
雷锋网AI研习社按 :对立样本是一类被歹意设计来攻击机器学习模型的样本。它们与真实样本的区别简直无法用肉眼分辨,但是却会招致模型停止错误的判别。本文就来大家普及一下对立样本的根底知识,以及如何做好对立样本的攻与防。
在近期雷锋网AI研习社举行的线上地下课上,来自清华大学的在读博士生廖方舟分享了他们团队在 NIPS 2017 上一个对立样本攻防大赛中提到的两个新办法,这两个办法在大赛中辨别取得了攻击方和防卫方的第一名。点击可 视频回放
廖方舟,清华大学化学系学士,生医系在读博士。研讨方向为计算神经学,神经网络和计算机视觉。参与屡次 Kaggle 竞赛,是 Data Science Bowl 2017 冠军,NIPS 2017 对立样本竞赛冠军。Kaggle 最高排名世界第10。
分享主题:
动量迭代攻击和高层引导去噪:发生和进攻对立样本的新办法

分享内容:
大家好,我是廖方舟,明天分享的主题是对立样本的攻和防。对立样本的存在会使得深度学习在平安敏理性范畴的使用收到要挟,如何对其停止无效的进攻是很重要的研讨课题。 我将从以下几方面做分享。
什么是很多朋友说,共享纸巾机是一个广告机,但我们不是这样定义它,我们定义它是一个互联网跟物联网结合的终端机,从线下吸入流量,重新回到线上,以共享纸巾项目作为流量入口,打造全国物联网社交共享大平台。对立样本
传统的攻击办法
传统的防卫办法
动量迭代攻击
去噪办法
高层引导去噪办法
什么是对立样本
对立样本的性质不只仅是图片所拥有的性质,也不只仅是深度学习神经网络独有的性质。因而它是把机器学习模型使用到一些平安敏理性范畴里的一个妨碍。
事先,机器学习大牛Good fellow找了些船、车图片,他想逐步参加一些特征,让模型对这些船,车的辨认逐步变成飞机,到最初发现人眼观测到的图在互联网思维的影响下,传统服务业不再局限于规模效益,加强对市场的反应速度成为传统服务业发展的首要选择。在互联网思维下,通过对传统服务业的改革,为传统服务业发展创造了全新的天地。片仍然是船、车,但模型曾经把船、车当做飞机。

我们之前的任务发现样本不只仅是对最初的预测发生误导,对特征的提取也发生误导。这是一个可视化的进程。
当把一个正常样本放到神经网络后,神经元会专门察看鸟的头部,但我们给它一些对立样本,这些对立样本也都全部设计为鸟,就发现神经网络提取出来的特征都是乌七八糟,和鸟头没有太大的关系。也就是说诈骗不是从最初才发作的,诈骗在从模型的两头就开端发生的。

下图是最复杂的攻击办法——Fast Gradient Sign Method

除了FGSM单步攻击的办法,它的一个延伸就是多步攻击,即反复运用FGSM。由于有一个最大值的限制,所以单步的步长也会相应减少。比方这里有一个攻击三步迭代,每一步迭代的攻击步长也会相应减少。

发生图片所用的CNN和需求攻击的CNN是同一个,我们称为白盒攻击。与之相反的攻击类型称为黑盒攻击,也就是对需求攻击的模型一无所知。
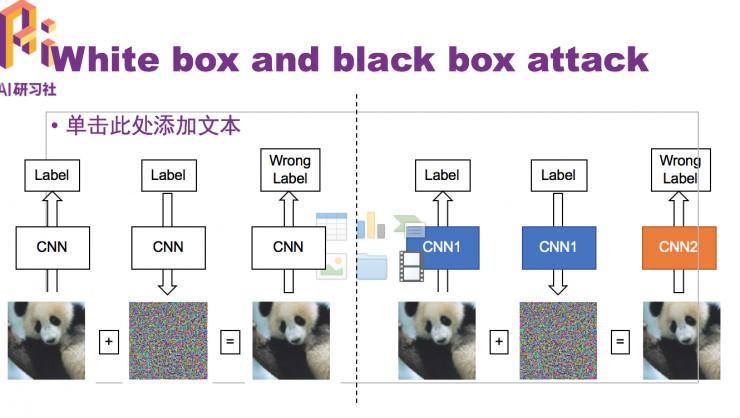
以上所说的都是Non Targeted, 只需最初失掉的目的预测不正确就可以了。另一种攻击Targeted FGSM,目的是不只要分的不正确,而且还要分到指定的类型。

