
雷锋网 AI 研习社按,YOLO 是一种十分盛行的目的检测算法,速度快且构造复杂。日前,YOLO 作者推出 YOLOv3 版,在 Titan X 上训练时,在 mAP 相当的状况下,v3 的速度比 RetinaNet 快 3.8 倍。在 YOLOv3 官网上,作者展现了一些比照和案例。在论文中,他们对 v3 的技术细节停止了详细阐明。雷锋网 AI 研习社将内容编译整理如下。
我们针对 YOLO 做了一些更新,在设计上停止了一些小改动,让它变得更好。当然,我们也训练了这个新网络,它的功能十分优秀。它比前一版本要大一点,但更精确。当然了,不用担忧会牺牲速度,它依然很快。YOLOv3 可以在 22ms 之内执行完一张 320 × 320 的图片,mAP 得分是 28.2,和 SSD 的精确率相当,但是比它快三倍。
此外,它在 Titan X 上经过 51 ms 训练,mAP50 为 57.9,相比之下,RetinaNet 经过 198ms 的训练之后 mAP50 为 57.5。比照起来,两者的功能差别不大,但是 YOLOv3 比 RetinaNet 快 3.8 倍。
一切的代码都在 https://pjreddie.com/yolo/ 上。
与其他检测器绝对比
YOLOv3 十分疾速和精确,在 IoU=0.5 的状况下,与 Focal Loss 的 mAP 值相当,但快了 4 倍。此外,大家可以轻松在速度和精确度之间停止权衡,只需改动模型的大小,而不需求重新训练。
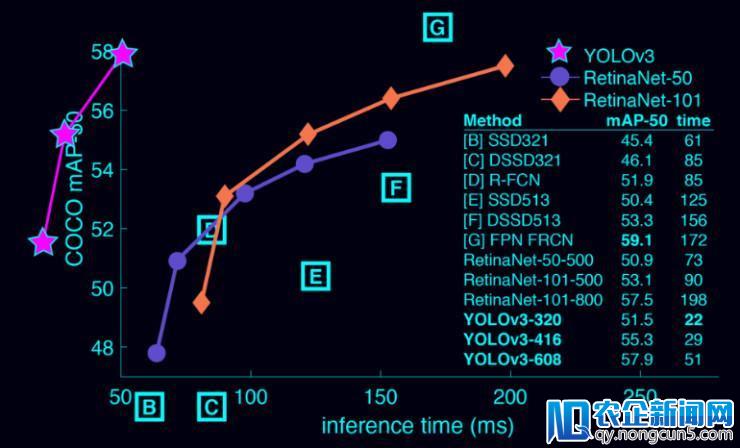
在 COCO 数据集上的表现
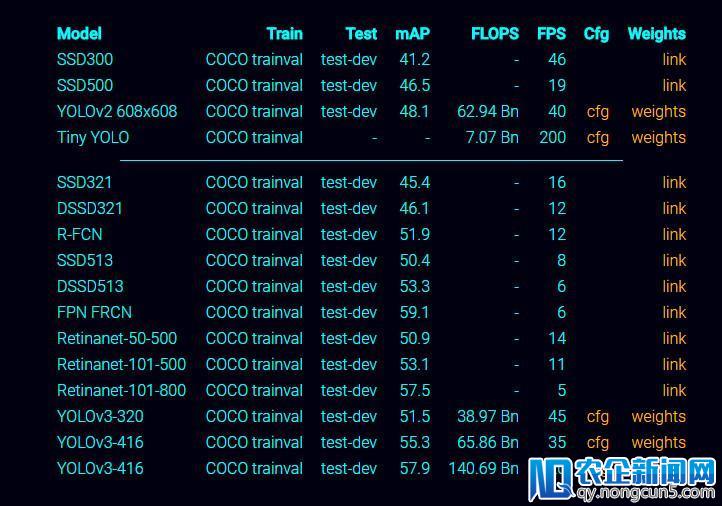
任务原理
先前的检测零碎是让分类器或定位器来执行检测义务。他们将模型使用于图片中,图片里物体的地位和尺寸各异,图像的高得分区域被以为是检测区域。
我们采用了完全不同的办法——将一个复杂的神经网络使用于整张图像。该网络将图像联系成一块块区域,并预测每个区域的 bounding box 和概率,此外,预测概率还对这些 bounding box 停止加权。

我们的模型相较基于分类的检测零碎有如下优势:它在测试时察看整张图像,预测会由图像中的全局上下文(global context)引导。它还经过单一网络评价做出预测,而不像 R-CNN 这种零碎,一张图就需求不计其数次预测。比照起来,YOLO 的速度十分快,比 R-CNN 快 1000 倍,比 Fast R-CNN 快 100 倍。
可以参阅我们的 论文 ,理解关于完好零碎的更多细节。
在 v3 中,有哪些全新的办法呢?
