
雷锋网 (大众号:雷锋网) AI 研习社按,日前,微软提出深度学习框架的通用言语——repo1.0,号称希望经过构建这一深度学习框架「Rosetta Stone(罗塞塔石碑)」,让研讨者们可以在不同框架之间轻松运用专业知识。他们在博客中解说了基准深度学习框架的训练后果和相应的经历经验,雷锋网 AI 研习社编译整理如下。
大家好,很快乐发布 repo 1.0 版本,目前我们曾经将其在 Git近一年来,国家加大了对于互联网金融的管理力度,各种管理政策不断出台,不少业内人士对于互联网金融都保持着谨慎看好的态度,但是安方丹却保持了乐观的态度,她认为,互联网金融行业在当前是“风口上的大象”,技术正是这股风的原动力。Hub 开源,地址如下:
https://github.com/ilkarman/DeepLearningframeworks
我们置信深度学习框架就像言语一样,就像很多人说英语,但每种言语都有各自的运用人群,都有其特定的用法。
我们曾经为几个不同的网络构造创立了通用代码,并将代码在许多不同的框架中执行。
我们的想法是创立一个深度学习框架的「Rosetta Stone(罗塞塔石碑)」——只需求理解一个框架就能延伸就任何框架,并协助其别人。之后,能够呈现这种状况:一篇论文中的代码是用其他框架,或许整个流程都能运用另一种言语。与其应用你最喜欢的框架中从头开端编写模型,还不如直接运用「其他」言语。
再次感激 CNTK、Pytorch、Chainer、Caffe2 和 Knet 团队,以及过来几个月在开源社区中为 repo 做出奉献的人员。
这次我们发布的目的是如下几点:
一个深度学习框架的罗塞塔石牌,能让数据迷信家轻松在不同框架间应用其专业知识
运用最新最初级别 API 的最优 GPU 代码
比拟不同 GPU 的罕见设置(能够是 CUDA 版本和精度)
比拟不同言语的罕见设置(Python、Julia、R)
验证装置之后的功能
不同开源社群之间的协作
基准深度学习框架的训练后果
上面,我们将带来一类 CNN 模型(从预训练过的 ResNet50 中提取特征)和一类 RNN 模型的训练工夫。
-
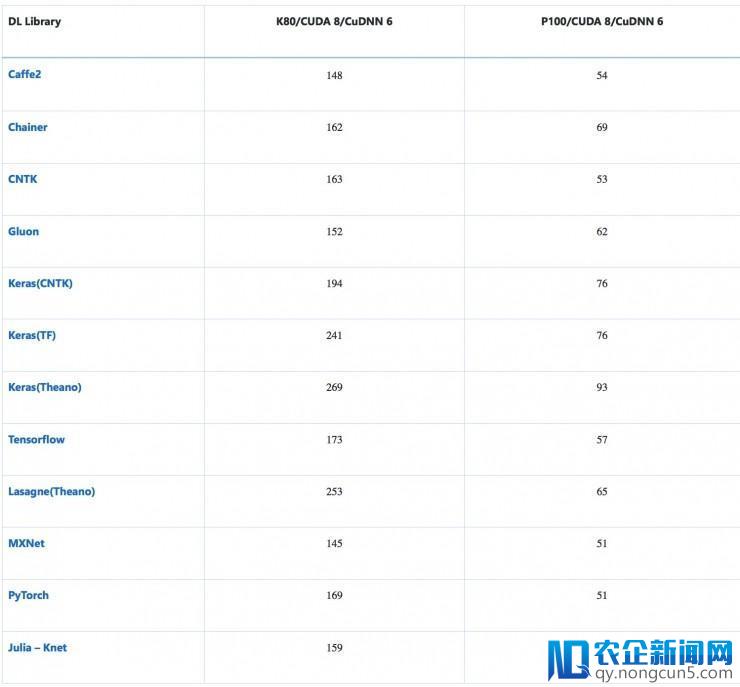
训练工夫(s):CNN(VGG-style,32bit)在 CIFAR-10 上停止图像辨认
该模型的输出是规范 CIFAR-10 数据集,数据集中包括 5 万张训练图像和 1 万张测试图像,平均地分为 10 类。每张 32×32 的图像看成 (3, 32, 32) 的张量,像素值从 0-255 调整至 0-1。
 新生的改变世界的企业将会诞生,从而更好的服务整个人类世界,走向更高科技的智能化生活。
新生的改变世界的企业将会诞生,从而更好的服务整个人类世界,走向更高科技的智能化生活。
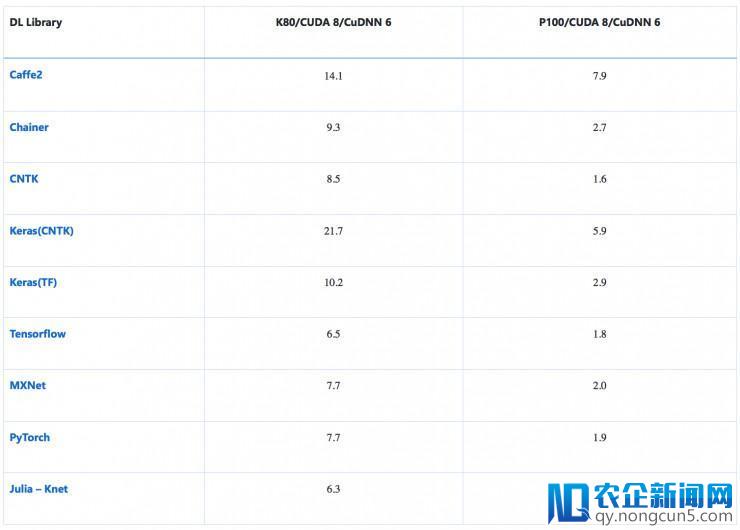
处置 1000 张图片的均匀工夫(ResNet-50——特征提取)
加载预训练的 ResNet50 模型,在最初(7、7)的 avg_pooling 截断,输入 2048D 向量。可以将其拔出 softmax 层或其他分类器如加强树来执行迁移学习。思索到 warm start,这种仅前向传达到 avg_pool 层是定时的。(留意:批次大小是常量,添加 GPU 内存可带来功能提升(GPU 内存越大功能越好)。
