
雷锋网
(公众号:雷锋网)
AI 科技评论按:本文由美国莱斯大学博士后牛力为 AI 科技评论提供的独家稿件,未经许可不得转载。
传统的机器学习尤其是深度学习,需要大量的标注数据,但是标注数据的获取非常费时费力。考虑到每天都有大量的图片和视频被上传到网上可供免费下载,为了有效地避免由于标注数据不足带来的对传统机器学习模型的不利影响,我们利用互联网上已有的、大量标注得比较粗糙的网络图片或视频来训练模型,用于物体识别、人体动作识别、视频事件检测等应用。
然而,用网络图片或视频来训练模型存在诸多问题,比如:
1.网络图片或视频标签是由用户提供的,非常不准确。有噪声的训练集对模型训练有非常负面的影响;
2. 网络图片视频和测试集的图片视频在数据分布上存在巨大差异,如果用网络数据训练模型,得到的模型在数据分布差别很大的测试集上,效果会很不理想。
但是,基于网络数据学习也有一些优势,比如:
1.网络图片和视频通常会配有标签、标题等文字信息,但测试图片和视频没有这种文字信息。这种只有训练数据有但测试数据没有的信息称为特权信息 (privileged information),我们可以利用特权信息来帮助训练图片或视频的分类模型;
2. 网络上有可以免费获得的语义信息,比如我们可以从维基百科上获取每一个类别的语义信息,用来辅助训练更鲁棒的图片或视频的分类模型;
3. 网络数据具有多源性。不论是图片还是视频,我们都可以从很多不同的网站下载大量免费的数据,比如从 Google、Bing 上获取图片,从 YouTube、Flickr 中获取视频。然而,每一个数据源的数据分布都会有很大的差异,因此如何利用多源网络数据进行学习也是很重要的研究课题。
为了充分利用网络数据的优势,解决基于网络数据学习中存在的关键问题,我们提出了一系列 基于网络数据的学习方法,使得网络图片和视频能被用于训练更鲁棒的模型,在物体识别、人体动作识别、视频事件识别等应用上取得了很好的效果。 接下来就分别介绍如何利用上述网络数据的三个优势(特权信息、语义信息和多源信息)来解决基于网络数据学习的两大主要问题(标签噪音和数据分布差异)。
一、 利用特权信息辅助基于网络数据的学习
为了解决网络数据的标签噪音问题,我们参照多示例学习 (multi-instance learning) 把网络图片分成若干个包。对于二分类问题,我们用类名作为关键词可以搜索得到很多相关样本,然后用其他关键词搜索得到很多无关样本。我们把相关样本分成正包,无关样本分成负包。我们只知道每个包的标签,但不知道每个包里面样本的真实标签。因而,我们对样本的标签做了如下假设:每个负包里面的样本都是负样本,但对于每个正包,至少有一定比例的样本是正样本而其他是负样本。其中提到的比例属于先验信息,可以根据实验观察人为设定。根据以上假设,我们就可以提出多实例学习的模型来解决标签噪音的问题。
另外,我们同时使用特权信息来进一步减弱标签噪音的影响。受 SVM+的启发,我们用基于特权信息的损失函数 (loss function) 来代替多实例学习模型中的损失变量,从而用特权信息控制损失的大小。一般来说,在特权信息的约束下,噪音样本的损失函数值较大,也就说我们允许它们的损失比较大;而非噪音样本的损失函数值比较小,也就是说我们强制要求它们的损失比较小。综上,我们将特权信息用于多种多示例学习方法,提出一种新的学习框架,如下图所示。