YOLOv3 用了一些小技巧来改良训练、进步功能,包括多尺度预测,更好的主干分类器等等。
异样,详细信息我们也全写在 论文 上了。
用预训练模型停止检测
接上去是应用 YOLO 运用预训练模型来检测物体。请先确认曾经装置 Darknet。接上去运转如下语句:
git clone https://github.com/pjreddie/darknet
cd darknet
make
这样一来 cfg/子目录中就有了 YOLO 配置文件,接上去下载预训练的 weight 文件(237 MB)( https://pjreddie.com/media/files/yolov3.weights ),或许运转如下语句:
wget https://pjreddie.com/media/files/yolov3.weights
然后执行检测器:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
输入如下:
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 20呼吁行业者在政府部门出台相关政策标准的之前,从业者一定要规范自己的行为准则健康有序的快速发展。8 x 208 x 64 1.595 BFLOPs
.......
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
truth_thresh: Using default '1.000000'
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.029329 seconds.
dog: 99%
truck: 93%
bicycle: 99%
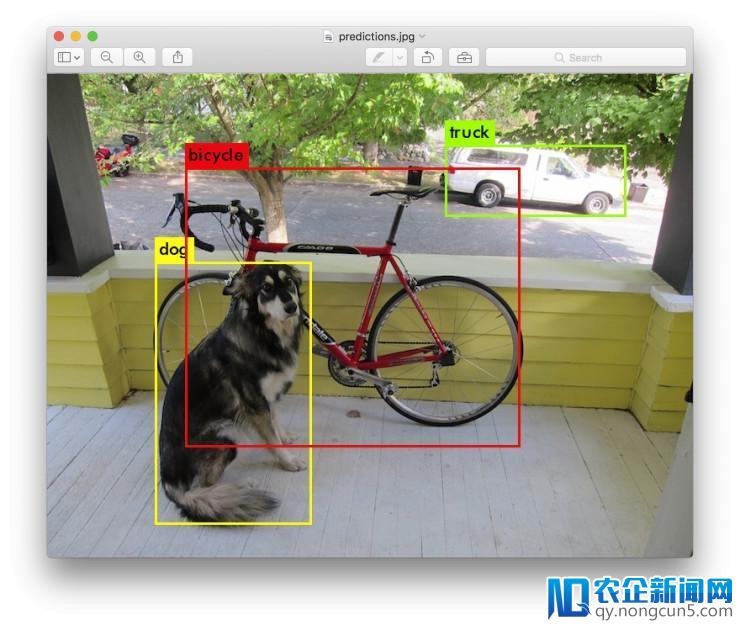
Darknet 会输入检测到的物体、confidence 以及检测工夫。我们没有用 OpenCV 编译 Darknet,所以它不能直接显示检测状况。检测状况保管在 predictions.png 中。大家可以翻开这个图片来检查检测到的对象。我们是在 CPU 上运用 Darknet,检测每张图片大约需求 6-12 秒,假如运用 GPU 将快得多。
我还附上了一些例子给大家提供灵感,你们可以试试 data/eagle.jpg,data/dog.jpg,data/person.jpg 或 data/horses.jpg。
detect 指令是对 command 的惯例版本的简写:
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
假如你只是想检测图像,并不需求理解这个,但假如你想做其他的事情,比方在网络摄像头上运转 YOLO,这将十分有用(稍后详细描绘)。
多个图像
在 command 行不写图像信息的话就可以延续运转多个图片。当加载完配置和权重,你将看到如下提示:
./darknet detect cfg/yolov3.cfg yolov3.weights
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
Loading weights from yolov3.weights...Done!
