
知识图谱可以把复杂的知识范畴经过语义婚配,数据发掘、信息处置、知识计量和图形绘制显示出来,提醒知识范畴的静态开展规律,为研讨和决策提供实在的、有价值的参考。
因而,当知识图谱使用于信息资产平安要挟的发现与剖析时,可以明显提升发现资产平安要挟的效率和精确率,为企业平安人员的要挟剖析提供决策根据。
本次雷锋网硬创地下课,北京数字观星科技无限公司开创人郭亮分享了如何应用知识图谱,对企业信息资产面临的平安要挟,停止构建、绘制、发掘以及剖析的理论经历。
嘉宾引见
郭亮,北京数字观星科技无限公司开创人,超越20年大型业务信息零碎平安运营管理经历,曾担任过国度发改委多个严重技术专项课题的技术担任人。
演讲提要
以下为雷锋网随着中国经济向消费型模式的转型, 电子商务和移动电子商务的快速发展带来了支付行业强劲的增长。 (大众号:雷锋网) 该演讲提要,要想获取完好内容,请移步视频回放区: http://www.mooc.ai/course/443/learn#lesson/2420。
一、知识图谱的相关概念和构建
1.知识图谱
Google于2012年首先提出了知识图谱(Knowledge Graph)概念,目的在于描绘真实世界中存在的各种实体、概念,以及它们之间的关联关系,大幅改善搜索体验。
实质上, 知识图谱旨在描绘真实世界中存在的各种实体或概念及其关系,其构成一张宏大的语义网络图,节点表示实体或概念,边则由属性或关系构成。
知识是一个外延十分丰厚的概念;知识普遍存在于社会各个范畴。迷信知识图谱狭义上包括:生物的基因图谱、教育教学中的认知地图、探究太空的天体图、描画地形的GIS、模仿人脑的神经网络图、各种金属图谱等。
知识图谱是以迷信知识为对象,显示学科的开展进程与构造关系的一种图形,具有“图”和“谱”的双重性质与特征。
2.知识图谱的3种节点:
实体: 指的是具有可区别性且独立存在的某种事物。如某一团体、某一个城市、某一种植物等、某一种商品等等。世界万物有详细事物组成,此指实体。如图1的“中国”、“美国”、“日本”等。,实体是知识图谱中的最根本元素,不同的实体间存在不同的关系。
语义类(概念):具有同种特性的实体构成的集合,如国度、民族、书籍、电脑等。 概念次要指集合、类别、对象类型、事物的品种,例如人物、天文等。
内容: 通常作为实体和语义类的名字、描绘、解释等,可以由文本、图像、音视频等来表达。
基于上述定义。基于三元组是知识图谱的一种通用表示方式,即,其中,是知识库中的实体集合,共包括|E|种不同实体; 是知识库中的关系集合,共包括|R|种不同关系;代表知识库中的三元组集合。三元组的根本方式次要包括(实体1-关系-实体2)和(实体-属性-属性值)等。
每个实体(概念的内涵)可用一个全局独一确定的ID来标识,每个属性-属性值对(attribute-value pair,AVP)可用来描写实体的内在特性,而关系可用来衔接两个实体,描写它们之间的关联。如下图1的知识图谱例子所示,中国是一个实体,北京是一个实体,中国-首都-北京 是一个(实体-关系-实体)的三元组样例北京是一个实体 ,人口是一种属性2069.3万是属性值。北京-人口-2069.3万构成一个(实体-属性-属性值)的三元组样例。