在上述框架的基础上,我们进一步解决网络训练数据和用户测试数据的分布性差异问题。我们给不同的训练样本分配不同的权重。具体来说,离测试数据中心比较近的被分配较高的权重,而离测试数据中心较远的被分配较低的权重,从而拉近加权的训练数据中心和测试数据中心的距离。经过公式推导,我们有一个有意思的发现: 对于每一个训练样本,它和训练数据中心的相似度减去它和测试数据中心的相似度可以被看成另外一种特权信息。至此,我们将学习框架拓展为可以同时解决基于网络数据学习的两大问题。 在实验部分,我们用 Flickr 图片或视频作为训练集,在图片分类、人体动作识别和视频事件检测的标准测试集上做了大量的实验,结果证明了特权信息的有效性。我们的论文发表在 ECCV 2014 [1],后来被拓展到 IJCV [2]。
二、利用语义信息辅助基于网络数据的学习
在网上我们可以免费获得每一种类别的语义信息 (semantic information)。比如给定一个类名,我们可以从它的维基主页上抽取文本信息作为该类别的语义信息,也可以用类名的词向量 (word vector) 作为该类别的语义信息。我们的方法建立在差分自编码器 (variational auto-encoder (VAE)) 的基础上,出于以下两点考虑: 1. 自编码器可以用来检测噪音;2. 自编码器的隐藏层 (hidden layer) 可以加入语义信息。
我们方法的框架见下图,分成上下两个子网络。下面的子网络是 VAE,输入是图片的 CNN 特征,输出是重建概率,可以用来指示该图片是不是噪音。具体来讲,噪音的重建概率比较低而非噪音的重建概率比较高。上面的子网络是分类器,输入是类别的语义信息和 VAE 的隐藏变量,输出是类别种类,这也相当于用分类器来约束 VAE 的隐藏层。在这种情况下,分类器和 VAE 可以联合利用语义信息来抵制噪音。
从我们最终的目标函数可以看出,我们旨在减少加权的分类损失。具体来说,更可能是非噪音的图片的损失被分配更高的权重,因为非噪音的图片对训练鲁棒的模型贡献更大。
在训练阶段,我们训练一个端到端的网络以优化 CNN、VAE 和分类器的参数。在测试阶段,我们输入测试图片和所有测试类别的语义信息,预测测试图片的类别。
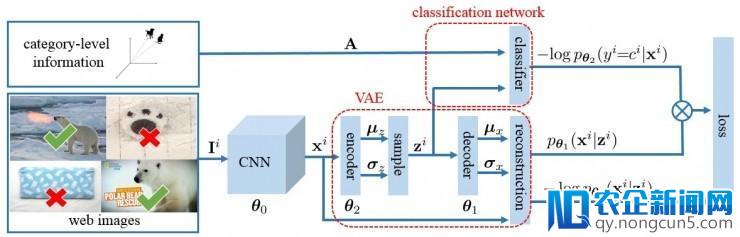
在上述网络结构的基础上,我们做了两点改进用来解决网络训练数据和用户测试数据的分布性差异问题:
首先,我们用 VAE 同时重建网络训练数据和无标签的测试数据,该方法已被之前域迁移 (domain adaptation) 的论文证明有效。
其次,我们用网络训练数据的隐藏变量 (hidden variable) 来重建测试数据的隐藏变量。
具体来说,我们假设测试数据的隐藏变量可以由网络训练数据的隐藏变量线性表示,并且表示矩阵是低秩的。借助低秩表示 (low-rank representation) 的学习方法,我们可以更新测试数据的隐藏变量并用更新后的数据重新预测。在实验部分,我们用 Google 图片作为训练集,在三个图片分类的标准测试集上做测试。结果表明类别的语义信息可以辅助解决基于网络数据学习的两大问题。我们的论文发表在 CVPR 2018 [3]。
三、 利用多源信息辅助基于网络数据的学习
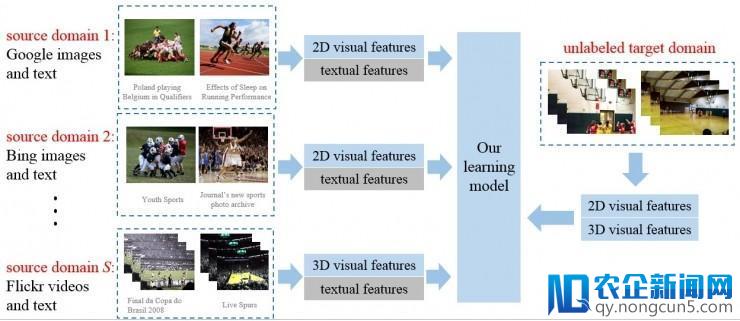
网络上的数据多模态且多源。比如图片可以从 Google, Flickr, Bing 等网站下载,视频可以从 Flickr, YouTube 等网站下载,并且从网上下载的图片或视频都带有文本信息。从不同网站下载的数据有很大的分布差异性。如果用网络数据作为训练集,我们希望选取和测试集分布比较接近的网络源作为训练集,这样训练出来的模型在测试集上能取得更好的效果。所以我们想要在不同的网络源上分配不同的权重,具体来讲,给和测试集分布比较接近的网络源分配更高的权重。