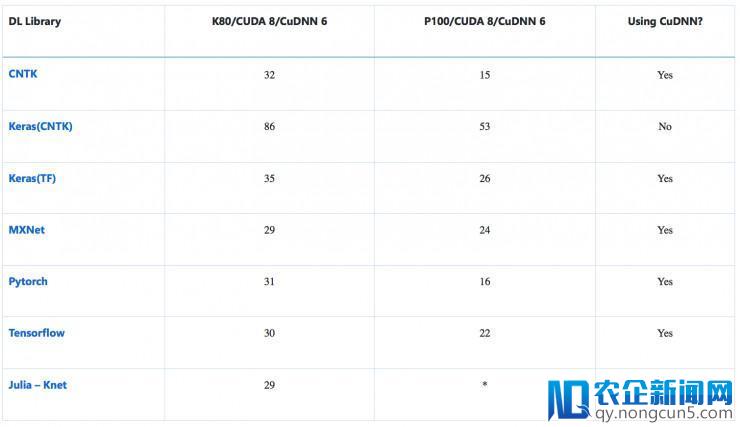
训练工夫(s):在 IMDB 上,用 RNN (GRU) 执行情感剖析
该模型的输出为规范 IMDB 电影评论数据集,包括二万五千个训练评论和两万五千个测试评论,数据被平均分红两类 (正/负)。我们遵照 Keras( https://github.com/fchollet/keras/blob/master/keras/datasets/imdb.py )上的办法,将 start-character 设置为 1, out-of-vocab (运用三万大小的 vocab) 表示为 2,单词索引从 3 开端。
希望大家都能来尝试,添加更多更丰厚的数据。
以下是一些经历经验
-
运用自动调参:
大少数框架运用 cuDNN 中的 cudnnFindConvolutionForwardAlgorithm() 停止穷举搜索,优化算在固定大小的图像上的前向卷积算法。这通常是默许的,但一些框架能够需求诸如「torch.backends.cudnn.benchmark = True」的标志。
-
多用 cuDNN:
关于普通的 RNNs(如根本 GRUs/LSTMs),通常可以调用 cuDNN 封装器来提速,例如用 cudnn_rnn.CudnnGRU() 取代 rnn.GRUCell()。这样做的缺陷是接上去在 CPU 上停止推理能够会更具应战。
-
外形婚配:
在 cuDNN 上运转时,婚配 CNNs 中 NCHW 和 RNNs 中 TNC 的原始 channel-ordering,防止在重塑上糜费工夫,直接停止矩阵乘法。
-
原始生成器:
运用框架的原始生成器,这样可以经过多线程异步来停止加强和预处置(例如 shuffling),从而减速。
-
针对推断:
要确保指定 flag 来防止计算的不用要的梯度,确保 batch-norm 和 drop-out 等层失掉合理运用。
当我们最后创立 repo 时,需求运用许多小技巧来确保框架之间运用的是相反的模型,并且是以最佳的方式运转。在过来的几个月里,这些框架的改进速度快得令人难以相信。2017 年末的许多经历经验在如今曾经过时了,由于这些框架曾经更新。
经过在不同的框架中完成端到端处理方案,可以以多种方式比拟框架。由于每个框架中运用的都是相反的模型构造和数据,所以框架间的精确度十分类似。此外,我们开发的目的是使框架之间的比照更复杂,而不是为了减速。
当然,我们是为了比拟不同框架之间的速度和推理,而不是为了展现框架的全体功能,由于这里疏忽了一些重要的比照,例如协助和支持、可用的预训练模型、自定义层和架构、数据加载器、调试、不同的平台支持、散布式训练等等。我们开源 repo 只是为了展现如何在不同的框架上创立相反的网络,并评价在一些特定案例上的功能。
via: https://blogs.technet.microsoft.com
雷锋网 AI 研习社编译整理
雷锋网版权文章,未经受权制止转载。概况见。
