
雷锋网按:本文为雷锋字幕组编译的技术博客,原标题 Improving the Performance of a Neural Network,作者为 Rohith Gandhi。
翻译 | 张平 赵若伽 衣星宇 整理 | 凡江

神经网络是机器学习算法,提供许多示例的精确度状态。但是,很多时候,我们构建的网络的准确性可能不令人满意,或者可能无法引领我们进入数据科学竞争排行榜的顶端。因此,我们一直在寻找更好的方法来改善模型的性能。有很多技术可以帮助我们实现这一目标。遵循这些技术来了解它们,并建立自己的准确的神经网络。
检查过拟合

确保神经网络在测试数据上表现良好的第一步是验证神经网络没有过拟合。好的,停一下,什么是过拟合?过拟合发生在模型开始记忆训练数据的值而不是从中学习。因此,当模型遇到一个它以前从未见过的数据时,就无法很好地执行。为了让你更好地理解,让我们来看一个类比:我们都会有一个善于背诵的同学,并且假设即将有一场数学考试。你和你这位善于记忆的朋友从课本开始学习。你的朋友会记住教科书中的每一个公式、问题和答案,但另一方面,你比他更聪明,所以你决定基于直觉来解决问题,并了解这些公式是如何发挥作用的。考试的日子到了。如果试卷中的问题直接出自教科书,那么你可以料到你的记忆力强的朋友做得更好,但如果问题是涉及直觉方面的新问题,那么你在考试中做得更好,你的记忆力强的朋友会惨遭失败。
如何识别模型是否过拟合?你可以交叉检查训练的准确性和测试的准确性。如果训练的准确性远远高于测试的准确性,那么你可以假设模型已经过拟合。 你还可以绘制图表上的预测点来验证。有一些技巧可以避免过拟合:
-
数据正则化(L1 或者 L2)
-
Dropouts - 随机丢弃神经元之间的连接,迫使网络找到新的路径并归纳
-
提早停止 - 减少神经网络的训练,从而减少测试集中的错误。
超参数调整
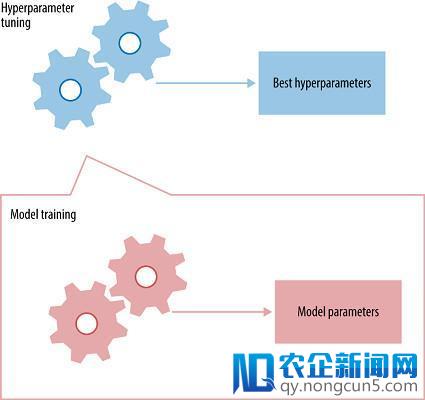
超参数是必须初始化到网络的值,这些值在训练时无法通过网络获知。比如,在卷积神经网络中,一些超参数是核的大小、神经网络中的层数、激活函数、损失函数、使用的优化器(梯度下降,RMSprop)、批量大小、训练的时代数量等。
每个神经网络都会有它的最优超参数集,这个参数集将会产生最大的精确度。 你也许会问,「有这么多的超参数,对于一个神经网络我如何选择使用哪些呢?」不幸的是,现在还没有一个明确的方法去为每个神经网络指定一个最优超参数集,所以这个最优参数集通常通过试错(trial and error)来获得。接下来我们会提到关于超参数的一些通用惯例:
-
学习率(Learning Rate)——选择一个最优的学习率是很重要的,因为它决定了你的网络是否收敛于全局最小值。选择一个高的学习率几乎不会得到全局最小值,因为你有很大概率直接越过最小值。因此,一直在全局最小值附近徘徊但从来没有收敛于这一点。选择一个小的学习率可以帮助一个神经网络收敛到全局最小值,但是这会耗费大量的时间。因此,必须用大量的时间来训练网络。一个小的学习率也会使网络陷入局部最优解。也就是说,由于学习率小,网络会收敛于局部最小值且无法跳出。因此,当设置学习率时,需要谨慎。
-
网络架构(Network Architecture)——现在并没有一种标准的架构会在所有测试案例中都得出高的精确度。你需要去实验,尝试不同架构,从结果中得到推论然后再尝试。我建议的一种方法是:使用一些经过证明的架构去替代你自己创造的。例如:对于图像识别任务,你有 VGG 网络,Resnet(残差网络),谷歌(Google)的 Inception 网络等。这些都是开源的且已经被证明有高的精确度,因此,你可以使用他们的架构再根据你的目的来微调他们。
-
优化方式及损失函数(Optimizers and Loss function )——对于优化方式及损失函数,我们已经有大量的可供选择的选项。事实上,如果需要的话,你甚至可以自定义损失函数。但是最常用的优化方法是 RMSprop 算法,随机梯度下降(Stochastic Gradient Descent)算法及 Adam 算法。这些优化方法可以应用于大多数的情况。对于通用的损失函数,如果应用于分类任务,可以使用分类交叉熵(categorical cross entropy)。如果是在回归任务中,常用的损失函数是均方误差(MSE)。多去调试这些优化方法的超参数,同时也要尝试不同的优化方式和损失函数的组合。
-
批量规模(Batch Size)和训练完整数据的次数(Number of Epochs)——再强调一下,批量大小和训练次数没有对所有情况都有效的通用的值。你需要去实验然后尝试不同的数值。在通常情况下,批量规模的值被设置为 8,16,32。训练完整数据的次数由开发者的偏好和其拥有的计算力来决定。