一个进步黑盒攻击成功率卓有成效的方法,是攻击一个集合。

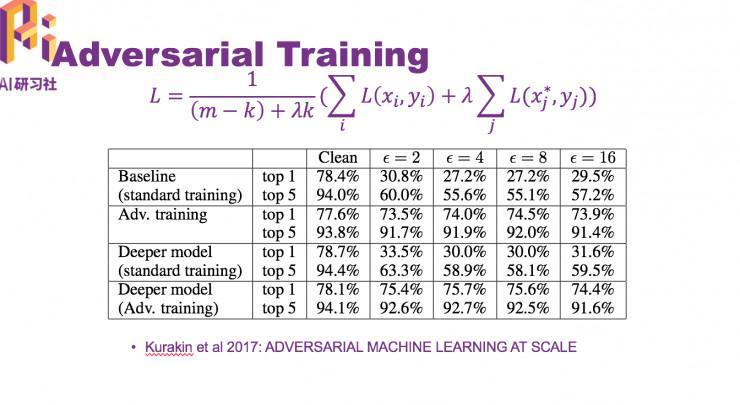
而目前为止一个卓有成效的防卫战略就是对立训练。在模型训练进程中,训练样本不只仅是洁净样本,而是洁净样本加上对立样本。随着模型训练越来越多,一方面洁净图片的精确率会添加,另一方面,对对立样本的鲁棒性也会添加。
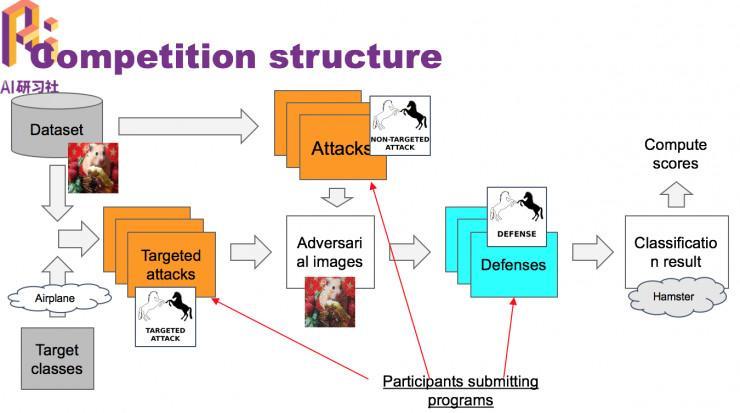
上面复杂引见一下NIPS 2017 上的这个竞赛规则
竞赛构造
两个限制条件 :容忍范围不能太大;不能花太长工夫发生一个对立样本,或许防卫一个对立样本

FGSM算法后果
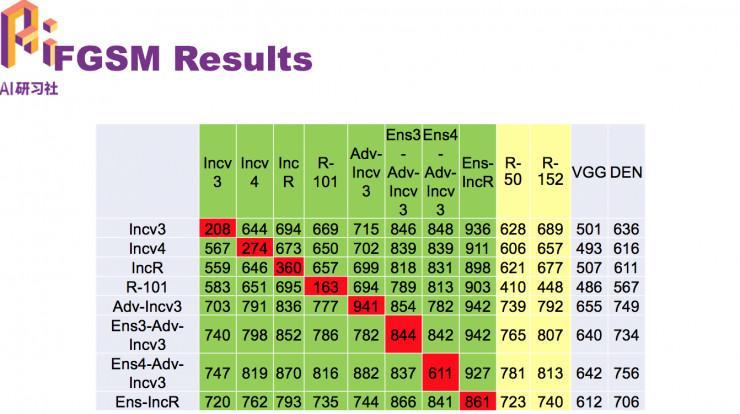
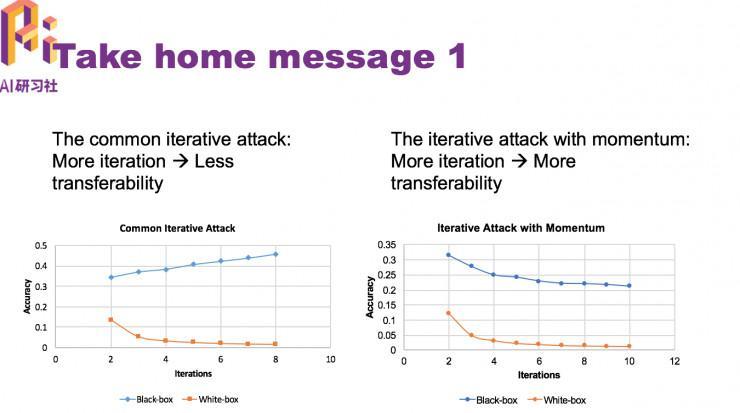
图中绿色模型为攻击范围,最初两栏灰色是黑盒模型,随着迭代数量的添加, 攻击成功率反而上升。这就给攻击形成了难题。
我们处理的方法就是在迭代与迭代两头参加动量

