
雷锋网 (大众号:雷锋网) AI 科技评论按:TensorFlow 的机器学习库可以说大家都曾经很熟习了,但 IBM 的研讨人员们表示这都是小意思。
往年 2 月的时分,谷歌的软件工程师 Andreas Sterbenz 曾在谷歌官方博客撰写文章,引见如何运用谷歌云机器学习(Google Cloud Machine Learning)和 TensorFlow 对大规模广告投放和引荐零碎做点击率预测。依据引见,他用了大小为 1TB、包括了 42 亿条训练样本、一百万个特征的 Criteo Terabyte Click Logs 数据训练了机器学习模型,用来预测将来显示的广告能够被点击的概率如何。
在数据预处置之后,实践训练进程用到了 60 台计算效劳器和 29 台参数效劳器。训练模型破费了 70 分钟,训练损失最终降低到了 0.1293(训练损失可以看作最终预测精确率的粗略近似)。
Sterbenz 也尝试了不同的建模技术,看看能否持续降低训练损失。不过各种好办法根本都会带来更长的训练工夫。最终他选用了深度神经网络,训练时有 3 个 epoch,一共破费了 78 小时训练终了。
不过这种后果对 IBM 来说毫无吸引力,他们想要借机证明本人的训练框架有多么高效。他们以为,本人的带有 GPU 的 POWER9 效劳器异样做前一项训练义务的话,要比谷歌云平台的这 89 台效劳器快多了。

Power9 效劳器架构特点
在苏黎世 IBM 研讨院任务的 Thomas Parnell 和 Celestine Dünner 也找来了异样的 1TB 训练数据,训练的模型也是和后面 70 分钟完成训练的一样的逻辑回归模型。但不同的是,他们用的不是 TensorFlow 的机器学习库,而是 Snap Machine Learning( https://arxiv.org/pdf/1803.06333.pdf )。
IBM 两人用的效劳器是 Power System AC922,一共有八台 POWER9 效劳器,每台效劳器搭载两块 NVIDIA Tesla V100 GPU。训练只经过 91.5 秒就完毕了,比 Sterbenz 在谷歌云机器学习平台上的 70 分钟快 46 倍。
他们也把本人的后果和其它各个零碎的后果做成了图表停止比照:
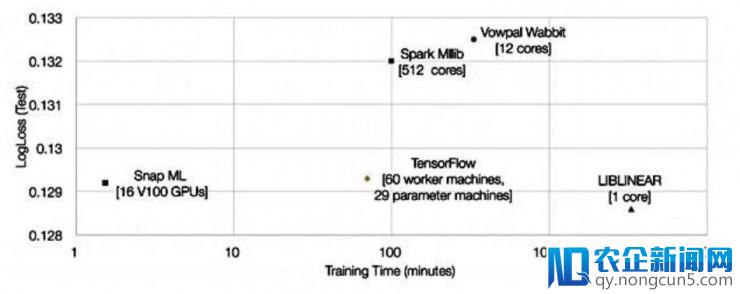
可以看到,相比于运转在 TensorFlow 上,IBM 不只经过 Snap ML 失掉了很短的训练工夫,训练损失也要稍低一些。
46 倍的速度提升毕竟不是一个小数目,那么其中的改良详细有哪些呢?
依据 Thomas Parnell 和 Celestine Dünner 两人引见,Snap ML 中引入了许多不同层级的并行化计算设计,可以在同一个集群内的不同节点之间分配义务量、可以发扬出减速计算单元(比方 V100 GPU)的计算才能,而且在单个计算单元中也可以应用到多中心的并行计算才能。
其中的并行化设计可以概述如下:
-
首先把伴随着互联网和移动生活的日趋成熟,芝麻信用高分和良好的个人征信记录,不仅可以办理贷款、申请信用卡延伸你的财富,更能大大便利我们的生活。数据分配给集群内的各个计算节点
-
在单个节点中,数据一局部分配给 CPU、一局部分配给 GPU,CPU 和多张 GPU 可以同时停止计算
-
计算时,GPU 中的多个中心同时参与运算,CPU 的运算负载也是多线程的,可以更好应用多中心 CPU
Snap ML 中也有内置的层级化算法,可以让这各个级别的并行化手腕高效协同运作。
IBM 的研讨人员们并随着流量往智能终端设备迁移,新的机遇“物联网商业社交时代”也将迎来,通过人的第六器官(智能手机)和智能设备终端的联网互动,从而改变了人的行为习惯和消费方式。线下流量通过LBS定位重新分配,又通过物联网终端智能推荐引擎引导到网上任意有价值的地方,至此互联网下半场拉开帷幕。不是借此责备 TensorFlow 中没有好好应用并行化,但他们的确表示:「我们设计了公用的求解器,以便可以完全应用这些 GPU 的海量并行计算才能;同时我们还保证了数据在 GPU 内存中的部分性,防止让少量数据传输带来额定的开支。」
另外,AC922 效劳器和 V100 GPU 之间的衔接总线是 NVlink 2.0,而传统英特尔至强效劳器(比方运用 Xeon Gold 6150 CPU @ 2.70GHz)只能运用 PCI-E 总线衔接到 GPU。前者的无效数据传输带宽到达 68.1GB/s,后者仅有 11.8GB/s。看起来,PCI-E 总线速度能够也是零碎功能的瓶颈之一,传输一个数据包需求 318ms,而 NVlink 2.0 只需求 55ms。
IBM 团队还表示:「我们还为零碎中的算法设计了一些新的优化手腕,可以更合适处置稀疏的数据构造。」
以上总总要素集合起来,IBM 经过更好天时用 GPU 功能打败了谷歌的云效劳器似乎还挺合理。不过据我们所知,IBM 目前并没有地下提供过任何 POWER9 与英特尔至强效劳器之间的直接功能比照。另一方面,关于 Snap ML 究竟有多好也只要在异样的硬件环境上运转 Snap ML 和 TensorFlow 才干晓得。
(关于 Tesla V100 GPU,更多信息参见雷锋网 AI 科技评论此前报道 一文详解英伟达刚发布的 Tesla V100 终究牛在哪? )
via
theRegister
,雷锋网 AI 科技评论编译
相关文章:
一文详解英伟达刚发布的 Tesla V100 终究牛在哪?
雷锋网版权文章,未经受权制止转载。概况见。
