数据可以在真实环境中搜集。接上去的局部首先讨论了经过遥操作搜集的单个示范来完成的视觉模拟,随后展现了这种办法是如何拓展到向人类视频中学习的范围中去的。
One-Shot视觉模拟学习
为了让机器人可以从视频中学习,研讨人员将模拟学习与一种高效的元学习算法(未知模型元学习,MAML)结合起来。经过规范的神经网络来作为战略表示,在每个工夫步长将机器人输出的图像o t 和形态信息x t (例如关节的角度和速度)映射到了机器人的举动上a t (比方夹爪的线速度和角速度)。下图展现了算法三个次要的步骤。
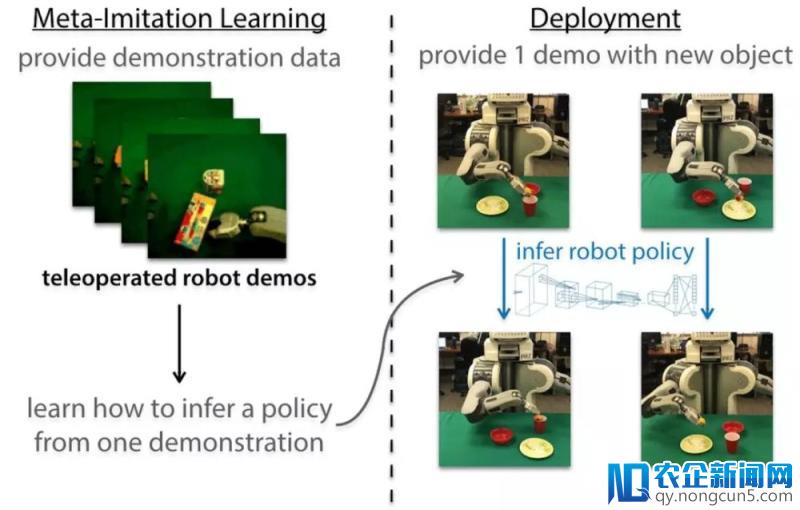
首祖先们关于不同义务(操作不同物体)搜集了少量操作示范构建了大型数据集;随后应用MAML学习了战略参数θ的初始形态。随后提供某一特定物体的示范时,我们可以基于这一示范来运转梯度下降法来寻觅关于这一物体的普通化战略θ’。当运用遥操作示范时,战略可以经过比拟预测举动π θ (o t )和专家行为a * t 来更新战略:
随后经过促使战略π θ’ 的值来婚配同一物体其他示例的行为,完成关于参数θ的更新。在元训练后,我们就可以应用这一义务的单一示范来计算梯度步骤,从而让机器人去操纵完全没有见过的物体了。这一步骤称为元测试。
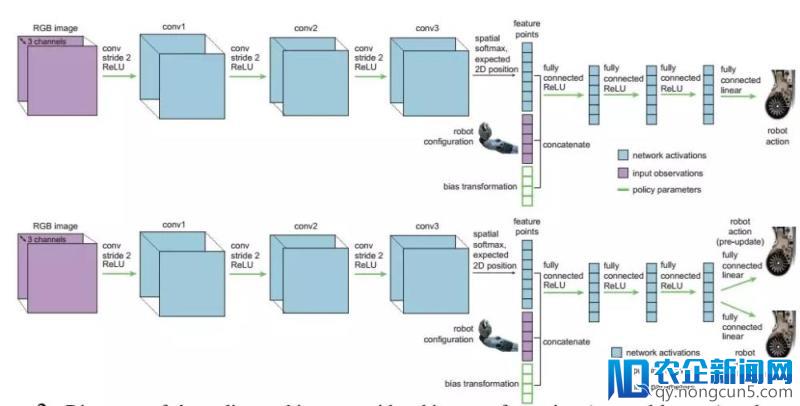
战略架构
由于这一办法没无为元学习和优化引入额定的参数,具有很好的数据效率。因而它可以经过察看遥操作机器人示例完成多样化的控制义务,例如推进和放置等义务。

