
作者/ Jason Brownlee
译校/ 崔跃辉、叶倚青
整理/ 雷锋字幕组
雷锋网
(大众号:雷锋网)
:用于循环神经网络的编码-解码架构,在规范机器翻译基准上获得了最新的效果,并被用于工业翻译效劳的中心。
该模型很复杂,但是思索到训练所需的少量数据,以及调整模型中有数的设计方案,想要取得最佳的功能是十分困难的。值得庆幸的是,研讨迷信家曾经运用谷歌规模的硬件为我们做了这项任务,并提供了一套启示式的办法,来配置神经机器翻译的编码-解码模型和预测普通的序列。
在这篇文章中,你将会晓得,在神经机器翻译和其他自然言语处置义务中,如何最好地配置编码-解码循环神经网络的各种细节:
-
谷歌的研讨调查了各个模型针对编码-解码的设计方案,以此来别离出它们的作用效果。
-
关于一些设计方案的后果和建议,诸如关于词嵌入、编码和解码深度以及留意力机制。
-
一系列根底模型设计方案,它们可以作为你本人的序列到序列的项目的起始点。
让我们开端吧:

Sporting Park
神经网络机器翻译的编码-解码模型
用于循环神经网络的编码-解码架构,取代了经典的基于短语的统计机器翻译零碎,以取得最新的后果。
依据他们2016年宣布的论文“Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”,谷歌现已在他们的Google翻译效劳的中心中运用这种办法。
这种架构的成绩是模型很大,需求十分少量的数据集来训练。 这遭到模型训练破费数天或数周的影响,并且需求十分昂贵的计算资源。 因而,关于不同设计选择对模型的影响及其对模型技艺的影响,曾经做了很少的任务。
Denny Britz等人清楚地给出理解决方案。 在他们的2017年论文“神经机器翻译体系的少量探究”中,他们为规范的英德翻译义务设计了一个基准模型,罗列了一套不同的模型设计选择,并描绘了它们对技艺的影响。他们宣称,完好的实验消耗了超越250,000个GPU计算工夫,至多可以说是令人印象深入的。
我们报告了数百次实验运转的实验后果和方差数,对应于规范WMT英语到德语翻译义务超越250,000个GPU小时。我们的实验为树立和扩展NMT体系构造提供了新的见地和适用建议 。
在本文中,我们将审视这篇文章的一些发现,我们可以用它来调整我们本人的神经网络机器翻译模型,以及普通的序列到序列模型 。
有关编码-解码体系构造和留意力机制的更多背景信息,请参阅以下文章:
Encoder-Decoder Long Short-Term Memory Networks
Attention in Long Short-Term Memory Recurrent Neural Networks
基线模型
我们可以经过描绘用作一切实验终点的基线模型开端。
选择基线模型配置,使得模型在翻译义务上可以很好地执行。
-
嵌入:512维
-
RNN小区: 门控循环单元或GRU
-
编码器:双向
-
编码深度: 2层 (每个方向一层)
-
解码深度:2层
-
留意: Bahdanau作风
-
优化器:Adam
-
信息丧失:20%的投入
每个实验都从基准模型开端,并且改动了一个要素,试图隔离设计决策对模型技艺的影响,在这种状况下,BLEU得分。
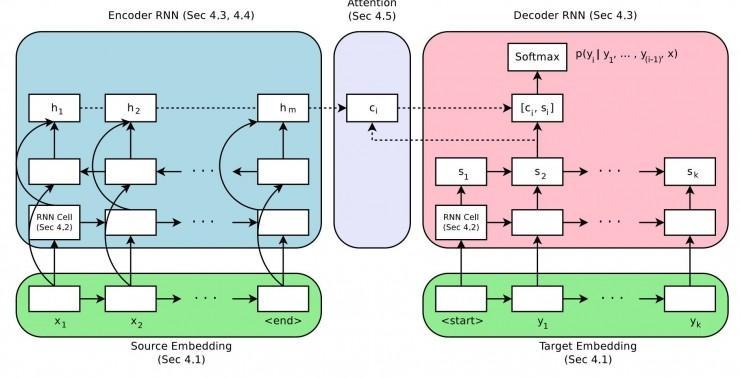
神经网络机器翻译的编码-解码体系构造
取自“Massive Exploration of Neural Machine Translation Architectures”
