
雷锋网 (大众号:雷锋网) AI 科技评论按,本文为图鸭科技投稿,注释内容如下:
说到图像紧缩算法,最典型的就是 JPEG、JPEG2000 等。

图 1:典型图像紧缩算法 JPEG、JPEG2000
其中 JPEG 采用的是以团圆余弦转换(Discrete Cosine Transform)为主的区块编码方式(如图 2)。JPEG2000 则改用以小波转换(Wavelet Transform)为主的多解析编码方式,小波转换的次要目的是将图像的频率成分抽取出来。
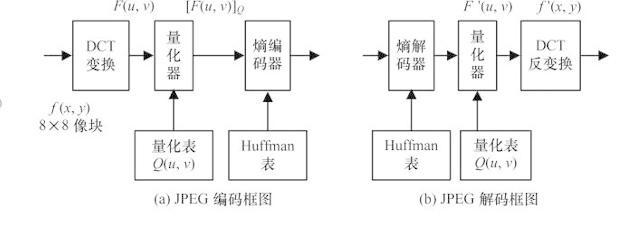
图 2:JPEG 编码框图
在有损紧缩下,JPEG2000 的分明优势在于其防止了 JPEG 紧缩中的马赛克失真效果 。JPEG2000 的失真次要是模糊失真,而模糊失真的次要缘由在于高频量在编码进程中一定水平的衰减。在高压缩比情形下(比方紧缩比小于 10:1),传统的 JPEG 图像质量有能够比 JPEG2000 好。JPEG2000 在高紧缩比的情形下,优势才开端分明。
全体来说,JPEG2000 相比于传统 JPEG,仍有很大技术优势,通常紧缩功能可进步 20% 以上。当紧缩比到达 100:1 时,JPEG 紧缩的图像曾经严重失真并开端难以辨认了,而 JPEG2000 的图像仍可辨认。
深度学习技术设计紧缩算法的目的
经过深度学习技术设计紧缩算法的目的之一是学习一个比团圆余弦变换或小波变换更优的变换,同时借助于深度学习技术还可以设计更简约的端到端算法,因此可以设计出比 JPEG2000 等商用算法功能更优的算法。
在图片、视频紧缩范畴,运用最多的深度学习技术就是卷积神经网络(CNN),上面会就卷积神经网络停止复杂引见。如图 3 所显示,像搭积木一样,一个卷积神经网络由卷积、池化、非线性函数、归一化层等模块组成。最终的输入依据使用而定,如在人脸辨认范畴,我们可以用它来提取一串数字(专业术语称为特征)来表示一幅人脸图片。然后经过比拟特征的异同停止人脸辨认。
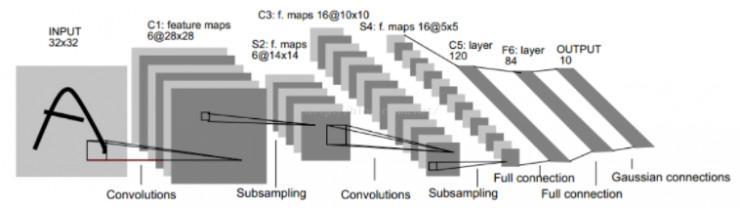
图 3 :卷积神经网络表示图
(来源 http://blog.csdn.net/hjimce/article/details/47323463)
那如何应用卷积神经网络做紧缩? 如图 4 所示,完好的框架包括 CNN 编码网络、量化、反量化、CNN 解码、熵编码等几个模块。编码网络的作用是将图片转换为紧缩特征,解码网络就是从紧缩特征恢复出原始图片。其中编码网络和解码网络,可以用卷积、池化、非线性等模块停止设计和搭建。
