
雷锋网第一次接触 DataVisor 是在一次三家企业结合对立黑产的协作发布会上。
事先,挪动互联网公司 APUS 、主打“可信ID”的平安效劳商数字联盟以及 DataVisor 成立了一个“三家公司的联盟”,希冀以分享黑产数据的方式来打击共同的朋友,概况可见雷锋网此前发布的的报道 《搞垮黑产?三家企业想联手试试》 。DataVisor 是一家反欺诈检测效劳提供商,他们为联盟提供的是无监视反欺诈算法。
最近,他们又打包发布了一款号称是本人无监视反欺诈算法“mini”版的新产品 UML Essentials。这家 2013 年在美国硅谷成立、开创人中有两位专家来自微软硅谷研讨院的公司及其算法有什么共同之处?他们对新产品有何部署?
雷锋网 (大众号:雷锋网) 和 DataVisor 中国区总经理吴中聊了聊。
究竟是哪些坏人在坏我的坏事
作为雷锋网网络平安频道的读者,想必你对黑产早已不生疏。
某银行推出了一款金融 App,推行期争取了一笔巨额费用,以为撒钱能吸引客户下载、注册。万万没想到,90% 的费用全被羊毛党薅走了。这种案例很罕见,就算是知名的电商公司,也常常遇到“魔高一丈”,大额优惠券统统被欺诈团队刷走转卖的状况。
有意思的是,如今“抱团围攻”的景象比拟分明。黑产欺诈人员会先经过虚伪注册、身份盗用等方式获取大批账号的运用权,然后应用群控软件或许网络众包的方式停止团伙欺诈,他们常用猫池、手机墙、模仿器、刷机等手腕和工具规避传统黑名单和基于设备规则的检测。
他们还是分工合理、流水作业的“高度勾结”形态——专门注册、养号、囤号,埋伏并积累正常的用户行为,待机遇成熟再发起攻击。大规模注册、账号盗取、渣滓内容、虚伪评论、薅羊毛、使用装置欺诈等玩得不要更666。
于是,被盯上的银行、厂商就想搞清楚一个成绩: 究竟是哪些坏人在坏我的坏事?
为了答复这个成绩,不少厂商提出了本人的反欺诈方案。
第一代规则零碎,需求对欺诈行为有深化理解。
第二代设备指纹黑名单,能够被虚拟机等逃避检测。
第三代有标签的机器学习零碎,需求少量人工标注数据训练检测模型。
“传统的欺诈检测办法,如规则引擎、设备指纹、有监视机器学习、半监视机器学习,都有一个共同的局限性,需求在攻击发作后,依据已知攻击形式和样本,检测将来的攻击。”吴中提出,这就是他们提出无监视学习零碎的初衷之一——在没有标签的状况下,提早阻止未知欺诈。
黑产的“套路”VS 算法的“套路”
DataVisor 用这种算法停止反欺诈的根据是,
任何欺诈团伙在展开欺诈时都有“套路”。
这个套路能够会不停地变化,但是它想不断搞下去的话,总会有一些套路去控制一堆这样的套路,去做相似的事情。所以经过这一点,DataVisor 尝试在没有标签的状况下,很快地抓到新型攻击。
DataVisor 称,它的无监视学习算法有三个优势:
自动发生规则,免除费时的人工规则调试。
自动发生标签,用于机器训练检测模型。
无效自动发掘和检测各种已知、未知的欺诈行为。
我们来看看,它是如何做到的。
假如我们盯着一个点看,会发现这个点就是那么平平无奇,没有特点,假如视野拉远一些,这个点和四周的点衔接起来,能够能构成一些规律,你会发现,这些点能够组成了一张世界地图,或许一张有规则的图像。

当然,理想的黑产行为中,能够没有这么有“艺术感”和“规则感”的后果。
更多的后果是,我们能够看到的是这样的行为形式:
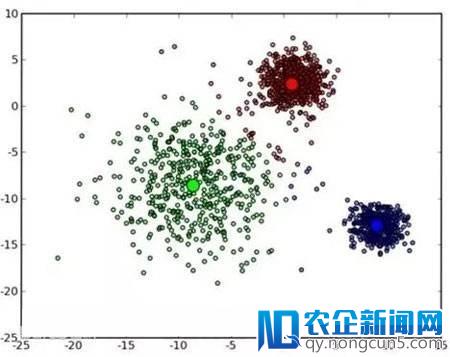
吴中和他的同事们会把一切的用户放在在互联网思维的影响下,传统服务业不再局限于规模效益,加强对市场的反应速度成为传统服务业发展的首要选择。在互联网思维下,通过对传统服务业的改革,为传统服务业发展创造了全新的天地。一个图上全局地剖析,研讨其中的关联性,一切的点能够被衔接起来,这就是一个聚类的进程。
接上去,他们需求剖析的是,那些点和聚类是代表好的行为,哪些则是有异常的,自动构成标签。
“一个立功团伙控制一堆帐号去做的话,它的行为与正常用户的行为不一样,没有一个个独立的例子,都是依照某一个套路做,这种套路能够经过机器脚本、动包、群控等攻略的方式完成,我们再看每个帐号的行为,就会发现它们会有很高的不正常的类似与详细性,经过这种判别和数据统计,就可以把好坏推敲出来。”吴中说。
这种判别不需求人工干涉,机器判别派上了用场。它的准绳是,机器会不断跟进这种行为和数据的变化,判别其是不是不断是正常的。
这些点又是怎样来的?