参加动量之后,白盒攻击变强了,而且对黑盒模型攻击的成功率也大大提升了。
总结:
以后方法(iterative attack)的弱点是在迭代数量增多的状况下,它们的迁移性,也就是黑盒攻击性会削弱,在我们提出参加动量之后,这个成绩失掉理解决,可以很担心运用十分多的迭代数量停止攻击。
在NIPS 2017 竞赛上失掉最高的分数
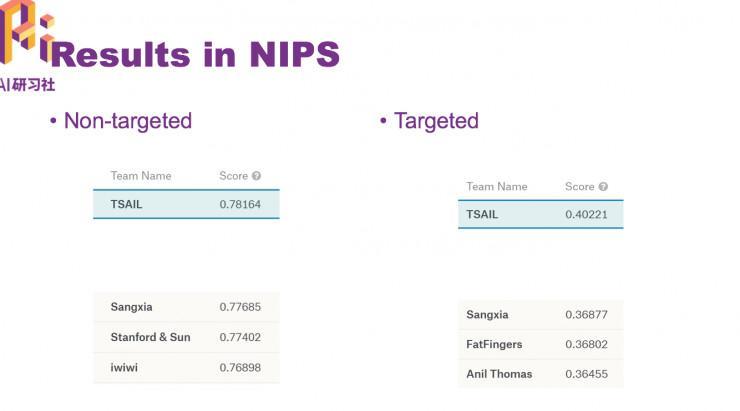
需求提到的一点,下面提到的都是Non-targeted , 在Targeted攻击外面,这个战略有所不同。在Targeted攻击外面,根本没有察看到迁移性,也就是黑盒成功率不断很差,即使是参加动量,它的迁移水平也十分差。
上面讲一下防卫
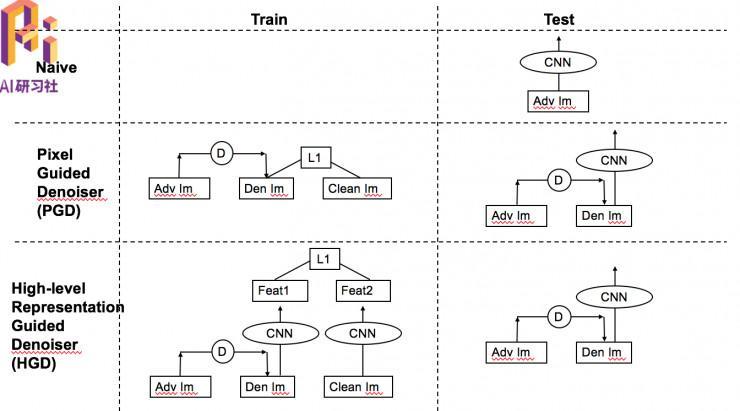
首先想到的就是去噪声,我们尝试用了一些传统的去噪办法(median filter 、BM3D)效果都不好。之后我们尝试运用了两个不同架构的神经网络去噪。一个是 Denoising Autoencoder,另一个是Denoising Additive U-Net。
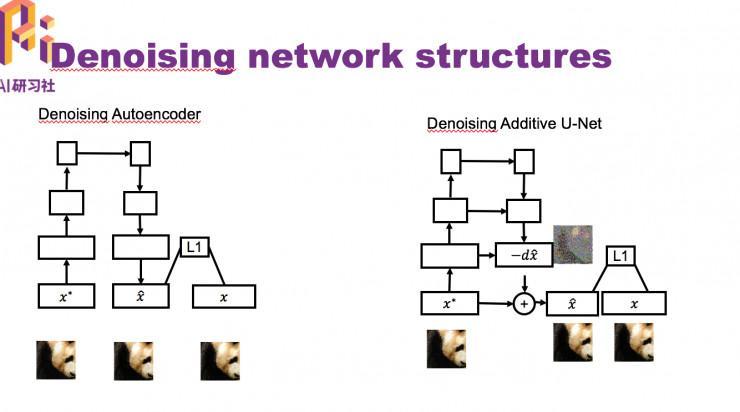
我们的训练样本是从ImageNet数据集中取了三万张图片 ,运用了七个不同的攻击办法对三万张图片攻击,失掉21万张对立样本图片以及三万张对应的原始图片。除了训练集,我们还做了两个测试集。一个白盒攻击测试集和一个黑盒攻击测试集。

