
大众号/AI科技大本营
作者 | Lars Hulstaert
翻译 | 林椿眄
编辑 | 谷磊
在这篇博文中,你将理解到什么是迁移学习,它的一些使用以及它为什么可以成为数据迷信家应具有的关键技艺。
迁移学习不是机器学习的一个模型或技术,它是 机器学习 中的一种“设计办法论”,还有一些其他的设办法论,比方说自动学习。

本文是AI科技大本营编译的迁移学习系列的第一篇文章。第二篇文章也会在近期放送给大家,其中讨论了迁移学习的两种使用。
在后续的文章中,作者将解释如何结合自动学习与迁移学习来最优天时用现有(或许新的)数据。 从狭义上说,在应用内部信息来进步功能或泛化才能时,可以运用迁移学习来完成一些机器学习的使用。
▌迁移学习的定义
迁移学习的总体思绪是:关于带少量标签数据及可用参数设置的源义务,迁移已学习的知识,处置带大批标签的目的义务。由于标志数据的本钱是昂贵的,最佳天时用现无数据集来处理目的义务是关键。
在传统的机器学习模型中,次要目的是将训练数据中学习到的形式,推行到未知的数据。 经过迁移学习,你可以尝试从曾经学习的义务形式开端,启动这个泛化进程。实质上,这不是从无到有地(通常是随机初始化的)开端学习进程,而是在学会了其他义务形式的根底上开端学习新义务。

可以从图像中区分线条和外形(左),这些特征可以更容易确定图中能否是“汽车”。可以运用迁移学习来学习其他计算机视觉模型中的形式,而不用从图像的原始像素值开端。
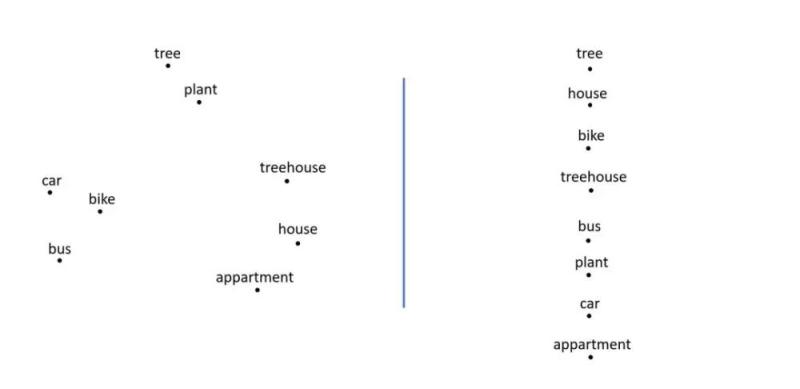
存在不同的办法来表示自然言语中的单词(词嵌入像左、右侧的词表示)。借助词嵌入算法,机器学习模型就可以应用不同单词之间存在的关系。
知识和形式的迁移在各种范畴都是有能够完成的。这篇文章将经过几个不同范畴的例子来阐明迁移学习是如何任务的。我们的目的是鼓舞数据迷信家在机器学习项目中运用迁移学习,并让他们认识到这种办法的优缺陷。
关于迁移学习的了解,以下这三个方面是我以为数据迷信家都应具有的关键技艺:
- 在任何一种学习形式中,迁移学习的使用都是至关重要的。为了取得成功,人类不能够学习到每一个义务或成绩。每团体都会遇到从未遇到过的状况,但我们依然希望以特殊的方式处理成绩。从少量的经历中学习,并将“知识”转移到新环境中的才能正是迁移学习的关键所在。从这个角度来看,迁移学习和泛化才能在概念层面上是十分类似的。它们的次要区别在于迁移学习常常被用于“跨义务迁移知识,而不是在一个特定的义务中停止概括”。因而,迁移学习与一切机器学习模型所必需的泛化才能概念有着内在联络。
- 关于小数据量状况下深度学习技术,使用迁移学习是获得成功的关键。在实践研讨中,深度学习简直是无处不在,但是关于很多理想生活场景来说,通常都没无数百万个带标签的数据来训练模型。而深度学习技术需求少量的数据来调整神经网络中的数百万个参数,特别是在监视式学习的状况下。这就意味着你需求少量带标签数据来训练模型,而标注数据则需求昂贵的人工本钱。标志图像听起来很往常的,但是在诸如自然言语处置(NLP)义务中,需求专家知识才干创立大型标志数据集。例如,Penn treebank是一个词性标注语料库,至今已有7年的历史了,它需求与多位言语学专家的亲密协作才干完成。为保证小数据量上的神经网络可以正常运转,迁移学习是一种可行的办法。而其他可行的选择正朝着更多概率启示的形式开展,这些形式通常更合适处置无限的小数据集。
- 迁移学习有着明显的优点和缺陷。理解这些缺陷关于机器学习使用顺序的成功是至关重要。知识迁移只要在“适当”的状况下才有能够。这种状况下,确切地定义“适当”的概念是不容易的,需求点经历知识来协助确定。例如,你不应该置信一个在玩具车里开车的孩子可以开上法拉利。迁移学习的原理也是一样的:虽然它很难被量化,但迁移学习也是有下限的,也就是说它不是一个合适一切成绩的处理方案。
