
雷锋网 (大众号:雷锋网) AI科技评论按 :1月22日,号称业界“研值”最高的百度奖学金2017年度颁奖仪式在百度科技园盛大举行。AI科技评论作为协作媒体也受邀参与了颁奖典礼,共同见证了10位“AI界耀眼新星”的降生。
百度奖学金方案是为了开掘、支持和鼓舞最优秀的华人先生去处理人工智能学科范畴当中最有价值的技术成绩,促进中国人工智能的世界前沿站位,培育中国人工智能范畴的将来储藏精英技术人才。因而本次的十位获奖选手无疑都来自AI范畴,研讨方向涵盖了当今最抢手的计算机视觉,自然言语处置,机器学习,大数据发掘等相关细分方向。以下是十位选手的复杂引见。

陈师哲 ,计算机视觉范畴,主攻“多模态情感辨认”和“视频内容自然言语描绘”,在国际顶会期刊宣布相关论文十余篇。
王奕森 , 机器学习/语音范畴,主攻树类机器学习模型,尤其是随机森林模型相关的根底实际和使用。
张飚 ,自然言语处置范畴,主攻机器翻译中的长时记忆模型,提出了创新型的新模型方案。
胡志挺 ,自然言语处置范畴,主攻自然言语处置以及机器学习方向的根底实际,尤其在知识和神经网络办法相结合的方向上有独到的见地。
林衍凯 ,自然言语处置范畴,主攻知识表示学习,知识获取,知识使用方向,代表性的研讨和效果有TransR和 PTransE,NRE和MNER等。
王小龙 ,计算机视觉范畴,硕士时期次要做DPM的检测任务,博士从事预测学习(predictive learning)任务,宣布的论文屡次被国际顶会收录,目前宣布17篇论文,10篇一作,570个援用。
王云鹤 ,计算机视觉范畴,主攻神经网络减速紧缩方面的研讨。他提出了应用团圆余弦变换来提升卷积神经网络预测进程的预测速度,该办法极具创新性和适用性。
李成涛 ,机器学习范畴,主攻多样性采样方面的研讨,他和导师共同研讨运用马尔科夫链停止采样,并且运用数值计算的技术(Gauss Quadrature),极大地提升了采样效率。
吴昊 ,数据发掘范畴,主攻应用数据发掘、机器学习与深度学习处理轨迹序列建模以及预测成绩。其研讨的办法在地图大数据轨迹发掘、地图新途径发掘,以及基于大数据人流剖析具有十分重要的意义。
朱鎔 ,数据发掘范畴,主攻多层图的发掘算法, 包括Top-K牢靠搜索,SimRank类似性,Top-K稀疏子图发掘等成绩。目前宣布一作的顶级期刊和会议文章五篇 (TKDE/KAIS/ICDE/ICDM)。