嵌入大小
一个词嵌入(word embedding)用于表示单词输出到编码器。
这是一个分散表示(distributed representation),其中每个单词映射到一个具有延续值的固定大小向量上。这种办法的益处是,具有类似含义的不同词语将具有相似的表示。
通常在训练数据上拟合模型时学习这种分散表示。嵌入大小定义了用于表示单词的矢量长度。普通以为,更大的维度会招致更具表现力的表示(representation),反过去功用更好。
风趣的是,后果显示最大尺寸的测试的确获得了最好的后果,但添加尺寸的收益总体来说较小。
[后果显示] 2048维的嵌入获得最佳的全体效果,他们只小幅这样做了。即便是很小的128维嵌入也表现出色,收敛速度简直快了一倍。
建议:从一个小的嵌入大小开端,比方128,也许稍后添加尺寸会细微加强功用。
RNN 单元品种共有三种常用的循环神经网络(RNN):
-
复杂循环神经网络
-
长短期记忆网络(LSTM)
-
门控循环单元(GRU)
LSTM是为理解决复杂循环神经网络中限制循环神经网络深度学习的梯度消逝成绩而开发的。GRU是为了简化LSTM而开发的。后果显示GRU和LSTM都明显强于复杂RNN,但是LSTM总体上更好。
在我们的实验中,LSTM 单元一直胜过GRU单元。
建议: 在你的模型中运用LSTM RNN单元。
编码-解码深度
通常以为,深度网络比浅层网络表现更好。
关键在于找到网络深度、模型功用和训练工夫之间的均衡。 这是由于,假如对功用的改善巨大,我们普通没有无量的资源来训练超深度网络。
作者正在探究编码模型和解码模型的深度,以及对模型功用的影响。
说到编码,研讨发现深度对功用并没有明显影响,更惊人的是,一个1层的双向模型仅优于一个4层的构造很少。一个2层双向编码器只比其他经测试的构造强一点点。
我们没有发现确凿证据可以证明编码深度有必要超越两层。
建议:
运用1层的双向编码器,然后扩展到2个双向层,以此将功用小幅度强化。
关于解码器也是相似的。1,2,4层的解码器之间的功用差别很小。4层的解码器略胜一筹。8层解码器在测试条件下没有收敛。
在解码器这里,深度模型比浅层模型表现略好。
建议: 用1层的解码器作为起步,然后用4层的解码器取得更优的后果。
编码器输出的方向
源文本序列可以经过以下几种顺序发送给编码器:
-
正向,即通常的方式
-
反向
-
正反向同时停止
作者发现了输出序列的顺序对模型功用的影响,相较于其他多种单向、双向构造。
总之,他们证明了先前的发现:反向序列优于正向序列、双向的比反向序列略好。
……双向编码器通常比单向编码器表现更好,但不是相对优势。具有反向数据源的编码器全部优于和它们相当的未反向的对照。
建议:
运用反向输出序列或许转变为双向,以此将功用小幅度强化。
留意力机制
原始的编码-解码模型有一个成绩:编码器会将输出信息布置进一个固定长度的外部表达式,而解码器必需从其中计算出整个输入序列。
留意力机制是一个提高,它允许编码器“关注”输出序列中不同的字符并在输入序列中辨别输入。
作者察看了几种复杂的留意力机制的变种。后果显示具有留意力机制将大幅提升模型表现。
当我们等待基于留意力机制的模型完胜时,才诧异地发现没有“留意力”地模型表现多么蹩脚。
Bahdanau, et al. 在他们2015年的论文 “Neural machine translation by jointly learning to align and translate” 中表述的一种复杂加权均匀的留意力机制表现最好。
