
雷锋网 AI 研习社按,日前,DeepMind 推出一种全新的散布式智能体训练框架 IMPALA,该框架具有高度可扩展性,将学习和执行进程分开,运用了一种名为 V-trace 的离战略(off-policy)修正算法,具有明显的减速功能,极高的效率。详细如何呢,雷锋网 (大众号:雷锋网) AI 研习社将其原文编译整理如下:
深度强化学习 (DeepRL) 在一系列义务中获得很明显的效果,比方机器人的延续控制成绩、玩围棋和 Atari 等游戏。目前为止,我们看到的这些效果仅限于单一义务,每个义务都要独自对智能体停止调参和训练。
在我们最近的任务中,研讨了在多个义务中训练单个智能体。
明天我们发布 DMLab-30,这是一组横跨很多应战的新义务,在视觉一致的环境中,有着普通的举动空间(action space)。想训练好一个在许多义务上都有良好表现的智能体,需求少量的吞吐量,无效应用每个数据点。
为此,我们开发了一种全新的、高度可扩展的散布式智能体训练框架 IMPALA(重点加权举动-学习器框架,importances Weighted Actor-Learner Architectures),这种框架运用了一种名为 V-trace 的离战略(off-policy)修正算法。
DMLab-30
DMLab-30 是经过开源强化学习环境 DeepMind Lab 设计的一系列新义务。有了 DMLab-30,任何深度强化学习研讨人员都可以在大范围的、风趣的义务中测试零碎,支持独自测试、多义务环境测试。

这些义务被设计得尽能够多样化。它们有着不同的目的,有的是学习,有的是记忆,有的则是导航。它们的视觉效果也各不相反,比方有的是颜色艳丽、古代作风的纹理,有的是拂晓、正午或夜晚的沙漠中奇妙的棕色和绿色。环境设置也不同,从开阔的山区,到直角迷宫,再到开放的圆房间,这里都存在。
此外,一些环境中还有「机器人」,这些机器人会执行以目的为导向的行为。异样重要的是,义务不同,目的和奖励也会有所不同,比方遵照言语指令、运用钥匙开门、采摘蘑菇、绘制和跟踪一条复杂的不能回头的途径这些义务,最终目的和奖励都会有所不同。
但是,就举动空间和察看空间来说,义务的环境是一样的。可以在每个环境中对智能体停止训练。在 DMLab 的 GitHub 页面上可以找到更多关于训练环境的细节。
IMPALA::重点加权举动-学习器框架
为了在 DMLab-30 中训练那些具有应战性的义务,我们开发了一个名为 IMPALA 的散布式智能体框架,它应用 TensorFlow 中高效的散布式框架来最大聚焦消费升级、多维视频、家庭场景、数字营销、新零售等创新领域,为用户提供更多元、更前沿、更贴心的产品,满足用户日益多样化、个性化的需求。化数据吞吐量。
IMPALA 的灵感来自盛行的 A3C 框架,后者运用多个散布式 actor 来学习智能体的参数。