雷锋网AI科技评论理解到,本次的初选评选规范次要参考选手们的学术成果,包括在国际顶级学术会议和期刊上的总发文数,以及一作和非一作的的各自占比。以上这些选手可以锋芒毕露,除了学术成果不俗、辩论环节降服评委外,最最重要的还有他们研讨效果的工程转化才能。这一点在颁奖现场也失掉了百度技术委员会主席吴华教授的认可。“相比往届的百度奖学金获奖选手们,这届百度奖学金的选手更注重把研讨与实践使用场景相结合,并获得了优秀的成果。我们希望,这些顶尖的人才干够在将来持续用他们的科研效果去推进人工智能的提高。”百度技术委员会主席,同时担任本次奖学金评审组组长吴华教授在颁奖现场如是说。
颁奖仪式完毕后, 为了能使大家更直接地感受获奖选手的学术风采。活动方约请了三位获奖者林衍凯、李成涛、王云鹤停止了扼要的学术分享,同时也约请了两位往届获奖者李纪为、黄岩前来为“新秀们”助阵。他们五位学术青年共同为大家分享了目前对话零碎、深度学习与知识图谱等范畴的最新研讨效果。
第一位分享的嘉宾是斯坦福毕业生
李纪为
,分享主题是:
教会机器说话。
大家好,很开心明天能回到这里,再次重新回到百度,我觉得十分开心! 以前是做对话的,明天就为大家分享我一两年前的任务。教会机器像人类一样交谈,需求处理两个成绩。一个是如何让机器发生比拟有意思并且有信息的内容。另一个是如何坚持机用具有分歧性,让它说话不自相矛盾。
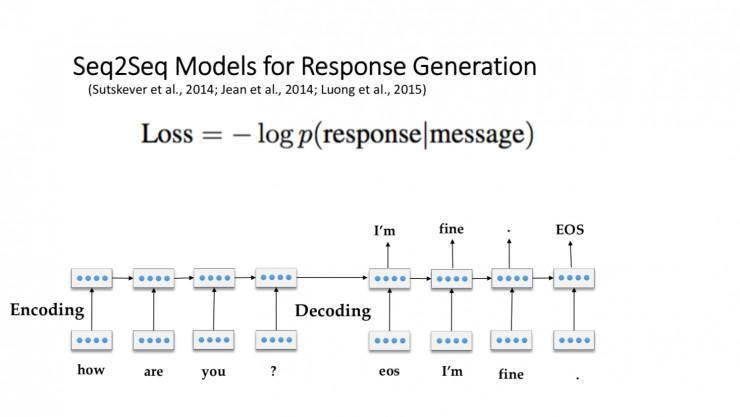
之前的这个模型,由于训练数据集里有很多无聊的回复,后果就是模型每次都会发生这种无聊的对话,比方说“我不晓得”,“呵呵”之类的。但是光制止机器答复这类无聊的成绩是不够的,机器还会发生同类,异样意思的其他语句变种,例如上面这张图。

所以要处理这个成绩首先要经过人对机器之前说的话,来猜到机器的回复是什么。机器经过人回复的话,来猜到人之前问的话是什么。
第二个成绩如何让机器对话坚持分歧性, 大家的想法是让每一团体用一个向量来替代,所以当你问一团体一百个成绩的时分,他会用同一个向量做抵扣。也就是说它会用同一个向量来去让这一百个成绩的答复发生分歧。
第二位分享嘉宾是 林衍凯 ,分享主题是: 知识表示与知识提取 。
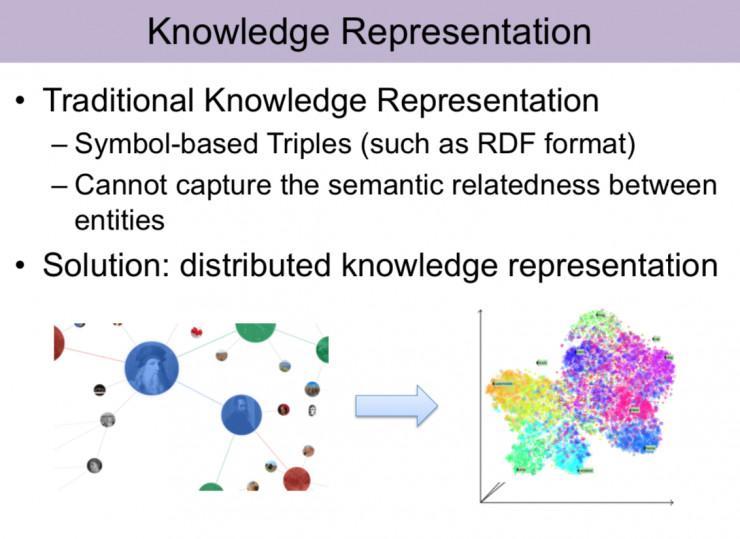