我们的流程图如下,给定若干个网络源,其中一部分是图片源,另一部分是视频源。我们从图片中抽取 2D 视觉特征,从视频中抽取 3D 视觉特征,从文本信息中抽取文本特征,输入到我们的学习模型。同时,我们的方法也需要输入无标签的测试视频,从测试视频中同时抽取 2D 视觉特征和 3D 视觉特征。基于视觉特征,我们在每个源上训练一个分类器。给定一个测试样本,每个分类器会产生一个预测值。我们把所有的预测值加权平均,和测试样本的标签作比较。然而,测试样本的标签在训练阶段是未知的,所以我们还需要推断测试样本的伪标签。 综上,在训练阶段,我们需要同时学习每个源的权重,每个源上的分类器以及测试样本的伪标签。这样就可以解决网络训练数据和用户测试数据分布的差异性问题。
在流程图中,我们还可以看到所有的图片和视频都有附带的文本信息。我们利用附带的文本信息作为特权信息来帮助解决网络数据标签噪音的问题。如何利用特权信息去噪已经在第一部分讲过,技术细节比较相似,在此就不重复了。在实验部分,我们把 Google 和 Bing 作为图片源,把 Flickr 作为视频源,在人体动作识别和视频事件检测的标准测试集上做了大量的实验。实验证明我们的方法可以更好地利用多模态多源的网络数据。我们的论文发表在 CVPR 2013 [4],然后拓展到 T-NNLS [5].
总结
基于网络数据学习存在两大主要问题:标签噪音和数据分布差异性,所以和基于精确标注数据的学习相比在性能上仍有一定的差距。但是考虑到网络数据的诸多优势,基于网络数据学习有着很大的提升空间和广阔的应用前景。 在这篇文章中,我们结合过去尝试的方法,讲述了如何利用特权信息、语义信息和多源信息帮助解决基于网络数据学习的主要问题。在未来工作中,我们会继续探索如何充分利用网络数据的优势去提升基于网络数据学习的性能,并把应用扩展到物体检测,语义分割、文本和图片的双向检索以及其他领域。
[1] Li Niu *, Wen Li *, and Dong Xu, 「Exploiting Privileged Information from Web Data for Image Categorization」, ECCV, 2014.
[2] Li Niu, Wen Li, and Dong Xu, 「Exploiting Privileged Information from Web Data for Action and Event Recognition」, IJCV, 2016.
[3] Li Niu, Qingtao Tang, Ashok Veeraraghavan, and Ashu Sabharwal,「Learning from Noisy Web Data with Category-level Supervision」, CVPR, 2018.
[4] Lin Chen, Lixin Duan, and Dong Xu,「Event recognition in videos by learning from heterogeneous Web sources」, CVPR, 2013.
[5] Li Niu, Xinxing Xu, Lin Chen, Lixin Duan, and Dong Xu, 「Action and Event Recognition in Videos by Learning from Heterogeneous Web Sources」, T-NNLS, 2017.
。