在这样的模型中,每个 actor 都运用战略参数的克隆在环境中举动。actor 会周期性地暂停探究来共享梯度,这些梯度是用一个地方参数效劳器来计算的,会实时更新(见下图)。
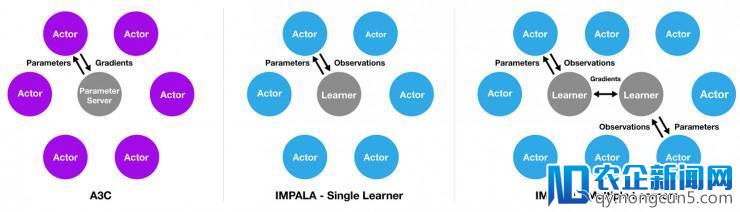
另一方面,在 IMPALA 中,不会用 actor 来计算梯度。它们只是用来搜集经历,这些经历会传递给计算梯度的地方学习器,从而失掉一个拥有独立 actor 和 learner 的模型。
古代计算零碎有诸多优势,IMPALA 可以应用其优势,用单个 learner 或多个 learner 停止同步更新。以这种方式将学习和举动别离,有助于进步整个零碎的吞吐量,由于 actor 不再需求执行诸如Batched A2C 框架中的等候学习步骤。
这使我们在环境中训练 IMPALA 时不会遭到框架渲染工夫的变化或义务重新启动工夫的影响。
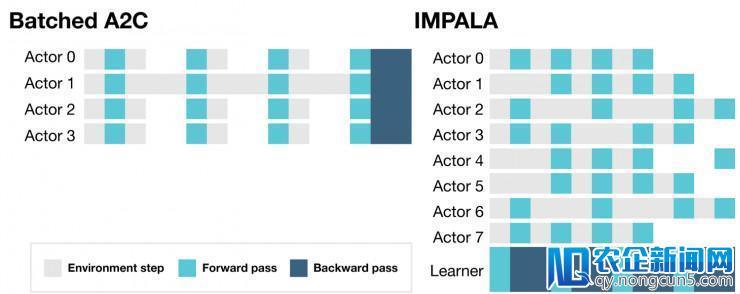
IMPALA 中的学习是延续的,不同于其他框架,每一步学习都要暂停
但是,将举动与学习别离会招致 actor 中的战略落后于 learner。为了补偿这一差别,我们引入 V-trace——条理化的离战略 actor critic 算法,它可以对 actor 落后的轨迹停止补偿。可以在我们的论文 IMPALA: Scalable Distributed Deep-RL with importance Weighted Actor-Learner Architectures 中看到该算法的详细细节。
IMPALA 中的优化模型绝对于相似智能体,能多处置 1 到 2 个数量级的经历,这使得在极具应战的环境中停止学习成为能够。
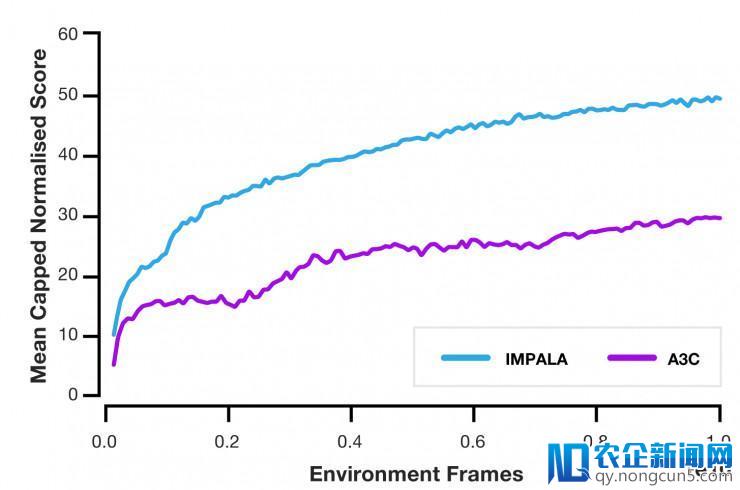
我们将 IMPALA 与几个盛行的 actor-critic 的办法停止了比拟,发现它具有明显的减速效果。此外,运用 IMPALA 的状况下,随着 actor 和 learner 的增长,吞吐量简直是按线性增长的。这标明,散布式智能体模型和 V-trace 算法都能支持极大规模的实验,支持的规模甚至可以到达上千台机器。
当在 DMLab-30 上停止测试时,与 A3C 相比,IMPALA 的数据效率进步了 10 倍,最终得分到达后者的两倍。此外,与单义务训练相比,IMPALA 在多义务环境下的训练呈正迁移趋向。
IMPALA 论文地址: https://arxiv.org/abs/1802.01561
DMLab-30 GitHub地址: https://github.com/deepmind/lab/tree/master/game_scripts/levels/contributed/dmlab30
via: DeepMind Blog
雷锋网 AI 研习社编译整理
雷锋网版权文章,未经受权制止转载。概况见。