训练效果
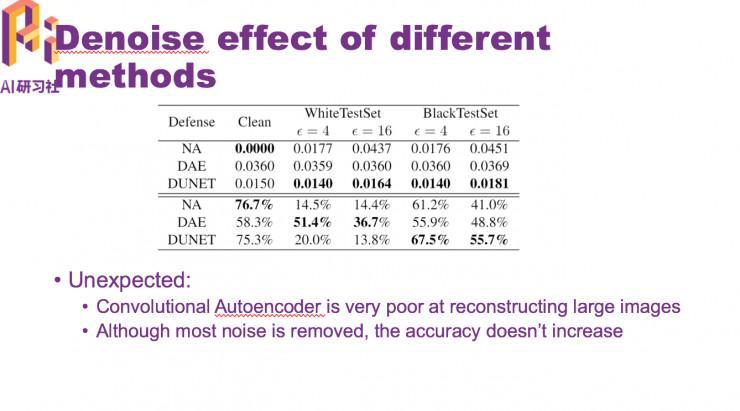
我们发现经过来噪当前,正确率反而有点下降。我们剖析了一下缘由,输出一个洁净图片,再输出一个对立图片,然后计算每一层网络在这两张图片上表示的差距,我们发现这个差距是逐层缩小的。
图中蓝线发现缩小的幅度十分大,图中红线是去噪当时的图片,依然在缩小,招致最初还是被分错。
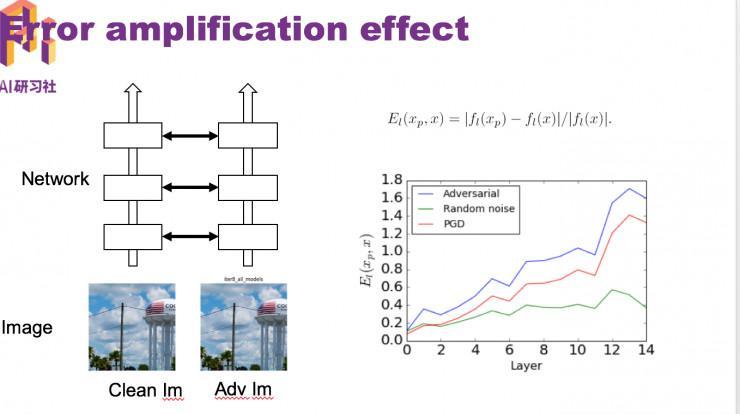
为理解决这个成绩,我们提出了经过改进后的网络 HGD
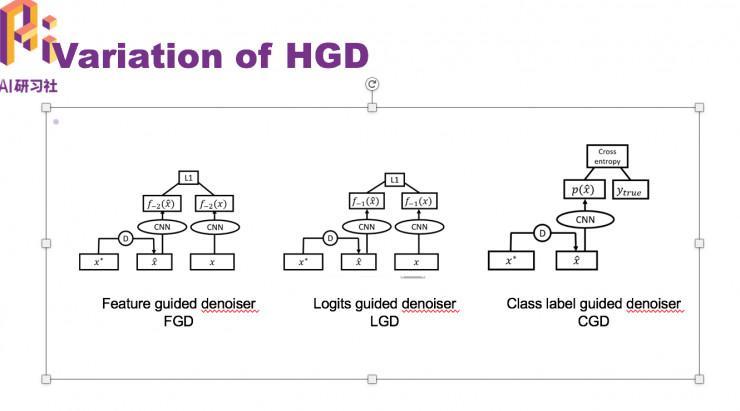
HGD 的几个变种
和之前的办法相比,改进后的网络 HGD防卫精确率失掉很大的提升