我是做偏知识图谱方向的,前两年次要在做知识的表示还有它的抽取。知识图谱,能够大家比拟熟习,就是把一些实体关系组成一个图谱。明天次要引见两方面,第一方面是知识表示,第二方面是知识获取。
知识表示其实就是将知识图谱外面的实体对应为一个空间中的向量,传统的知识图谱是以一种三元组方式去展示的,现有知识表示办法在模型复杂度较小的状况下,效果是十分好的。我们次要任务有两点,就是去处理现知识表示办法存在的一些成绩。第一个它无法去对知识图谱中的复杂关系停止建模。第二个,它无法针对知识图谱外部的关系途径去做建模。
第二局部任务是关于知识抽取。我次要做的是文本关系抽取方面的任务。我们提出了多元的关系抽取零碎,无论是在中文数据下或许在英文数据下,它抽取效果都比原始的有了十分大的进步。
第三位分享嘉宾是 黄岩 ,分享主题为: 用双向循环神经网络处置超分辨率视频。
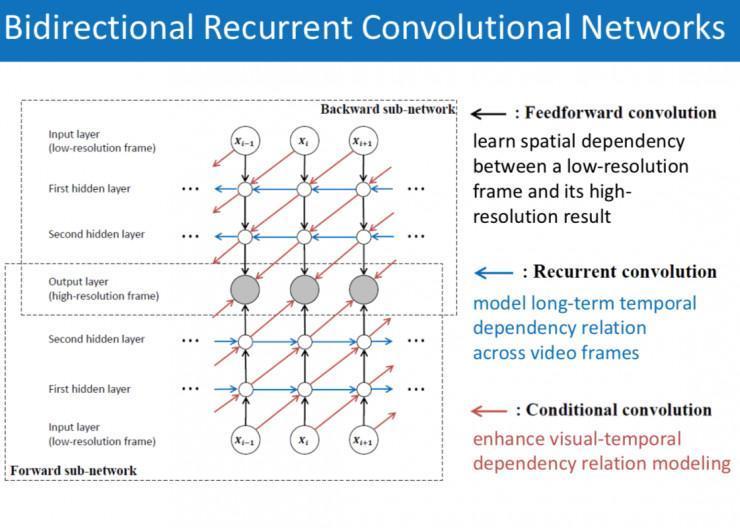 我的研讨方向是计算机视觉和深度学习,上面我将扼要引见一下循环神经网络。绝对于传统的深度神经网络,循环的网络更侧重于处置序列化的数据,最大的区别在于不同时辰隐含形态之间的循环衔接。需求留意的一点是,无论是传统的深度神经网络,还是循环网络,它们的一切输出都是向量的方式,层与层之间都是全衔接的操作。
我的研讨方向是计算机视觉和深度学习,上面我将扼要引见一下循环神经网络。绝对于传统的深度神经网络,循环的网络更侧重于处置序列化的数据,最大的区别在于不同时辰隐含形态之间的循环衔接。需求留意的一点是,无论是传统的深度神经网络,还是循环网络,它们的一切输出都是向量的方式,层与层之间都是全衔接的操作。
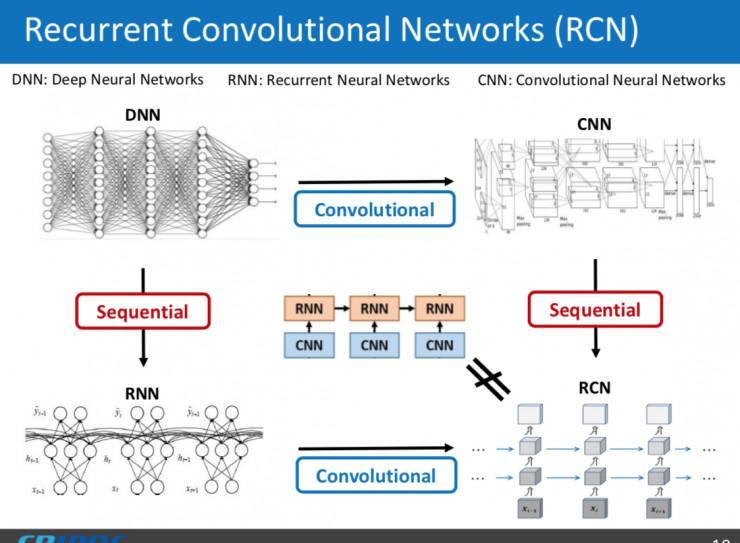
再来引见一下循环卷积网络,它其实是一个全卷积的循环网络。以上图为例,关于传统的全衔接深度神经网络,把它停止全卷积化,即把一切的全衔接都交换成卷积操作,就失掉我们常常运用的卷积网络。沿着工夫方向展开,深度神经网络就变成一个循环网络。而我所引见的循环卷积网络实质上是一个全卷积的循环网络。这种网络在参数量上有宏大优势,传统循环网络的参数量大约是在百万甚至千万左右,循环卷积网络根本上只要一两万左右,因而测试速度会得极大的提升。