将物体放到新的容器中去,左图是示范右图是学习后的战略。
经过域顺应性元学习,机器人察看人类完成一次模拟
上述办法仍然是依赖于遥操作机器人的示范而不是人类的示范。为了到达从人类示范学习的目的,研讨人员们在上述算法的根底上设计了一种域顺应的一次模拟办法。搜集了机器人和人执行不同义务的示范,随后经过人类示范来计算战略更新,并用同一义务的机器人示范来评价更新后的战略,算法架构图如下所示:
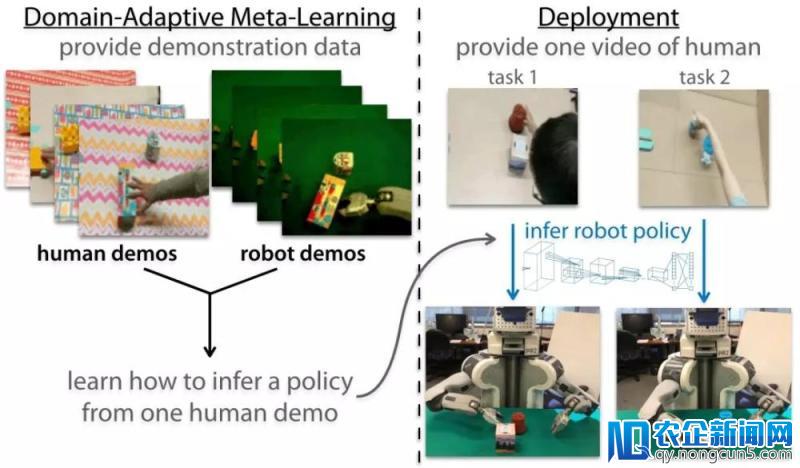
但人类示范只是在执行义务时的视频而已,并不包括对应的行为,无法经过后面的公式计算出损失并更新战略。在这里,研讨人员另辟蹊径的提出了用深度学习的办法学习出一个协助战略更新的损失函数,这个损失函数无需举动作为标志。直接学习损失函数面前的思想来自于,我们可以经过无标签的数据失掉损失函数,同时给出正确的梯度用于战略更新,并最终的到一个成功的战略。
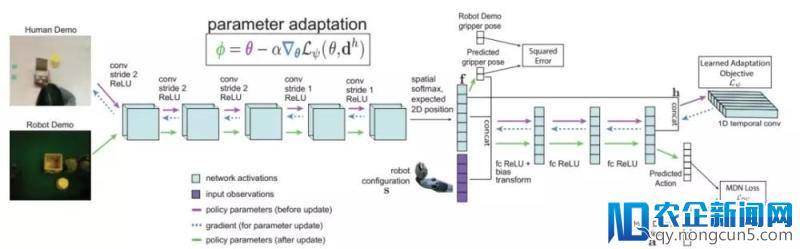
战略架构
这看起来像是不能够完成的义务,但要记住的是元训练进程照旧经过梯度步骤后机器人行为监视着战略的更新。学习损失函数可以被了解为经过抽取场景中适合的视觉线索来更新参数从而修正战略。所以元训练的行为输入将会发生正确的举动。研讨人员应用Temporal卷积来完成了损失函数的学习,可以抽取视频示范中的顺时信息。
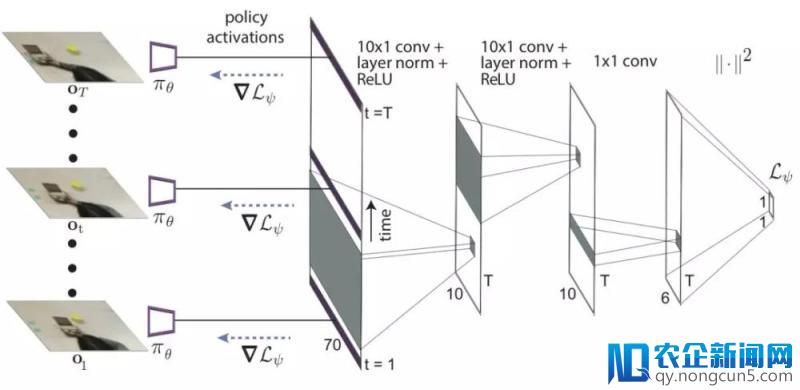
研讨人员将这一办法归为具有域顺应性的元学习算法,这是由于它可以经过其他域的数据完成学习,而不是机器人的战略操纵空间。这一办法使得PR2机器人高效的学会了如何推进很多不同的物体到目的地位,而这些物体在元训练的进程中是历来没有看到过的。

同时也能经过察看人类关于每个物体的操纵,完成物体的抓取并将其放置到新的目的容器中去:

同时应用不同背景环境和相机拍摄的人类示范来验证算法的无效性, 发现即便相机很多朋友说,共享纸巾机是一个广告机,但我们不是这样定义它,我们定义它是一个互联网跟物联网结合的终端机,从线下吸入流量,重新回到线上,以共享纸巾项目作为流量入口,打造全国物联网社交共享大平台。和背景的变化,算法照旧可以坚持良好的表现。

将来任务
目前曾经完成了教会机器人经过观看单个视频就能学习操纵新物体,下一步自然是扩展这种办法的规模,不同的义务对应着完全不同的运动和目的,例如运用不同的工具来停止不同的运动。经过思索潜在义务散布的多样性,研讨人员希望这样的模型可以适用于更普遍的义务,协助机器人在新环境中迅速的树立起战略。同时这里提到的技术并不只仅限于机器人操纵或控制,模拟学习和元学习可以用于言语和其他序列化决策进程中。经过多数的示例学会模拟是一个将来一个非常风趣的研讨方向。
假如想看论文请参考:
- One-Shot Visual Imitation Learning via meta-Learning
https://arxiv.org/abs/1709.04905
对应代码:https://github.com/tianheyu927/mil
- One-Shot Imitation from Observing Humans via Domain-Adaptive meta-Learning
https://arxiv.org/abs/1802.01557