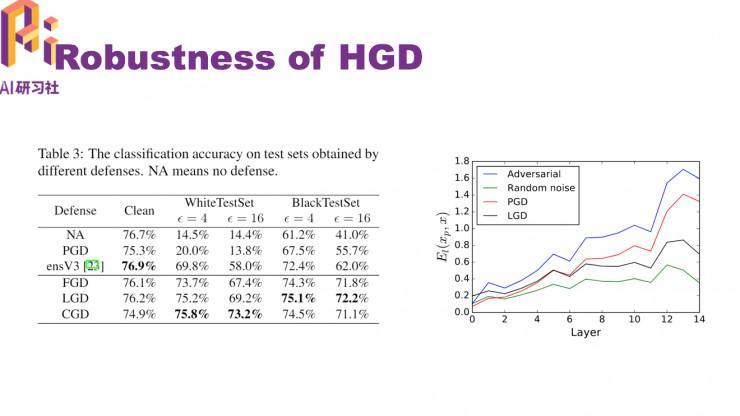
HGD 有很好的迁移性
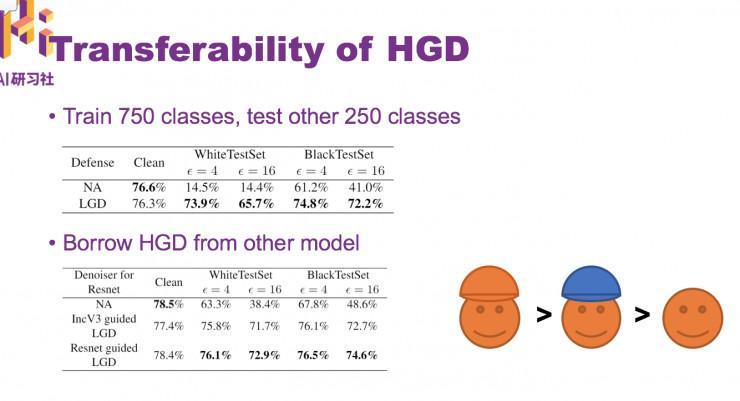
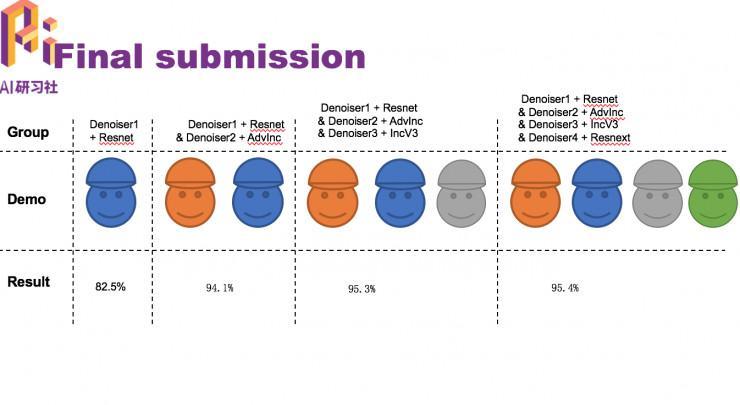
最初竞赛中,我们集成了四个不同的模型,以及训练了他们各自的去噪, ,最终把它们兼并起来提交了上去。
HGD网络总结
优点:
效果明显比其他队伍的模型好。
比后人的办法运用更少的训练图片和更少的训练工夫。
可迁移。
缺陷:
还依赖于巨大变化的可测量
成绩并没有完全处理
依然会遭到白盒攻击,除非假定对手不晓得HGD的存在
雷锋网 (大众号:雷锋网) AI慕课学院提供了本次分享的视频回放:http://www.mooc.ai/open/course/383
。