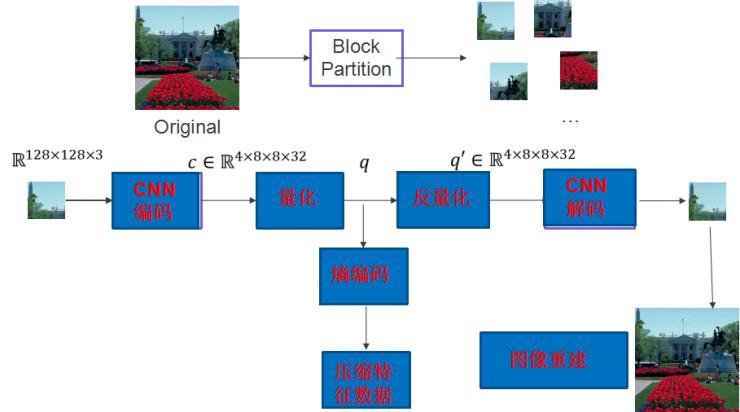
图 4:用深度学习停止图片紧缩表示图
如何评判紧缩算法
在深化技术细节前,我们先来理解一下如何评判紧缩算法。 评判一个紧缩算法好坏的重要目标有两个:一个是每个像素占据的比特位数(bit per pixel,BPP),一个是 PSNR 。我们晓得,数据在计算机中以比特方式存储,所需比特数越多则占据的存储空间越大。BPP 用于表示图像中每个像素所占据的比特数,如一张 RGB 三通道图,表示每个像素需求耗费 24 个比特。PSNR 用来评价解码后图像的恢复质量,复杂了解就是 PSNR 越高,恢复质量越好。
我们举个例子,假定长宽为 768*512 的图片大小为 1M,应用深度学习技术对它编码,经过编码网络后发生包括 96*64*192 个数据单元的紧缩特征数据,假如表示每个数据单元均匀需求耗费 1 个比特,则编码整张图需求 96*64*192 个比特。经过紧缩后,编码每个像素需求的比特数为(96*64*192)/(768*512)=3,所以 BPP 值为 3bit/pixel,紧缩比为 24:3=8:1。这意味着一张 1M 的图,经过紧缩后只需求耗费 0.125M 的空间,换句话说,之前只能放 1 张照片的空间,如今可以放 8 张。
如何用深度学习做紧缩
谈到如何用深度学习做紧缩,还是用方才那个例子。将一张大小 768*512 的三通道图片送入编码网络,停止前向处置后,会失掉占据 96*64*192 个数据单元的紧缩特征。有计算机根底的读者能够会想到,这个数据单元中可放一个浮点数,整形数,或许是二进制数。那成绩来了,究竟应该放入什么类型的数据?从图像恢复角度和神经网络原理来讲,假如紧缩特征数据都是浮点数,恢复图像质量是最高的。但一个浮点数占据 32 个比特位,那之前讲的比特数计算公式变为(96*64*192*32)/(768*512)=96,紧缩后反而每个像素占据比特从 24 变到 96,非但没有紧缩,反而添加了,这是一个蹩脚的后果,很显然浮点数不是好的选择。
所以为了设计靠谱的算法,我们运用一种称为量化的技术 ,它的目的是将浮点数转换为整数或二进制数,最复杂的操作是去掉浮点数前面的小数,浮点数变成整数后只占据 8 比特,则表示每个像素要占据 24 个比特位。 与之对应,在解码端,可以运用反量化技术将变换后的特征数据恢复成浮点数 ,如给整数加上一个随机小数,这样可以一定水平上降低量化对神经网络精度的影响,从而进步恢复图像的质量。