Enter Image Path:
输出相似 data/horses.jpg 的图像途径来停止边框预测。
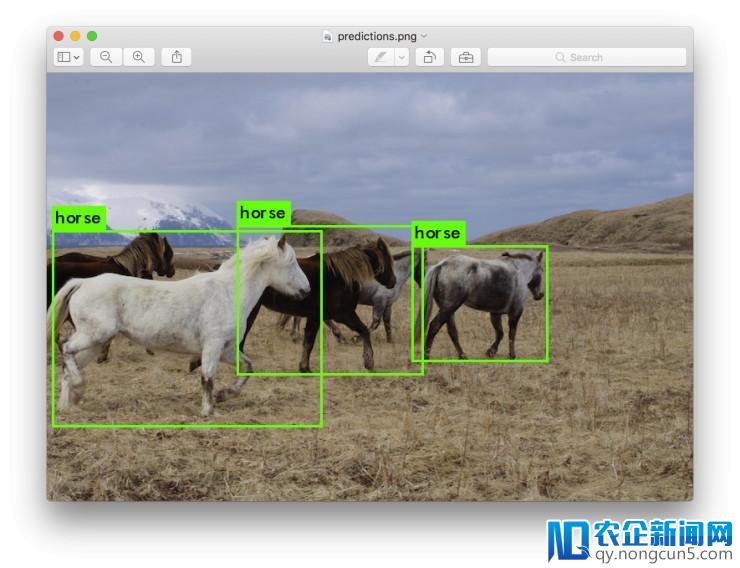
一旦完成,它将提示你输出更多途径来检测不同的图像。运用 Ctrl-C 加入顺序。
改动检测门限
默许状况下,YOLO 只显示检测到的 confidence 不小于 0.25 的物体。可以在 YOLO 命令中参加-thresh <val>来更改检测门限。例如,将门限设置为 0 可以显示一切的检测后果:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
网络摄像头实时检测
假如在测试数据上运转 YOLO 却看不到后果,那将很无聊。与其在一堆图片上运转 YOLO,不如选择摄像头输出。
要运转如下 demo,需求用 CUDA 和 OpenCV 来编译 Darknet。接上去运转如下指令:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
YOLO 将会显示以后的 FPS 和预测的分类,以及伴有边框的图像。
你需求一个衔接到电脑的摄像头并可以让 OpenCV 衔接,否则就无法任务。假如有衔接多个摄像头并想选择其中某一个,可以运用 -c <num>(OpenCV 在默许状况下运用摄像头 0)语句。假如 OpenCV 可以读取视频,也可以在视频文件中运转:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
在 VOC 数据集上训练 YOLO
首先需求 2007-2012 年的一切 VOC 数据,这是下载地址: https://pjreddie.com/projects/pascal-voc-dataset-mirror/ ,为了存储数据,执行如下语句:
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
接上去一切 VOC 训练数据都在 VOCdevkit/ 子目录下。
生成标签
接上去需求生成 Darknet 运用的标签文件。Darknet 需求的.txt 文件格式如下:
<object-class> <x> <y> <width> <height>
x, y, width 和 height 对应图像的宽和高。需求在 Darknet scripts/子目录下运转 voc_label.py 脚原本生成这些文件。
wget https://pjreddie.com/media/files/voc_label.py
python voc_label.py
几分钟后,这个脚本将生成一切必需文件。大局部标签文件是在 VOCdevkit/VOC2007/labels/ 和 VOCdevkit/VOC2012/labels/ 下,大家可以在目录下看到如下信息:
ls
2007_test.txt VOCdevkit
2007_train.txt voc_label.py
2007_val.txt VOCtest_06-Nov-2007.tar
2012_train.txt VOCtrainval_06-Nov-2007.tar
2012_val.txt VOCtrainval_11-May-2012.tar
相似 2007_train.txt 的语句列出了图像文件的年份和图像集。Darknet 需求一个包括一切你想要训练的图片的文本文件。在这个例子中,我们训练除了 2007 测试集的一切数据。运转如下语句:
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
修正
如今去 Darknet 目录,需求改动 cfg/voc.data 配置文件以指向数据:
1 classes= 20
2 train = <path-to-voc>/train.txt
3 valid = <path-to-voc>2007_test.txt
4 names = data/voc.names
5 backup = backup
将<path-to-voc>交换为你寄存 VOC 数据的目录。
下载预训练卷积权重
在训练中运用在 Imagenet 上预训练的卷积权重。我们这里运用 darknet53 模型的权重,可以点击这里 https://pjreddie.com/media/files/darknet53.conv.74 下载卷积层权重:
wget https://pjreddie.com/media/files/darknet53.conv.74
训练模型
接上去执行如下语句停止训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
在 COCO 上的训练与 VOC 上相似,大家可以在 这里 检查概况。
YOLOv3 论文地址如下:
https://pjreddie.com/media/files/papers/YOLOv3.pdf
雷锋网 (大众号:雷锋网) AI 研习社编译整理。
雷锋网版权文章,未经受权制止转载。概况见。