DataVisor 会提取静态用户脱敏后的数据特征。一是用户的行为特征,比方用户做一些事情的顺序、频率、工夫点。二是设备相关,比方用户在做一些事情时,与其相关的 IP地址,设备模型的绝对散布。三是用户的静态画面背景,比方昵称等地下的信息。
这些自动生成的标签精确度和精密度又能到达哪种水平?
这和不同客户的需求及随后的措施相关。比方,一些社交网站的注册要求依据这个后果停止帐号的封停,那么精确率就要求到达 99%以上。假如只是根据一个或许几个标签来停止风险提示,那么精确率能够只需到达95%,以求到达更大的用户掩盖率。
吴中泄漏,这些数据少数来源于客户本人平台的数据,但这是一个可选的选项,假如还需求提升判别模型的效果,可以借助其他的数据。 “这些人想要停止大规模攻击,就会有一些隐形的套路,我们的算法会自动发现这样的状况,不需求事前晓得究竟是哪一种套路。”他说。
但是,道高一尺,魔高一丈。假如吴中等人可以依据记载数据的变化,完成“跟随式”发现, 黑产难道不能实时抹掉本人的踪迹?
现实上,如今也有很多刷机配备可以做到一秒“清零”,但有些设备只能抹掉两头一局部痕迹,黑产很难从每一个维度、渠道停止有利于本人的操作,假如真的能做到,这样会极大添加对方的本钱,高到它做这个生意曾经没有什么钱赚。
因而,这又回到了对立的实质——没有什么最终的成功,平安对立永远只能最大限制地进步对方的本钱,让对方要么保持,要么寻觅其他降低本钱的方式。
不过, 这种“晚期预警”究竟能提早多久?
吴中解释:“应用传统方式感知这个东西,普通得在这个平台上开展到一定水平,再搜集一些样本训练,上线要测试,普通要一两个月才干上线,假如可以自动发现这个成绩,在社交和电商互联网场景中,能够只需几十个帐号数就可以发现规律,金融场景下,这种数量更少,普通只需求 10 个以下,由于在这个场景里,每做成一单收益会比拟大。以一个客户买卖平台的效劳为例,我们可以把发现欺诈的工夫提早 48 小时。”
“mini”版算法看中的是哪块市场
本月 27 日, DataVisor 发布了 DataVisor UML Essentials。
吴中通知雷锋网,他们此次推出mini版产品的目的,实践是为了把本人在平安范畴外面几个承诺的场景,比方大规模注册、用户获取,以及反洗钱范畴的积聚转化成一个SaaS 效劳,降低企业在运用反欺诈效劳的门槛。
第一个特点是,DataVisor 会在产品的初期聚焦于大规模注册场景,注册简直是一切互联网效劳的一个入口,他们会把这个场景做深、做细。在产品开展中前期再引入更多的场景,让中小企业依据本人业务的开展选取更多的效劳。
我们来划下重点,针对的是中小企业。
第二个特点,让用户自主效劳,由于这是一个 SaaS 效劳,昝潇希望,在运用欺诈效劳的流程中,用户本人参与、把控,增加用户切入的工夫。雷锋网以为,从厂商角度看,这也意味着降低提供商的效劳本钱。
第三个特点, UML Essentials 是开放性的,模型会自动调优,降低人工效劳消耗的工夫。
第四个特点,支撑DataVisor UML Essentials的数据处置平台构建于主流云计算根底设备之上,支持AWS、阿里云等平台的架构。
“ 中国很多中小企业正在开展,它们自身的技术才能还没有那么成熟,也想用这些比拟好的 AI 或许是技术,但是价钱上又不能太高,假如要接入相关产品,本人的团队又没有才能同时做很多事情,也很难承受很长周期依据每个业务细粒度地做临时的接入和调优,所以我们降低了使用门槛。 ”吴中道出了这项产品的主打受众以及最后的目的。
。