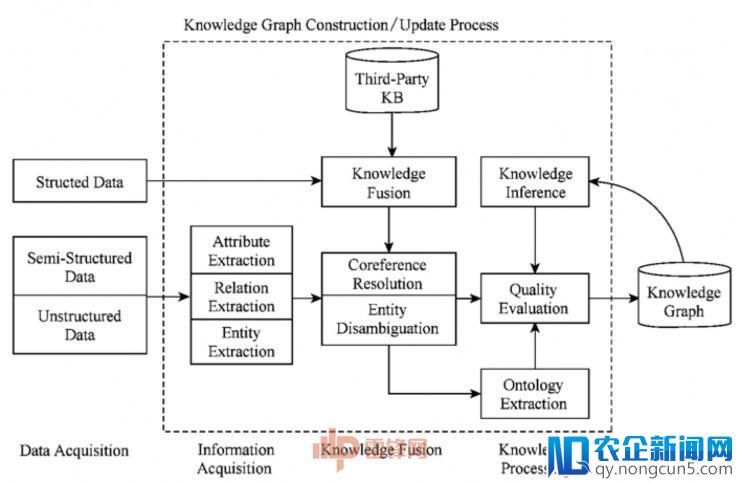
3.知识图谱的构建
包括3个步骤:
信息抽取,即从各品种型的数据源中提取出实体(概念)、属性以及实体捡的互相关系,在此根底上构成本体化的知识表达
知识交融,在取得新知识后,需求对其停止整合,以消弭矛盾和歧义,比方某些实体能够有多种表达,某个特定称谓也许对应于多个不同的实体等
知识加工,关于经过交融的新知识,需求经过质量评价之后(局部需求人工参与鉴别),才干将合格的局部参加到知识库中,以确保知识库的质量,新增数据之后,可以停止知识推理、拓展示有知识、失掉新知识。
4.知识样本数据的获取
传统静态知识
次要数据来源:Web of Science
迷信文献数据:(SCI) (SSCI)
专利文献数据:德温特创新索引DII
国际会议文献数据:(CPCI)
国际数据库:CNKI、CSSCI、CSCD、万方等
网络数据源:Google Scholar、arXiv、CiteSeerX
静态知识
次要数据来源:事情数据
另外还有Scopus,Science Direct
设备可读取以及可输入的异常数据
4.样本数据的梳理
基于数据停止知识可视化的质量、合感性和牢靠性很大水平上依赖于所用数据的准确性和片面性,不精确或不片面的数据往往形成不准确甚至错误的后果。即便目前最威望、公认质量最高的WoS,也存在数据著录格式(如人名和地名的不一致)和脱漏的成绩。
5.数据规范化
为便于可视化,对复杂地频次计算的单元数据,规范化经常经过数据间的类似度测量。次要有两大类:一是集合论办法(Set-theoretic measures),包括Cosine、Pearson、Spearman、Inclusion 指数和Jaccard指数;二是概率论办法(Probabilistic measure),次要有合力指数(Association Strength)和概率亲和力指数(Probabilistic Affinity)
6.数据剖析-简化剖析
因子剖析以较少几个因子描绘许多目标或要素间关系,即把较亲密的变量归在同一类,每类变量成为一个因子,以大批的因子反映原材料中大局部信息。
7.在知识图谱的解读进程中,经常需求对图谱停止相应操作,包括阅读、缩小、减少、过滤、查寻、关联和按需挪动等。次要从以下几方面着手:网络剖析、历时剖析、空间剖析、渐变检测
二、资产和要挟
资产数字化是趋向,每个资产都有其特征;要挟是数字的表征,要挟数据有其特征
三、关联和剖析
分三步:
第一步,先把企业展开任务需求哪些关键知识辨认出来,找到源头,不论是企业外部的还是内部的,不论是数据库、文档库还是网页,都会聚起来;
第二步,是经过知识图谱,让零碎能“看法了解”这些数字和文字代表的含义,把各个源头的知识抽取出来,把知识和人都关联起来,构成一张知识网;
第三步,让知识围绕业务转起来,完成智能化使用,包括语义搜索、特性化引荐、智能问答、协同研讨、决策支持等等
要想获取雷锋网该地下课演讲的完好内容,请移步视频回放区:http://www.mooc.ai/course/443/learn#lesson/2420。
。