▌迁移学习的普通概念
迁移学习的要求
正如它的名字,迁移学习需求将知识从一个范畴迁移到另一个范畴的才能。通常,迁移学习可以在高层级上停止解释。例如,自然言语处置义务中的体系构造可以在序列预测成绩中反复运用,由于很多自然言语处置成绩实质上都可以归结为序列预测成绩。迁移学习也可以在低层级上停止解释,例如在实践中你常常会反复运用不同模型中的参数(跳过词组,延续词袋等)。迁移学习的要求,一方面是针对详细的成绩而定,另一方面则是由详细的模型决议。接上去的两节将辨别讨论迁移学习在高层级和低层级的使用办法。虽然在文献中通常会用不同的名字来论述这些概念,但是迁移学习的总体概念依然存在。
多义务学习
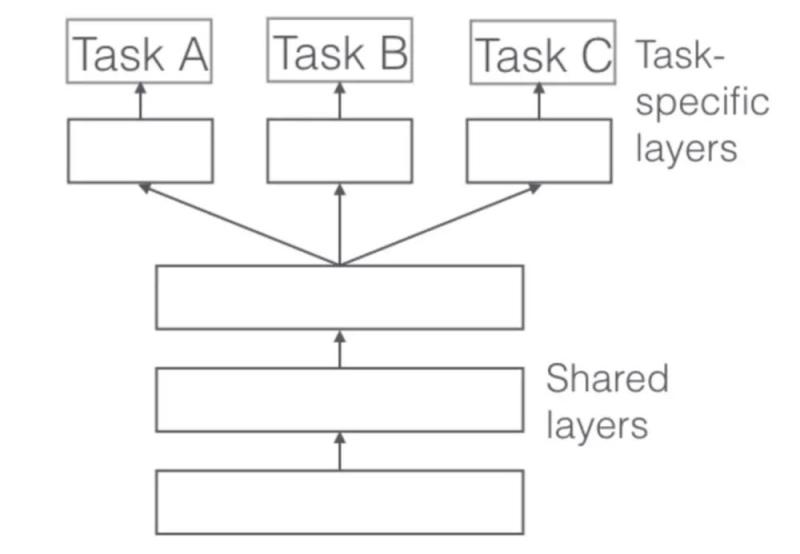
在多义务学习中,你可以同时在不同的义务上训练模型,通常这些都是深度学习模型,由于它们可以灵敏地停止调整。
网络体系构造是这样调整的:第一层跨越不同的义务运用,随后为不同的义务指定特定的义务层和输入。总体的思绪是,经过对不同义务的网络停止训练,网络将更好地推行,由于模型需求在类似的“知识”或“处置”义务上表现良好。
例如,自然言语处置义务的最终目的是执行实体辨认的模型,而不是在实体辨认义务地道地训练模型。你还用它来处置一局部语音分类,词语联想等义务……因而,模型将从不必的构造、不同的义务和不同的数据集的学习中获益。假如你想学习更多关于多义务学习的内容,激烈建议你阅读Sebastian Ruder的关于多义务学习的博文(http://ruder.io/multi-task/)。
▌ 特征提取
深度学习模型的一大优点是可以“自动化”地提取特征。基于标志的数据和反向传达规律,网络可以捕获到对义务有用的特征。例如,关于图像分类义务,网络会计算出输出的哪一局部是重要的。这意味着手动定义的特征是很笼统的,而深度神经网络学习到的特征可以在其他成绩中反复地运用。由于网络所提取的特征类型,经常对其他成绩也是有用。实质上,你可以运用网络的第一层来确定有用的特征,但是你不能在其他义务上运用网络的输入,由于这些输入是针对特定义务的。
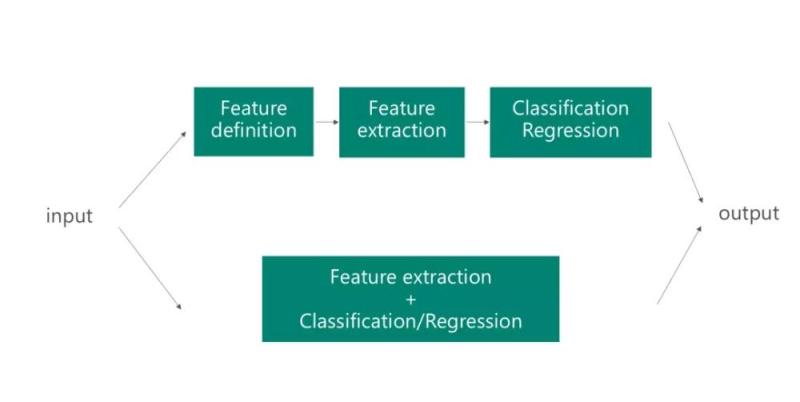
思索到深度学习零碎弱小的特征提取才能,如何反复运用现有网络来执行其他义务的特征提取?
这里有一个办法,可以将新的数据样本馈送到网络中,并将网络中的一个两头层作为输入。这个两头层可以被设置为一个固定的长度,来表示原始数据的输入。特别地,在计算机视觉范畴运用图像特征,馈送到预训练好的网络(例如,VGG或AlexNet),并在新的数据表示上运用不同的机器学习办法。提取两头层作为图像的表示可以明显地增加了原始数据大小,以便它们更合适于传统的机器学习技术(例如,关于一个128×128的小图像:大小为128×128=16384像素,逻辑回归算法或支持向量机通常有更好的算法功能)。
在接上去的博文中,作者还将深化讨论转移学习两种的使用,并器具体的例子来进一步阐明,AI科技大互联网思维,就是在(移动)互联网+、大数据、云计算等科技不断发展的背景下,对市场、用户、产品、企业价值链乃至对整个商业生态进行重新审视的思考方式。本营将继续编译,欢送持续关注。
原文链接
https://towardsdatascience.com/transfer-learning-leveraging-insights-from-large-data-sets-d5435071ec5a