ReLU 激活函数
-
激活函数(Activation Function )——通过激活函数可以在输出中加入非线性映射。激活函数非常重要,选择一个恰当的激活函数可以帮助你的模型学习的更好。现在,ReLU 是最广泛使用的激活函数因为它解决了梯度消失的问题。早年间,Sigmoid 和 Tanh 函数是最常用的激活函数。但是,他们都存在着梯度消失的问题。也就是说,在反向传播的过程中,当传播到起始层时,梯度会在数值上消失。这会阻止神经网络扩大到有更大规模更多层的状态。ReLU 有效的克服了这个问题因此使神经网络可以有更大的规模。
算法集成

如果单一神经网络的精度不是你所想要的那样,你还可以构建一个神经网络的集成并使它们的预测性能结合起来。你可以选取不同的神经网络架构,用数据的不同部分来训练它们,之后将它们「组装」起来,用其联合的预测性能在测试集上取得高精度。假设,你正在构建一个猫狗分类器,0 代表猫 1 代表狗。当将不同的猫狗分类器结合起来时,集成算法的精度将会根据它与各个单一分类器的皮尔森相关性(Pearson Correlation)提升。让我们来看一个例子,测试 3 个模型并评估它们的精度。

这三个模型之间的皮尔森相关性较高。因此,集成它们没有提升精度。如果我们通过多数投票来集成上述三个模型,我们会得到下面的结果。
现在,让我们看另外三个模型,它们预测结果之间的皮尔森相关性很低。

当我们将这三个「中等生」结合起来,得到如下结果。
你可以从上看到,同样是三个「中等生」的集成,皮尔森相关性低的一方性能要胜过高的一方。
数据的缺乏

在运用了上述所有的技术之后,如果你的模型在你的测试集上依旧没有表现得更好,那可能得归因于缺少训练数据了。当可利用的训练数据的数量受限时,也有很多的使用案例。如果你无法采集更多的数据,那么你可能得求助于数据增强(data augmentation)技术了。

数据增强技术
如果你正在研究图片的数据集,你可以通过图片剪切,翻转,随机裁剪等等,来为训练集增添新的图片。这可以为神经网络的训练提供不同的实例。
结论
这些技术被看作是最好的实践经验,并且往往在提升模型学习特征的性能上看起来十分有效。这篇文章可能看起来比较长,感谢你将它通篇读完,如果任何这些技术有帮助到你,我很乐意与你分享。
博客原址: https://towardsdatascience.com/how-to-increase-the-accuracy-of-a-neural-network-9f5d1c6f407d
添加雷锋字幕组微信号(leiphonefansub)为好友
备注「我要加入」,To be an AI Volunteer ! 雷锋网(公众号:雷锋网)雷锋网
雷锋网雷锋网 (公众号:雷锋网)
。