
雷锋网 AI 研习社按:本文由 Anthony Goldbloom 发布于 Kaggle 官方 blog,本文先是总结了 Kaggle 在 2017 年里获得的宏大成就,然后对 2018 的新任务做了瞻望。雷锋网 (大众号:雷锋网) AI 研习社对本文停止了编译。Kaggler 们想晓得将会发作哪些变化吗?那就赶忙过去看看吧!
2017 年是 Kaggle 获得宏大开展的一年。这一年,除了参加 Google,我们还从一个次要关注机器学习竞赛的社区,扩展成一个更普遍的数据迷信和机器学习平台。往年,我们的 地下数据集 的下载量和 Kaggle Kernels 上的用户数都增长了 3 倍,这意味着我们如今拥有了一个蓬勃开展的数据存储库,并构建了一个良好的代码共享环境。
为了让社区成员们对 Kaggle 的这些变化有更好的理解,我们决议分享我们次要的活动目标(Activity metrics)以及与这些目标有关的一些剖析。不只如此,我们还将分享一些 2018 年的规划。
回忆 2017
活泼用户从 2016 年的 47.1 万增长到了往年的 89.5 万(见图1)。因而在 2017 年, 活泼用户获得了高达 90% 的增长 ,而在 2016 年这一增长率为 71%。
虽然我们以后依然以机器学习竞赛而出名,但我们的地下数据集平台和 Kaggle Kernels 将在 2018 年终成为 Kaggle 更大的推进力。
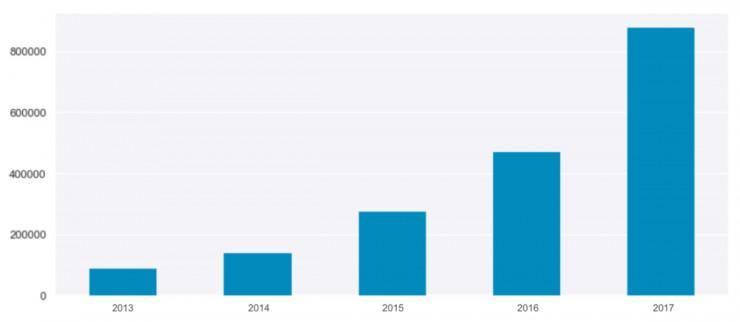
图1. 活泼用户增长状况
竞赛
我们在 2017 年发起了 41 项机器学习竞赛,高于去年的 33 项。
其中还有 3 项竞赛的奖金超越 100 万美元:
在「 从身体的扫描图中辨认出能否携带风险物品 」竞赛中,TSA 资助 150 万美元
在「 预测房价 」竞赛中,Zillow 资助 120 万美元
在「 经过 CT 扫描图诊断出能否患有肺癌 」竞赛中,NIH 与 Booz Allen 资助 100 万美元
我们同时也添加了对学术界的投入,比方协助 NIPS 和 CVPR 研讨会举行了一些重要的研讨竞赛。其中的亮点包括一系列 对立学习(Adversarial learning) 应战赛和 YouTube 8M 应战赛。此外,Kaggle 如今也正式托管了 ImageNet 。
Kaggle inClass 则允许教授收费举行面向先生的竞赛,它曾经成为一个完全自助效劳的平台并且获得了很好的开展。2017 年,共有 1217 个机器学习和统计班级在 Kaggle inClass 上举行了竞赛,相比起 2016 年的 661 个有所进步(增长率 84%)。
在社区方面,37.5 万名用户下载了竞赛数据集,同比去年增长 62%。而且,有 12.2 万名用户参与了我们的机器学习竞赛,同比去年增长了 54%。
地下数据集平台
我们的地下数据集平台允许我们的社区成员在公共数据集上停止共享和协作。2017 年有 7044 个数据集被上传到平台上,而 2016 则有 495 个数据集被上传。2017年所上传的最受欢送的数据集有:
-
World Happiness Report
-
Bitcoin Historical Data
-
Medical Appointment No Shows
2017 年,我们 地下数据集平台 上的数据集 下载量增长了 3 倍 以上,到达了 33.9 万次,而 2016 年则为 10.7 万次。这种增长意味着地下数据集平台正在推进数据的下载量。我们在 2016 年发布地下数据集平台,而竞赛平台则是 2010 发布的。
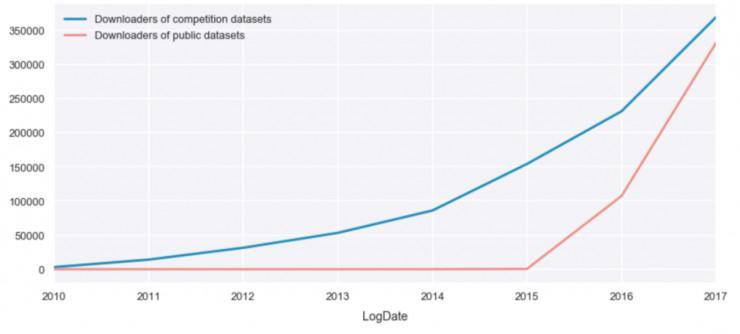
图2. 公共数据集平台的下载量 vs. 竞赛平台下载量
Kaggle Kernels
Kaggle Kernels 目前用于在竞赛和地下数据集平台上共享代码和模型。在 2017 年,Kaggle 之心的用户数量到达了 11.3 万,相比起 2016 年的 3.9 万增长了将近 3 倍。Kernel 创作(Kernel authoring)正迅速变得和参与竞赛一样受欢送(见图3)。