建议: 运用留意力机制并优先运用Bahdanau的加权均匀的留意力机制。
推断
神经零碎机器翻译经常运用集束搜索来对模型输入序列中的单词的概率取样。
通常以为,集束的宽度越宽,搜索就越片面,后果就越好。
后果显示,3-5的适中的集束宽度表现最好,经过长度折损仅能稍微优化。作者建议针对特定成绩调理宽度。
我们发现,调理精确的集束搜索对好后果的获得十分关键,它可以继续取得不止一个的BLE点。
建议: 从贪心式搜索开端(集束=1) 并且依据你的详细成绩调理。
最终模型
作者把他们的发现都使用在同一个“最好的模型”中,然后将这个模型的后果与其他表现突出的模型和表现最高程度的后果比拟。
此模型的详细配置如下表,摘自论文。当你为自然言语处置顺序开发本人的编码-解码模型时,这些参数可以作为一个好的起始点。
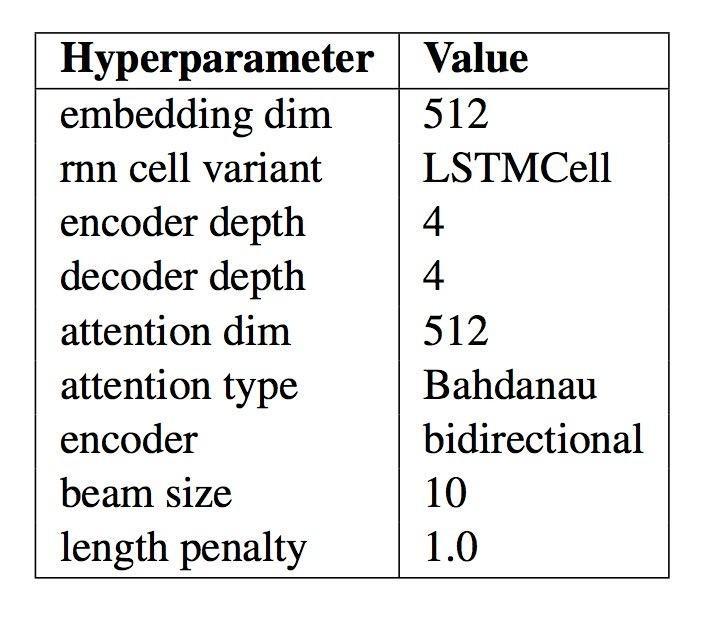
最终的神经网络机器翻译模型的模型配置总结
“Massive Exploration of Neural Machine Translation Architectures”
此零碎的后果令人印象深入,它用更复杂的模型到达了接近最先进的程度,而这并不是论文的最终目的。
……我们的确证明了经过细心的超参数调整和优秀的初始化,基于规范的WMT也能够到达最先进的程度。
很重要的一点,作者将他们的代码作为了开源项目,称作“tf-seq2seq”。2017年,由于其中两位作者时谷歌的大脑训练项目的成员,他们的效果在谷歌研讨博客上发布,标题为“Introducingtf-seq2seq: An Open Source Sequence-to-Sequence framework inTensorFlow“。
延伸阅读
假如你想深化理解,这局部提供关于此话题的更多资源。
-
Massive Exploration of Neural Machine Translation Architectures, 2017.
-
Denny Britz Homepage
-
WildML Blog
-
Introducing tf-seq2seq: An Open Source Sequence-to-Sequence framework in TensorFlow, 2017.
-
tf-seq2seq: A general-purpose encoder-decoder framework for Tensorflow
-
tf-seq2seq Project documentation
-
tf-seq2seq Tutorial: Neural Machine Translation Background
-
Neural machine translation by jointly learning to align and translate, 2015.
总结
本文论述了在神经网络机器翻译零碎和其他自然言语处置义务中,如何最好地配置一个编码-解码循环神经网络。详细是这些:
-
谷歌的研讨调查了各个模型针对编码-解码的设计方案,以此来别离出它们的作用效果。
-
关于一些设计方案的后果和建议,诸如关于词嵌入、编码和解码深度以及留意力机制。
-
一系列根底模型设计方案,它们可以作为你本人的序列到序列的项目的起始点。
雷锋网:文章来自machinelearningmastery ,雷锋字幕组编译,雷锋网发布。

。