使用循环卷积网络到视频超分辨率上,可以在坚持视觉内容空间构造信息的同时极大提升模型的测试速度,并且卷积操作使得我们可以处置恣意尺度的视频帧。
第四位分享嘉宾为 李成涛 ,分享主题是 : 关于多样性采样相关的实际、理论及使用 。
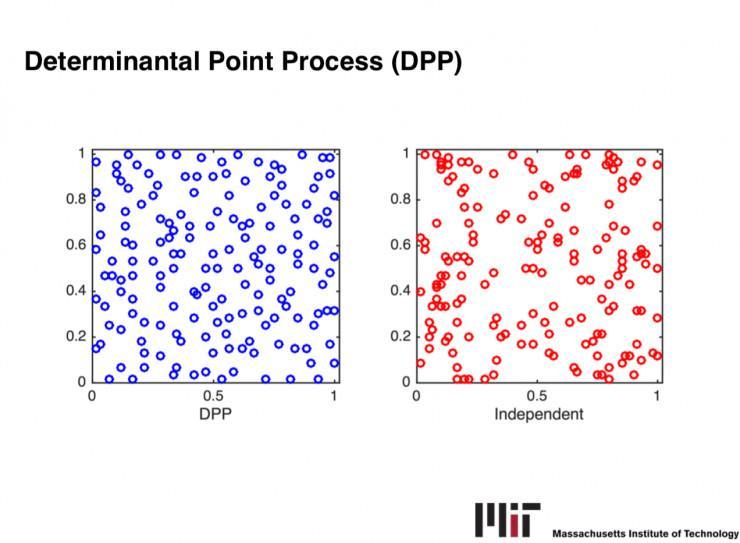
我的研讨次要是关于多样性采样方面的,详细来讲就是在一个数据集中采样出一些具有代表性的,没有冗余信息的一些样原本代表整个数据集,比方一本书的梗概,一段视频的剪辑等等,简言之就是从少量信息中提取“干货”。
经过多样性采样,我们可以极大地增加处置数据的工夫,在很短的工夫内取得较多的信息。我之前做过一些多样性采样的实际任务,次要是关于如何提升多样性采样的效率的。比方我们研讨的一个比拟典型的多样性采样的概率散布,Determinantal Point Process。它的采样进程十分耗时,我和导师研讨后经过运用马尔科夫链停止采样,在实际上证明了它的采样效率要高于本来的办法,并且运用数值计算的技术(Gauss Quadrature),极大地提升了采样效率。
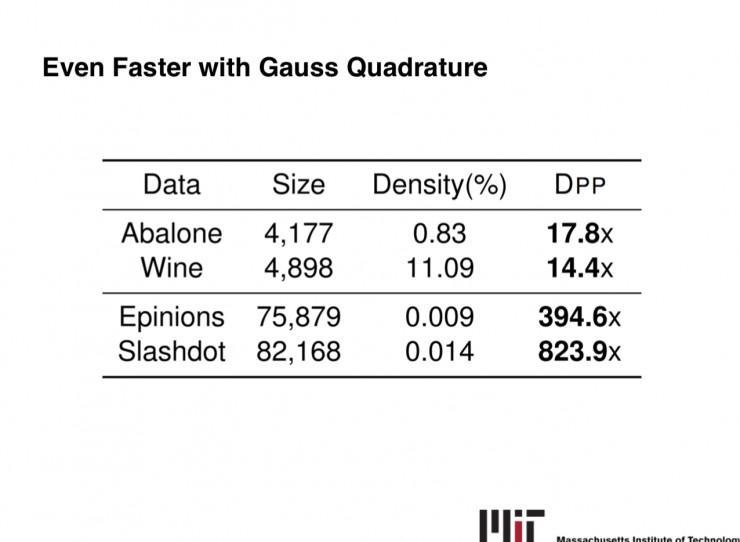
多样性采样还是有十分大的使用前景的。如今是一个信息爆炸时代,如何在更短的工夫内处置更多的信息不断是一个十分重要的课题。我觉得多样性采样在这外面会充任十分重要的角色。很多我们能够不敢想象的事情,能够都会由于多样性采样儿变成理想,比方一小时看完一本书,一分钟看完一部电影电影等等。
最初一位分享嘉宾是 王云鹤 ,分享主题为: 关于深度神经网络的紧缩方面的研讨。

我在神经网络减速紧缩方面做了深化研讨,提出应用团圆余弦变换将卷积神经网络预测进程中的卷积计算从空间域转换为频率域,在精确度只要细微下降的前提下,预测速度大幅度提升、模型耗费的存储大幅度降低。该办法极具创新性和适用性。
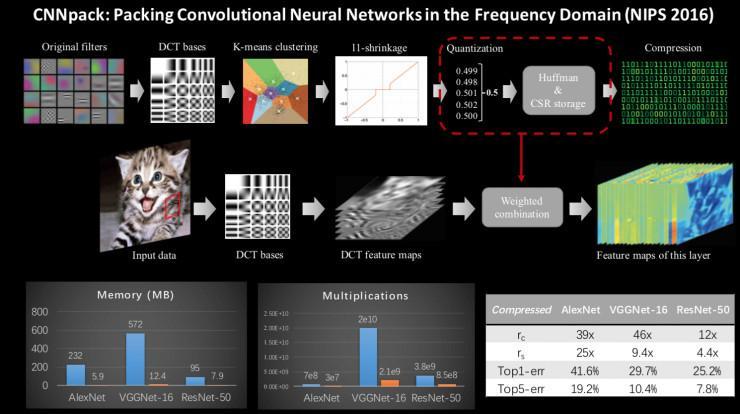
深度卷积神经网络紧缩这个课题十分具有使用前景,由于深度学习模型在大少数义务(例如图像辨认、图像超分辨率等)上的精度曾经到达了落地需求,但是它们的线上速度和内存耗费还没有到达落地需求。
但是,越来越多的实践使用需求用到这些深度学习模型,例如手机、智能摄像头、无人车等。所以如何设计更笨重、更高精度的深度神经网络依旧是一个亟需处理的成绩。
雷锋网报道
。