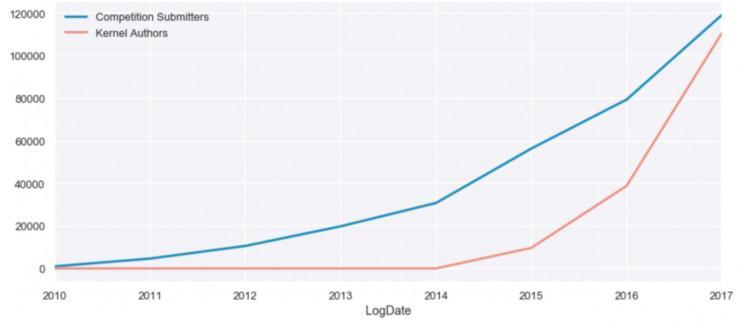
图3. 中心作者 vs 竞赛报名者
往年最受欢送的几个开源 Kernel 是:
-
针对 2017 年数据迷信杯赛(Data Science Bowl)——从 CT 扫描图中检测肺癌而编写的 图像预处置教程
-
运用 Python 完成 模型的堆叠和嵌入教程
-
一个片面的数据探究教程
其它亮点
我们发起了有史以来规模最大的数据迷信家和机器学习者的 调查研讨 。共有 16716 名受访者,最终发生 235 个探究 数据集 的地下 kernel。大家可以在 FT 和 Verge 上看到该项调查的最片面报告。
总的来说,往年我们在旧事界发生了很多话题,包括 Kaggle 被收买( Techcrunch )的报道,对几个社区精英成员( Wired 和 Mashable )的报道,NIPS 对立学习应战赛( MIT Tech Review ),TSA 竞赛( NYTimes )和 Zillow 竞赛( NYTimes )。
值得强调的是,社区的活泼有助于增强我们的活动。我们已知的线下 Kaggle 聚会小组 就有 50 多个,这些小组都由 Kaggle 社区成员自发组织构成,从 普林斯顿 到 巴黎 。大家会在聚会上讨论我们的竞赛和数据集。往年,一些 Kaggle 精英成员还在 Coursera 上发起了“如何博得 Kaggle 竞赛”的课程 。还有一群社区成员设立了一个“ Kaggle slack ”频道来讨论 Kaggle 竞赛和数据集,它目前曾经拥有超越 3300 名成员。
瞻望 2018
Kaggle 从机器学习竞赛开端,到现今曾经扩展出了一个地下数据集平台和 Kaggle Kernels。而我们的终极理想是将 Kaggle 打形成一个合适于迷信研讨的场所——一切 Kagglers 都可以停止数据迷信和机器学习的相关研讨。2018 年,我们将 专注于改良一切的中心产品 (竞赛、地下数据集平台和 Kaggle Kernels),并为我们的平台添加新的教育资源。
竞赛平台
目前竞赛平台处于一个很好的开展形态。但是我们不能自满,要不时创新。在 2018 年,我们方案开端支持新的竞赛类型,以确保 Kaggle 竞赛能支持机器学习和 AI 的前沿成绩。要做到这一点,我们需求努力于完成代码竞赛支持(Code-only competitions,指的是 Kagglers 在竞赛中需求上传代码而不只仅是后果的数据文件)。 这将使得我们可以举行全新类型的竞赛,包括像强化学习竞赛和计算资源受限的竞赛 。
地下数据集平台
在 2018 年,我们希望地下数据集平台能获得和我们的机器学习竞赛一样的名望。为此,我们需求持续添加 Kaggle 上高质量数据集的数量。我们计划运用一系列弱小的新功用来做到这一点。我们正在方案整合和添加新效劳,使得我们的社区可以经过与 BigQuery 这样的数据仓库停止集成以处置更大的数据集。并树立允许 Kagglers 在实时数据集中流式传输的功用,而不只仅是上传静态数据集。
Kaggle Kernels
Kaggle Kernels 目前最大的用途在于 模型共享、竞赛和公共数据集平台的数据集剖析 。在 2018 年,我们想让 Kaggle Kernels 成为一个弱小的独立产品,这包括使得 Kagglers 可以在公有的数据集上运用,支持拜访 GPU 集群和愈加复杂的管道操作。
Kaggle 教育
许多用户来 Kaggle 开启他们的数据迷信事业,并进步他们的学习兴味。为了更好地支持这一块,我们在 https://www.kaggle.com/learn 上推出了机器学习理论课程平台。我们希望它能成为用户们开端创立高度准确的机器学习模型,并掌握他们所需技艺的最便捷途径,以助力他们开启本人的第一份数据迷信任务。
Via blog.kaggle.com ,雷锋网 AI 研习社编译。
雷锋网版权文章,未经受权制止转载。概况见。