即便紧缩特征中每个数据占据 1 个比特位,可是 8:1 的紧缩比在我们看来并不是一个很理想的后果。那如何进一步优化算法?再看下 BPP 的计算公式。假定每个紧缩特征数据单元占据 1 个比特,则公式可写成:(96*64*192*1)/(768*512)=3,计算后果是 3 bit/pixel,从紧缩的目的来看,BPP 越小越好。在这个公式中,分母由图像决议,可以调整的局部在分子,分子中 96、64、192 这三个数字与网络构造相关。很显然,当我们设计出更优的网络构造,这三个数字就会变小。
那 1 与哪些模块相关?1 表示每个紧缩特征数据单元均匀占据 1 个比特位,量化会影响这个数字,但它不是独一的影响要素,它还与码率控制和熵编码有关。码率控制的目的是在保证图像恢复质量的前提下,让紧缩特征数据单元中的数据散布尽能够集中、呈现数值范围尽能够小,这样我们就可以经过熵编码技术来进一步降低 1 这个数值,图像紧缩率会进一步提升。
用深度学习做视频紧缩,可以看作是在深度学习图片紧缩根底上的扩展,可结合视频序列帧间的光流等时空信息,在单张紧缩的根底上,进一步降低码率。
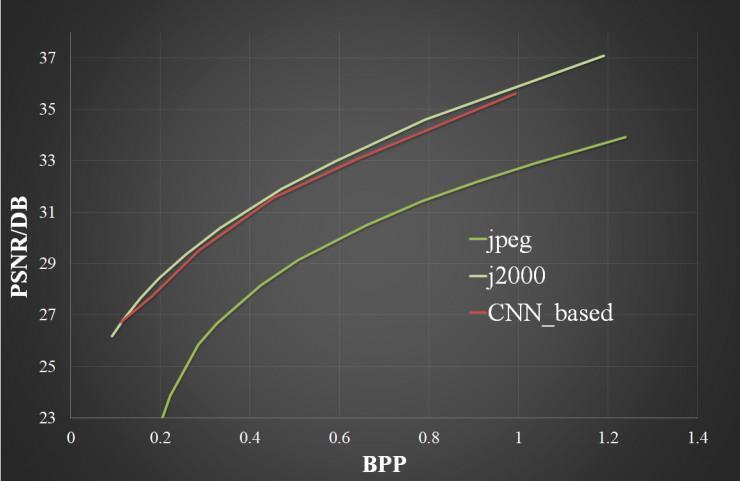
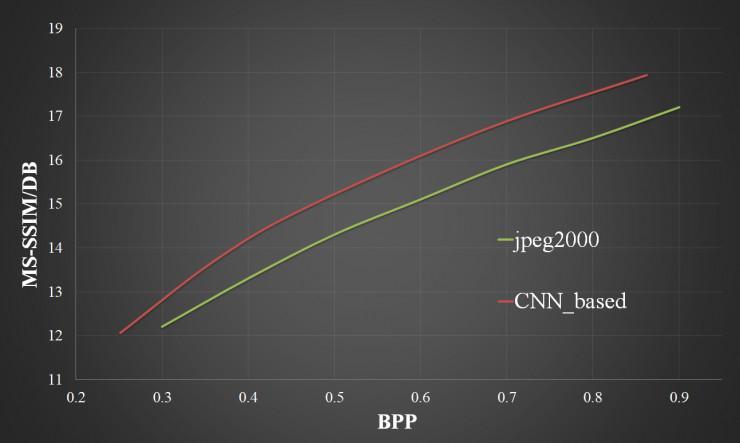
图 5:在 kodak24 规范数据集上测评后果,上图为 PSNR 后果,下图为 MS-SSIM 的后果
总结
总体而言,借助于深度学习设计视频和图像紧缩算法是一项十分具有前景但也十分具有应战性的技术。目前,其曾经在人脸辨认等范畴证明了它的弱小才能,有理由置信在不久的未来,深度学习技术将为图像视频紧缩范畴带来更大的打破。


图 6:在同等紧缩率下紧缩视觉效果比照。上图为图鸭所提出的算法,下图为 JPEG2000 算法。在纹理细节上,上图的效果更好。


图 7:在同等紧缩率下,对复杂图像紧缩视觉效果比照。上图为图鸭所提出的算法,下图为 JPEG2000 算法。在细节上,可以看到上图的效果更好。
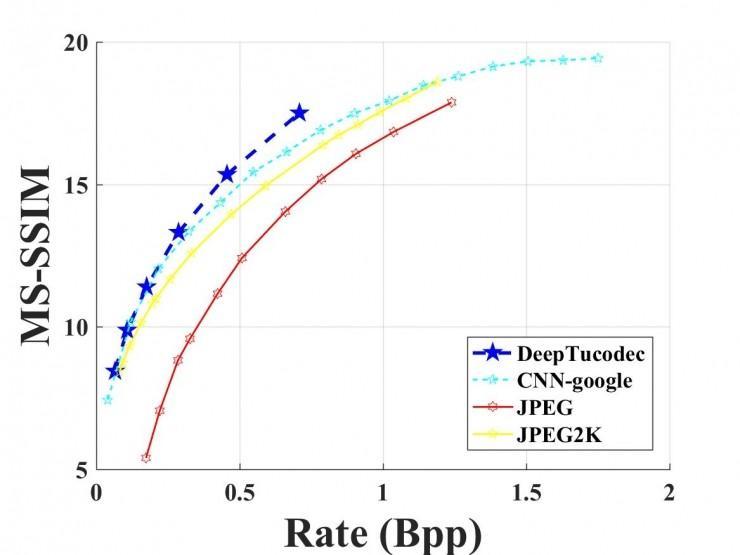
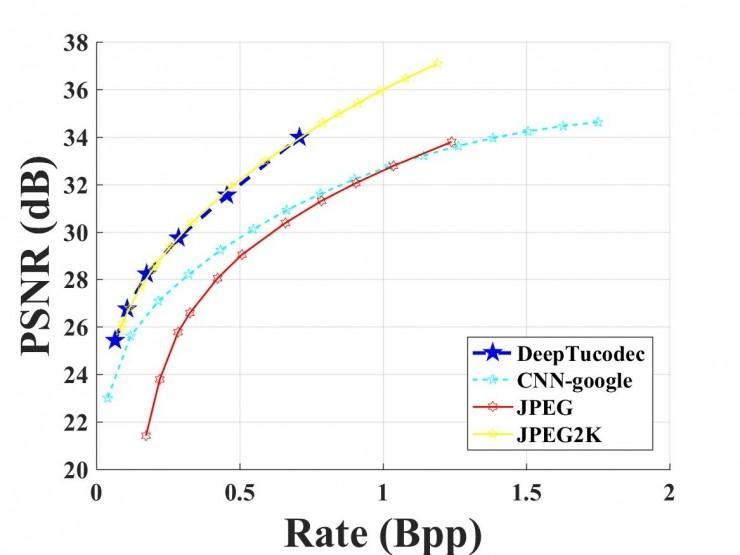
图 8:图鸭科技,BPG,JPEG2000,JPEG,CNN-google 算法的图像亮度重量的 rate-distortion 曲线,上图为感知质量,由多尺度构造类似性度量(MS-SSIM)。下图为峰值信噪比。
(完)
雷锋网版权文章,未经受权制止转载。概况见。
